大语言模型(Large Language Model,LLM)的能力提升到一定阶段后,AI Agent(人工智能智能体)的瓶颈会从“模型够不够聪明”转移到“系统能不能把模型用好”。
单次问答里,提示词写得好就能明显改善输出;任务变复杂后,模型需要足够准确的上下文;再往后,Agent 不只是回答问题,而是要读文件、查日志、调用工具、修改代码、执行测试、处理异常、回滚错误。这个时候,决定结果上限的已经不是提示词本身,而是模型外面那套完整的运行环境。
这套系统就是 Harness。
“Harness”本意是马具。模型像一匹力量很强但不稳定的马,Harness 则负责给它方向、边界、工具和反馈,让它能在真实任务里可靠行动。一个实用的定义是:
Agent = LLM + Harness
LLM 决定 Agent 拥有什么基础认知能力;Harness 决定 Agent 能看到什么信息、能使用什么工具、按照什么流程执行、遇到失败时如何恢复、完成任务后如何验证。
AI 工程重心为什么从 Prompt 转向 Harness
AI 工程方法大致经历了三层重心迁移:Prompt Engineering、Context Engineering、Harness Engineering。
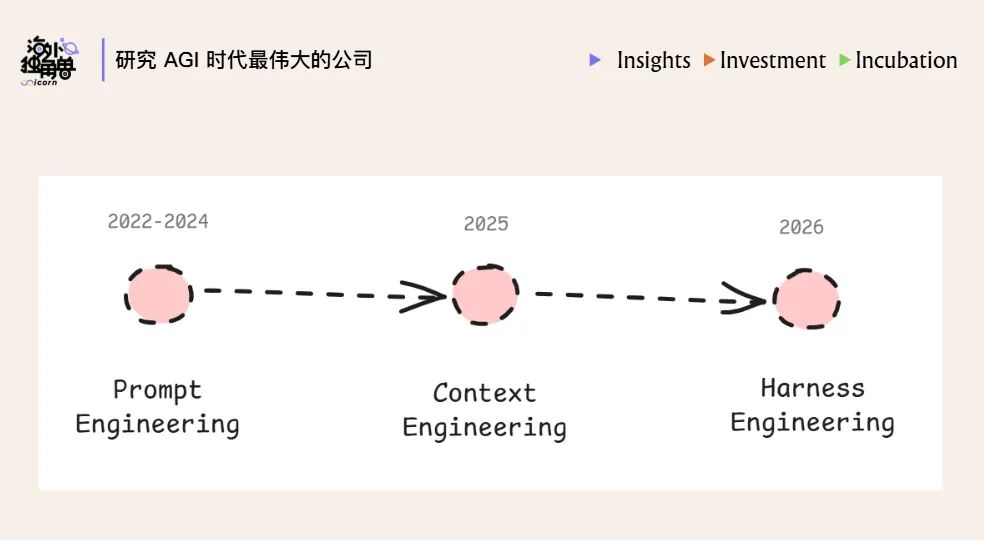
这张图表达的是控制面的上移:早期主要控制模型“怎么回答”,后来控制模型“能看到什么”,再后来控制整个 Agent “怎么完成任务”。
| 阶段 | 关注点 | 主要问题 | 典型做法 |
|---|---|---|---|
| Prompt Engineering | 指令表达 | 怎么让模型理解单次任务 | 角色设定、任务描述、示例、输出格式约束 |
| Context Engineering | 上下文组织 | 怎么让模型拿到恰好够用的信息 | 检索、压缩、摘要、上下文裁剪 |
| Harness Engineering | 系统构建 | 怎么让 Agent 在真实环境里完成长链路任务 | 工具、记忆、编排、沙箱、权限、验证、观测 |
Prompt Engineering 解决的是“问得清楚”;Context Engineering 解决的是“资料给得合适”;Harness Engineering 解决的是“让模型进入一个可执行、可验证、可恢复的系统”。
当模型的基础推理、代码、工具调用能力达到可用水平后,单纯继续堆提示词的收益会下降。更大的提升来自系统层:是否有干净的上下文、是否能调用正确工具、是否能把任务拆开、是否能自动测试、是否能记录失败轨迹并持续修正。
Harness 的 6 个核心组件
工程实践里,Harness 通常可以拆成 6 个组件:记忆与上下文、工具与技能、编排与协调、基础设施与安全护栏、评估与验证、追踪与可观测性。
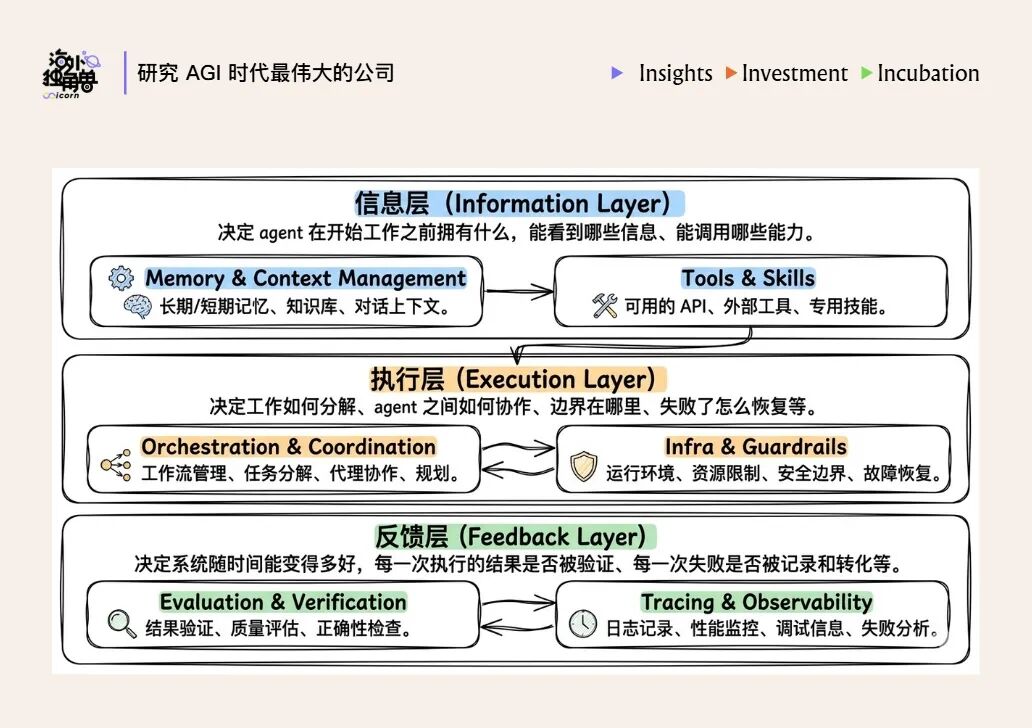
图中的 6 个组件可以进一步归入三层:
- 信息层:决定 Agent 看到什么。
- 执行层:决定 Agent 如何行动。
- 反馈层:决定系统如何被验证、调试和持续改进。
flowchart TB
subgraph Info[信息层]
A[Memory & Context<br/>记忆与上下文管理]
B[Tools & Skills<br/>工具与技能入口]
end
subgraph Exec[执行层]
C[Orchestration<br/>任务编排与多 Agent 协调]
D[Infra & Guardrails<br/>沙箱、权限、安全与恢复]
end
subgraph Feedback[反馈层]
E[Evaluation & Verification<br/>评估与验证]
F[Tracing & Observability<br/>轨迹、日志、监控与成本]
end
Info --> Exec --> Feedback
Feedback --> Info
1. Memory & Context:让 Agent 看到正确的信息
记忆与上下文管理解决的是:当前任务到底需要哪些信息。
它包括:
- 从文档、代码库、工单、日志、聊天记录中检索相关内容;
- 把长文本压缩成模型能处理的摘要;
- 把历史状态写入外部存储,而不是全部塞进上下文窗口;
- 根据任务阶段动态加载资料;
- 清理已经过期或无关的信息。
这里的关键不是“越多越好”,而是“足够准确”。上下文窗口是稀缺资源,噪音会挤占模型注意力。
2. Tools & Skills:扩展 Agent 的行动能力
工具让 Agent 能做事,技能让 Agent 能复用方法。
工具通常是可调用能力,例如:
- 搜索代码;
- 读写文件;
- 执行命令;
- 调用 API(应用程序编程接口);
- 查询数据库;
- 打开浏览器;
- 提交 Pull Request;
- 运行测试。
技能更像任务手册,例如:
- 如何修复某类测试失败;
- 如何发布一个版本;
- 如何排查线上告警;
- 如何按照团队规范写设计文档。
工具提供动作,技能提供方法。工具太少会限制 Agent,工具太多又会让它在选择上犯错,所以工具集设计需要克制。
3. Orchestration & Coordination:把长任务拆开并收敛
真实任务往往不是一步完成的。比如“给系统增加登录鉴权”至少涉及需求澄清、方案调研、数据库设计、接口实现、前端接入、测试、上线回滚方案。
编排层负责:
- 判断任务是否需要规划;
- 拆分子任务;
- 决定哪些任务可以并行;
- 分配给主 Agent 或 subagent;
- 处理中间结果;
- 合并结论并推进下一步。
一个可靠的 Agent 系统不能只会“执行下一步”,还要能判断“下一步是否仍然正确”。
4. Infra & Guardrails:提供安全、稳定的运行环境
当 Agent 开始调用工具、写代码、访问数据时,安全问题会立刻出现。
基础设施与护栏包括:
- 沙箱环境;
- 文件系统隔离;
- 网络权限控制;
- 密钥管理;
- 操作审批;
- 失败重试;
- 状态持久化;
- 回滚机制;
- 审计日志。
没有这一层,Agent 很容易从“自动化助手”变成“不可控脚本”。尤其在企业环境里,Agent 的权限必须遵循最小权限原则:只给完成当前任务所需的权限。
5. Evaluation & Verification:让 Agent 自己知道做得对不对
复杂任务的质量往往不取决于第一次生成,而取决于有没有验证闭环。
验证方式可以是:
- 单元测试;
- 集成测试;
- lint 检查;
- 类型检查;
- UI(用户界面)自动化测试;
- 人工评审;
- LLM scorer,即用另一个模型按规则打分;
- 业务指标回归测试。
没有验证,Agent 只能“看起来完成了”;有验证,Agent 才能根据反馈继续修正。
6. Tracing & Observability:把黑箱变成可调试系统
可观测性解决的是:Agent 到底做了什么。
一条完整 trace 通常包括:
- 用户输入;
- 模型中间思考或计划摘要;
- 每次工具调用;
- 工具返回结果;
- 失败和重试;
- token 消耗;
- 延迟;
- 最终输出;
- 验证结果。
没有 trace,就很难判断问题发生在提示词、上下文、工具、模型、权限还是验证标准上。Agent 越复杂,可观测性越重要。
一个例子:OpenClaw 的亮点不在模型,而在 Harness
OpenClaw 的走红很适合用来理解 Harness。它的核心并不是换了一个更强模型,而是把几个工程组件组合到了一起,让 Agent 呈现出“跨平台存在感”和“持续行动能力”。
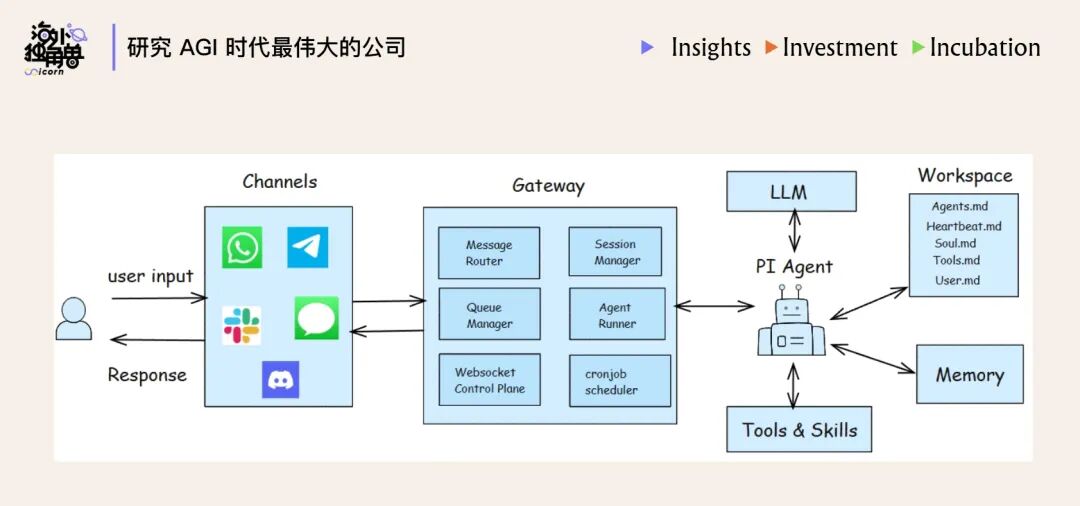
图中这类系统通常由几块能力拼出来:
| 组件 | 作用 |
|---|---|
| Gateway | 对接 WhatsApp、Discord 等外部入口,让 Agent 能出现在不同平台 |
| Skills 库 | 提供可复用能力,例如搜索、写作、沟通、执行任务 |
| Memory | 记录长期偏好、历史互动和经验 |
| Heartbeat | 定时唤醒 Agent,让它能主动发起动作 |
| 身份文件 | 用稳定设定约束语气、行为边界和角色一致性 |
单个组件并不神秘,组合之后效果会发生变化。跨平台入口让 Agent 有“出现位置”,记忆让它有“连续性”,定时机制让它有“主动性”,身份设定让它有“稳定人格”。这些都不是模型参数本身直接提供的,而是 Harness 设计出来的行为模式。
信息层设计:上下文不是越多越好
Agent 最大的工程约束之一是上下文窗口。上下文窗口指模型一次请求中能处理的 token 数量上限。很多人会自然地认为:上下文越长,模型知道得越多,结果越好。
实际情况更复杂。随着上下文变长,模型容易出现 context decay(上下文衰减):它虽然“看见”了更多信息,但对关键内容的利用率下降,尤其当关键线索被埋在大量无关内容中间时,模型可能无法稳定抓住重点。
渐进式披露:只在需要时加载信息
渐进式披露的原则是:不要一次性把所有资料都塞给模型,而是把信息分层,让模型按任务阶段加载。
以 Claude Code 这类编码 Agent 的文件组织方式为例,可以把项目知识拆成三层:
project/
├── CLAUDE.md # Level 1:项目级核心规则
├── skills/
│ ├── fix-test/
│ │ └── SKILL.md # Level 2:某类任务的方法
│ └── release/
│ └── SKILL.md
├── docs/
│ ├── architecture.md # Level 3:参考资料
│ └── api.md
├── scripts/
│ ├── run-tests.sh # Level 3:可执行脚本
│ └── check-style.sh
└── src/
CLAUDE.md 不应该写成巨大的百科全书,它更适合放少量高频规则和导航信息:
# Project Instructions
## Core rules
- 修改代码前先阅读相关测试。
- 非简单任务必须先给出计划。
- 不要直接修改数据库迁移文件,除非任务明确要求。
- 完成后运行对应测试,不要只声称已经完成。
## Where to look
- API 设计见 docs/api.md
- 架构说明见 docs/architecture.md
- 测试命令见 scripts/run-tests.sh
- 发布流程见 skills/release/SKILL.md
SKILL.md 则面向具体任务:
# Skill: Fix Failing Tests
## When to use
当测试失败、CI 报错或用户要求修复 bug 时使用。
## Steps
1. 运行最小失败测试,确认错误可复现。
2. 阅读失败堆栈,不要先改代码。
3. 查找最近相关修改。
4. 做最小修复。
5. 重新运行失败测试。
6. 如果影响公共接口,运行完整测试集。
这种结构的价值在于:模型一开始只看到最关键的规则,需要修测试时再加载修测试技能,需要发布时再加载发布流程。上下文被用在当前任务上,而不是被历史资料占满。
工具要少而准
给 Agent 加工具很容易,难点是删工具。
工具越多,Agent 需要做的选择越多,错误路径也越多。一个包含几十个相似工具的工具箱,可能会带来三个问题:
- Agent 不知道该选哪个;
- Agent 对工具参数产生幻觉;
- 工具返回结果太多,进一步污染上下文。
更好的做法是提供少量通用工具,并让这些工具的行为稳定、返回清晰。
| 工具设计方式 | 结果 |
|---|---|
| 大量细碎工具,每个只做一点点 | 选择成本高,容易误用 |
| 少量通用工具,参数清晰 | 容易组合,调试成本低 |
| 工具返回完整原始数据 | 上下文占用高 |
| 工具返回摘要 + 可追溯引用 | 更适合长任务 |
一个编码 Agent 通常只需要这些基础工具就能完成大量任务:
read_file
write_file
search
list_directory
run_command
open_browser
call_api
新增工具前要问三个问题:
- 这个工具是否明显减少任务步骤?
- 它是否比现有工具组合更可靠?
- 它的返回结果是否足够简洁,能避免污染上下文?
如果答案不明确,先不要加。
控制上下文窗口利用率
长上下文能力不等于可以把窗口塞满。大海捞针测试能直观看到这个问题:输入 token 越接近上限,检索命中率越容易下降。
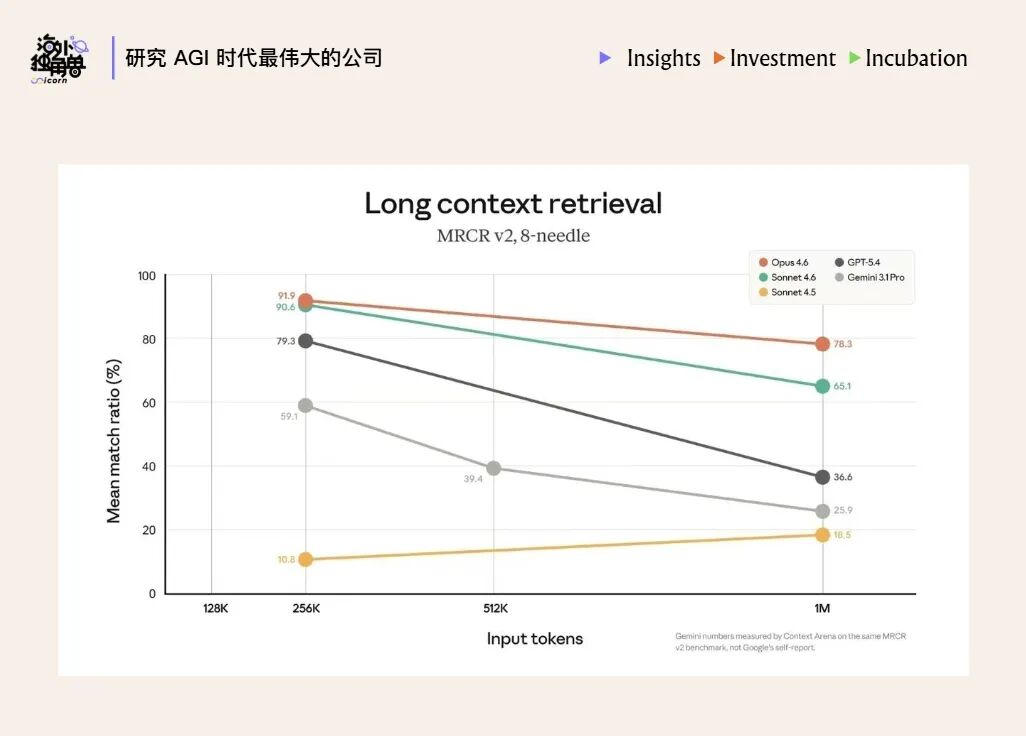
图里的趋势说明,模型在长上下文中并不是稳定线性地吸收信息。即便模型支持很大的上下文窗口,当输入从几十万 token 增加到接近上限时,关键事实的召回率也可能明显下降。
工程上可以采用几条简单规则:
| 规则 | 目的 |
|---|---|
| 定期压缩历史上下文 | 避免旧信息挤占窗口 |
| 把长期记忆放外部存储 | 不把所有历史都放进 prompt |
| 只检索当前阶段需要的文档 | 降低无关噪音 |
| 主 Agent 只保留摘要 | 让主线程聚焦决策 |
| 超过阈值时切新 session | 避免上下文衰减继续扩大 |
很多复杂任务可以把上下文窗口利用率控制在 60% 以下。这个数字不是绝对标准,但它提醒我们:不要因为模型支持长上下文,就默认长上下文一定更好。
用 subagent 做上下文隔离
当主 Agent 的上下文变重时,可以把任务拆给 subagent。每个 subagent 在独立上下文中完成一个小任务,最后只把结论返回给主 Agent。
flowchart LR
U[用户任务] --> M[主 Agent<br/>负责规划与收口]
M --> A1[Subagent A<br/>查代码]
M --> A2[Subagent B<br/>查日志]
M --> A3[Subagent C<br/>查文档]
A1 --> R1[代码结论摘要]
A2 --> R2[日志结论摘要]
A3 --> R3[文档结论摘要]
R1 --> M
R2 --> M
R3 --> M
M --> P[统一计划]
P --> E[执行与验证]
这种做法可以理解为 context firewall(上下文防火墙):查日志的上下文不会污染查代码的上下文,查文档的中间噪音也不会全部进入主线程。主 Agent 只处理摘要、决策和最终收敛。
执行层设计:把研究、计划、执行、验证拆开
很多 Agent 失败不是因为模型不会写代码,而是任务链条设计得太粗。
一句“帮我实现登录系统”会迫使模型在同一个上下文里同时做需求分析、技术选型、代码实现和测试验证。更可靠的方式是把任务拆成四个阶段:
flowchart LR
A[Research<br/>研究方案] --> B[Plan<br/>制定计划]
B --> C[Execute<br/>执行修改]
C --> D[Verify<br/>验证结果]
D -->|失败| B
D -->|通过| E[交付]
Research:先理解问题,而不是直接开改
研究阶段适合让 Agent 收集信息:
- 当前系统怎么实现认证;
- 是否已有权限模型;
- 使用了什么框架;
- 数据库结构是什么;
- 有哪些测试;
- 团队规范是什么;
- 可能方案有哪些;
- 每个方案的风险是什么。
这个阶段不应该改代码,只产出事实和方案对比。
Plan:把执行步骤写清楚
计划阶段要把任务变成可执行列表。一个好的计划应该包含:
- 要改哪些文件;
- 每个文件为什么要改;
- 不改哪些地方;
- 测试怎么跑;
- 回滚点在哪里;
- 哪些地方需要人工确认。
示例:
# Plan: Add Password Login
## Scope
实现邮箱 + 密码登录,不包含第三方 OAuth。
## Files to change
- src/auth/service.ts:新增密码校验逻辑
- src/auth/routes.ts:新增 POST /login
- src/db/schema.ts:确认 users.password_hash 字段
- tests/auth/login.test.ts:补充成功、失败、锁定用户测试
## Steps
1. 阅读现有 auth service 和 user model。
2. 添加 password hash 校验函数。
3. 新增 login route。
4. 添加测试。
5. 运行 auth 测试。
6. 若 auth 测试通过,再运行完整后端测试。
## Verification
- npm test -- tests/auth/login.test.ts
- npm run lint
Execute:用干净上下文落实计划
执行阶段最好从一个干净 session 开始,只带入已确认计划和必要文件。研究阶段的大量讨论、废弃方案和无关资料会干扰执行。
输入给执行 Agent 的内容 = 最终计划 + 必要规则 + 当前相关文件
不输入 = 研究过程中的全部讨论 + 被否决方案 + 大量背景材料
这样做能减少模型在执行时“想起”错误分支,尤其适合复杂代码修改。
Verify:让完成标准变成可运行检查
验证阶段不能只靠 Agent 自述。完成标准越可执行,结果越可靠。
| 任务类型 | 验证方式 |
|---|---|
| 代码修改 | 单元测试、集成测试、lint、类型检查 |
| 前端交互 | 浏览器自动化、截图对比、关键路径点击 |
| 文档生成 | 规则检查、事实核对、链接检查 |
| 数据分析 | SQL 复算、抽样检查、指标一致性 |
| 业务流程 | 端到端测试、回归用例、人工审批 |
一个实用原则是:复杂任务只要超过 3 个步骤,或者涉及架构判断,就应该先进入计划模式;一旦执行中发现计划不成立,停止继续推进,回到计划阶段重做。
人类介入点:把精力放在上游计划
很多人习惯把时间花在最终验收或代码审查上,但对 Agent 来说,人类更应该介入研究和计划阶段。
原因很直接:一行糟糕代码影响的可能只是局部;一个糟糕计划会生成一批糟糕代码。越上游的判断,单位时间影响越大。
| 阶段 | 人类介入价值 | 适合做什么 |
|---|---|---|
| Research | 高 | 补充业务背景、指出约束、确认事实 |
| Plan | 最高 | 审查方案边界、风险、文件范围、验证标准 |
| Execute | 中 | 处理权限审批、关键取舍 |
| Verify | 中 | 检查体验、业务语义和不可自动化判断 |
最有杠杆的做法不是“让 Agent 做完再挑错”,而是“让 Agent 开始做之前就把方向定准”。
反馈层设计:把每次失败变成系统资产
Harness Engineering 最重要的工程纪律之一是:Agent 每犯一次错,就把防止同类错误再次发生的机制补上。
这个机制可以很简单,比如把规则写进 AGENTS.md 或 CLAUDE.md:
# Lessons Learned
## Database migrations
- 不要修改已经发布到生产环境的 migration。
- 需要 schema 变化时,新建 migration 文件。
## Tests
- 修复 bug 后必须新增回归测试。
- 如果只运行了单个测试,需要说明没有运行完整测试集的原因。
## API changes
- 修改接口响应字段时,必须同步更新 docs/api.md。
这不是为了让规则文件越来越长,而是为了把高频失败沉淀成系统记忆。每条规则都应该来自真实错误,并且可执行、可检查。
自动反馈闭环
更进一步,可以让 Agent 进入自动迭代循环:生成结果、运行验证、观察失败、修复、再次验证,直到满足完成条件或达到预算上限。
flowchart TD
A[生成方案或代码] --> B[运行验证]
B --> C{是否通过}
C -->|是| D[交付结果]
C -->|否| E[分析失败原因]
E --> F[修正方案]
F --> B
C -->|超过预算或风险过高| G[请求人工介入]
这个闭环适合很多场景:
- 编码 Agent 自动修测试;
- UI Agent 自动打开浏览器检查交互;
- Research Agent 自动提出实验、跑实验、观察结果;
- 增长 Agent 自动生成多个版本并根据指标筛选;
- 数据 Agent 自动校验异常指标。
关键不在于让模型“一次答对”,而是让系统能不断筛选和纠偏。
模型和 Harness 的关系:不是外挂,而是共同进化
很多人会问:随着模型变强,Harness 会不会被模型吃掉?
答案不是简单的“会”或“不会”。更准确地说,模型和 Harness 正在形成共同进化关系:Harness 先在外部系统中创造能力,成功模式再被训练进模型,模型变强后又需要新的 Harness 支持更复杂任务。
训练即部署:Agentic RL 依赖真实环境
普通聊天模型常见的 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)更偏单轮反馈:模型回答,人工或奖励模型打分,优化输出偏好。
Agentic RL(面向智能体的强化学习)复杂得多:
- 一次 rollout 可能包含多轮推理;
- 可能调用上百次工具;
- 动作空间巨大;
- 奖励信号稀疏;
- 成败依赖真实环境反馈,例如测试是否通过、代码是否能跑、lint 是否报错;
- 任务中间状态需要长期保持。
这意味着训练环境本身会强烈影响模型能力。模型训练时用什么工具、什么终端、什么沙箱、什么反馈,上线后就更擅长处理什么环境。
flowchart LR
A[Harness 设计<br/>工具、沙箱、反馈] --> B[Agentic RL 训练]
B --> C[模型学会工具使用与验证策略]
C --> D[线上 Agent 产品]
D --> E[真实轨迹与失败案例]
E --> A
Cursor、Windsurf 等编码 Agent 的实践都体现了这点:模型不是先在真空里学会“写好代码”,再随便接一个工具环境;相反,模型在接近真实用户工作区的环境中反复试错,逐渐学会搜索代码、少量修改、补测试、修 linter 错误、在合适时机停下来验证。
Harness 能力会被模型内化
很多现在由 Harness 提供的能力,未来可能逐渐进入模型本身,例如:
- 自动规划;
- 工具搜索;
- 多步工具调用策略;
- 自我压缩和摘要;
- 自我验证;
- 判断何时请求人工介入。
这个过程通常是循环式的:
- 工程团队和用户在 Harness 里试出有效模式;
- 训练团队把这些执行轨迹用于后训练;
- 模型内化一部分能力;
- 旧 Harness 的部分逻辑变得多余;
- 新 Harness 支持更长、更复杂、更高风险的任务;
- 新轨迹继续反哺模型。
所以 Harness 不是静态产品,而是一层会被不断重写的系统。它的价值不只在当下执行任务,也在于生成下一轮训练所需的数据。
Harness 就是数据集
“静态语料”已经不是唯一重要的数据。Agent 执行真实任务时产生的轨迹,正在变成更有价值的数据类型。
一条高质量轨迹包含:
{
"task": "修复登录接口测试失败",
"context_used": ["auth/service.ts", "tests/auth/login.test.ts"],
"tools_called": [
{"tool": "search", "query": "login"},
{"tool": "read_file", "path": "src/auth/service.ts"},
{"tool": "run_command", "cmd": "npm test -- tests/auth/login.test.ts"}
],
"decisions": [
"先复现失败",
"只修改 password hash 校验逻辑",
"补充回归测试"
],
"failures": [
"第一次修复遗漏 locked user 分支"
],
"verification": {
"unit_test": "passed",
"lint": "passed"
}
}
这种数据比普通问答更接近真实智能行为,因为它记录了 Agent 看什么、怎么选工具、在哪里失败、如何被反馈纠正。谁能持续捕获高质量执行轨迹,谁就更容易形成数据飞轮。
创业和产品机会:Harness 栈会长出哪些基础设施
Harness 可以按信息层、执行层、反馈层拆出不少产品机会。每一层都对应企业落地 Agent 时的真实痛点。
信息层:企业上下文系统
企业知识往往分散在工单、日志、邮件、聊天记录、文档、代码仓库里。Agent 要想完成任务,必须知道“公司真实怎么运转”,而不是只读取几份说明文档。
这一层的机会是把隐性流程变成 Agent 可使用的动态上下文和 playbook。
| 能力 | 价值 |
|---|---|
| 读取 tickets、logs、emails、chat histories | 收集真实流程线索 |
| 还原业务操作路径 | 让 Agent 知道任务通常怎么完成 |
| 生成 playbook | 把经验变成可复用步骤 |
| 按任务动态检索 | 避免一次性塞入全部企业知识 |
Edra 这类产品把自己定位为大规模 Agent 上下文系统,目标是学习企业如何运行,再把流程自动化。
执行层:长任务编排和持久执行
Agent 任务会越来越长。一个任务可能持续几小时、几天,甚至等待外部事件后继续执行。传统脚本一旦进程挂掉、网络断开、节点重启,就容易丢状态。
Durable Execution(持久执行)基础设施解决的是:
- 当前执行到哪一步;
- 哪些步骤已经成功;
- 哪些步骤可以重试;
- 哪些状态必须持久化;
- 服务挂掉后如何从断点继续。
Temporal 是这一层的代表。它对 Agent 的意义在于:让长链路、多步骤、可失败的任务不再依赖单个进程“活着跑完”。
执行层:Agent 权限与治理
企业里访问系统的不再只有人,也会有大量 Agent。每个 Agent 都可能拥有数字身份、访问权限和操作记录。
权限治理要回答几个问题:
- 企业里有多少 Agent 身份;
- 每个 Agent 能访问哪些系统;
- 权限是否过大;
- 谁批准了权限;
- Agent 做了哪些操作;
- 出问题后如何追责和回滚。
Oasis Security 这类平台关注的就是 Agentic Enterprise 里的身份、权限和治理。
执行层:沙箱和工作区
一次性代码执行盒子适合短任务,但长周期 Agent 更像一个“数字员工”,需要稳定工作区:
- 持久文件系统;
- 可恢复终端;
- 独立依赖环境;
- 项目状态保存;
- 安全隔离;
- 可审计操作记录。
Daytona 这类沙箱基础设施的价值在于给 Agent 一台可长期使用的电脑,而不是每次执行完就销毁的临时容器。
反馈层:评估与可观测性平台
企业部署 AI 应用后,需要独立质量控制面板来回答:
- 哪些请求失败了;
- 失败发生在哪个环节;
- 哪个模型版本更好;
- 哪个 prompt 版本更稳定;
- token 和成本花在哪里;
- 上线前测试集是否通过;
- 线上真实问题能否沉淀成回归用例。
Braintrust 这类平台通常覆盖三步:
| 步骤 | 作用 |
|---|---|
| 记录过程 | 把生产请求记录成 traces,包括输入、输出、中间步骤、延迟、成本 |
| 判断好坏 | 用人工标注、规则或 LLM scorer 给结果评分 |
| 持续优化 | 把线上问题沉淀成测试集,比较 prompt、模型和工具版本 |
这一层不只是看板。一旦接入数据采集、评分、版本发布和回归测试流程,替换成本会变高,也更不容易被单一模型厂完全覆盖。
Harness 之后:Coordination Engineering
Prompt、Context、Harness 的演进很像一个员工从新手到独立执行者的成长过程:
- 一开始,只能回答清楚的问题;
- 后来,能阅读背景资料完成研究;
- 再后来,能拿到工具、权限和反馈机制,独立推进任务;
- 下一阶段,需要协调多个 Agent 和人类节点共同完成复杂项目。
可以把下一层称为 Coordination Engineering:协调工程。
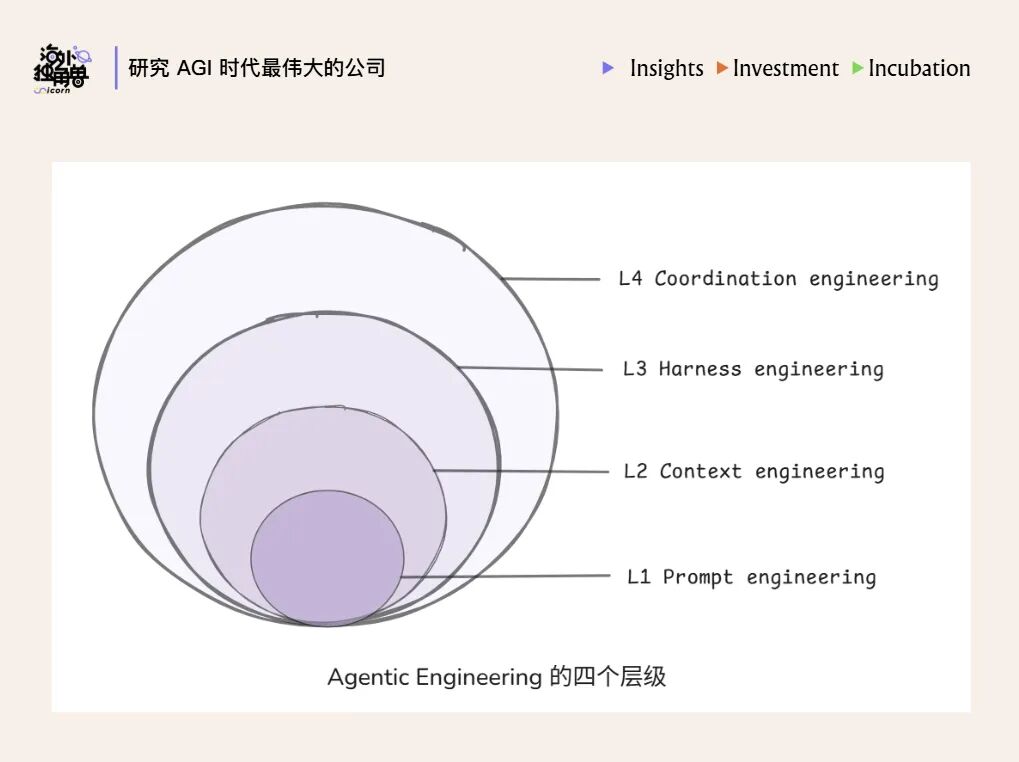
图中的层级可以这样理解:
| 层级 | 工程范式 | 解决的问题 |
|---|---|---|
| L1 | Prompt Engineering | 问答质量 |
| L2 | Context Engineering | 认知边界 |
| L3 | Harness Engineering | 执行闭环 |
| L4 | Coordination Engineering | 组织协同 |
Multi-agent networks 会带来新的复杂度:用户需要知道每个 Agent 在做什么、当前流程推进到哪一步、哪些动作需要授权、哪些结果需要纠偏、不同 Agent 的输出如何合并。
下一代 AI 产品可能不只是一个更聪明的单体助手,而更像一个面向 Agent 的协作系统:既有监工看板,也有即时通信(Instant Messaging,IM)式的协作界面,还要支持权限、状态、审计和任务编排。
关键判断
Harness Engineering 的核心不是给模型包一层花哨界面,而是把 Agent 变成可运行、可验证、可恢复、可优化的工程系统。
实践时可以抓住几条原则:
- 上下文要精准,不要贪多。
- 工具要少而准,避免决策瘫痪。
- 长任务要拆成研究、计划、执行、验证。
- 主 Agent 要做调度和收口,子任务可交给 subagent 隔离上下文。
- 人类最该介入的是计划阶段,而不是只在结果出来后审核。
- 每次失败都要沉淀成规则、测试或自动验证机制。
- trace 是未来训练数据,Harness 捕获的执行轨迹会反哺模型能力。
当模型基础能力继续提升,竞争优势会越来越多地来自系统层:谁能设计更好的任务环境,谁能捕获更高质量的执行轨迹,谁就更可能在垂直场景里做出成本更低、结果更稳的 Agent 系统。