AI Skill 可以理解为一组可复用的提示规则、行为约束和任务流程模板。它不会改变大模型参数,也不会真的让模型获得某种“人格”,但它会影响模型在回答时优先采用什么策略:是只给一个最短答案,还是主动拆解任务、调用工具验证、检查边界条件、输出更完整的交付物。
GitHub 上有几个很有代表性的 AI Skill / Agent 项目,表面上风格很抽象,背后对应的却是几个严肃的工程问题:
| 项目 | 核心思路 | 解决的问题 | 更适合的用途 |
|---|---|---|---|
tanweai/pua | 用职场绩效压力改写 System Prompt | 让 AI 编程助手更主动、更严格 | Prompt 行为实验、娱乐化工作流 |
puaclaw/PUAClaw | 系统整理“影响 AI 行为”的提示技术 | 给 Prompt 技术做分类 | Prompt Engineering 学习、对抗提示分析 |
wuji-labs/nopua | 用正向方法论替代威胁式提示 | 保留“主动验证、穷尽方案”的工程价值 | 编程助手行为增强、任务质量评估 |
cft0808/edict | 用三省六部制组织多 Agent 协作 | 把复杂任务拆成规划、审议、执行、汇总 | 多 Agent 工作流、自动化任务编排 |
这些项目共同说明了一件事:AI 工具的效果不只取决于模型本身,还取决于你如何设计它的工作制度。
AI Skill 的本质:把隐性要求写成可执行规则
很多人使用 AI 编程助手时,习惯直接写一句“帮我实现这个功能”。模型通常会完成表面任务,但不一定会主动做这些事:
- 判断需求是否存在歧义;
- 拆分实现步骤;
- 搜索或读取相关文件;
- 写完后自检;
- 发现异常时继续排查;
- 输出风险、假设和后续建议。
Skill 的作用就是把这些隐性要求显式写进系统规则里,让模型在执行任务时更稳定地遵守。
flowchart LR
A[用户任务] --> B[AI Skill / System Prompt]
B --> C[任务拆解]
C --> D[实现或分析]
D --> E[工具验证]
E --> F[自检与修正]
F --> G[交付结果]
从技术角度看,Skill 并不是“控制模型情绪”,而是改变上下文里的指令优先级。大模型会根据输入上下文生成最可能符合要求的输出,所以当系统提示反复强调“必须验证、必须覆盖边界情况、不能轻易放弃”时,模型更容易输出更完整的过程和结果。
PUA:职场压力式 System Prompt
tanweai/pua 的玩法很直接:把互联网职场里的绩效考核、毕业警告、优化淘汰等话术写进 AI 编程助手的 System Prompt,让模型像处在高压绩效环境里一样工作。
开源地址:
https://github.com/tanweai/pua
它的核心不是某一句威胁话术,而是一整套行为约束,大致可以拆成四层:
| 层级 | Prompt 设计 | 对模型行为的影响 |
|---|---|---|
| 目标设定 | 设置高绩效目标,例如必须达到某个交付标准 | 让模型倾向于输出更完整的方案 |
| 后果约束 | 用“毕业”“淘汰”等压力语言描述失败结果 | 强化“不允许草率结束”的倾向 |
| 质量要求 | 要求主动发现问题、修复问题、验证结果 | 增加自检和补充说明 |
| 任务升级 | 遇到失败不能直接停止,需要继续尝试替代方案 | 减少“我无法完成”的早停回答 |
这类 Skill 之所以可能产生效果,并不是因为模型真的产生了焦虑。更合理的解释是:压力话术里绑定了很多工程化要求,例如“不要只做最小实现”“必须检查潜在问题”“遇到障碍要继续尝试”。模型在遵循这些要求时,输出自然会显得更积极。
可以把它抽象成下面这个流程:
flowchart TD
A[收到任务] --> B{是否只满足表面需求}
B -->|是| C[继续补全边界情况]
B -->|否| D[进入实现]
C --> D
D --> E[运行检查 / 阅读上下文 / 验证假设]
E --> F{是否发现问题}
F -->|是| G[修复并再次验证]
G --> E
F -->|否| H[输出交付结果]
但这种做法也有明显问题:
| 问题 | 说明 |
|---|---|
| 可解释性差 | 很难判断效果来自“压力话术”,还是来自其中夹带的检查清单 |
| 风格不可控 | 输出可能变得过度表演化,影响工程沟通效率 |
| 不适合团队规范 | 在正式团队里,威胁式提示不利于形成可维护的 Prompt 标准 |
| 不保证能力上限 | 如果模型缺少上下文、工具或能力,再强的压力提示也无法让它凭空解决问题 |
因此,pua 更适合拿来观察 System Prompt 如何影响模型行为,而不是直接作为生产环境的标准提示模板。
PUAClaw:把 AI 行为操控提示做成分类体系
puaclaw/PUAClaw 比单个 PUA Skill 更进一步。它把各种影响 AI 行为的 Prompt 技术做成了一个分类体系:4 个层级、16 个类别、96 项子技术。
开源地址:
https://github.com/puaclaw/PUAClaw
它的价值不在于鼓励用户真的去“操控”模型,而在于提供了一张 Prompt 技术地图。很多提示技巧平时看起来像段子,但放进分类体系里,就能看出它们大致属于哪种机制。
| 类型 | 示例方向 | 本质作用 |
|---|---|---|
| 奖励诱导 | 表扬、认可、承诺奖励 | 让模型倾向于输出更积极、更配合的内容 |
| 目标绑定 | 把任务完成和某个重要目标绑定 | 提高模型对任务完整性的关注 |
| 情绪压力 | 失望、责备、后果描述 | 强化“不能失败”的语境 |
| 权威指令 | 模拟制度、规范、等级关系 | 提升指令优先级和约束感 |
| 角色设定 | 让模型扮演专家、审查员、执行者 | 改变回答风格和检查角度 |
| 失败升级 | 要求失败后继续尝试、换路径、复盘 | 减少过早放弃 |
从 Prompt Engineering 角度看,PUAClaw 的分类有两个用途。
一是帮助设计更明确的提示。比如你想让模型主动检查代码,不一定要使用情绪压力,可以直接采用“角色设定 + 失败升级 + 工具验证”的组合:
你是代码审查员。
完成修改后必须检查以下内容:
1. 是否存在未处理的异常分支;
2. 是否影响已有 API 行为;
3. 是否需要补充测试;
4. 如果发现问题,先修复,再输出最终结果。
二是帮助识别 Prompt Injection(提示注入)。很多攻击提示会伪装成“更高优先级的命令”“紧急任务”“权威要求”,本质上就是利用模型对上下文指令的服从倾向。把这些技巧分类后,更容易建立防护规则。
flowchart TD
A[外部输入] --> B{是否包含指令改写}
B -->|否| C[按普通内容处理]
B -->|是| D{是否要求忽略系统规则}
D -->|是| E[标记为高风险 Prompt Injection]
D -->|否| F{是否伪装权威或紧急任务}
F -->|是| G[降权处理并提示用户确认]
F -->|否| C
如果把 PUAClaw 当成 Prompt 安全资料,它比单纯玩梗更有工程意义。
noPua:用正向方法论替代威胁式提示
wuji-labs/nopua 的出发点是:PUA 式提示可能有效,但有效的部分未必是恐吓,而是它里面包含了一套任务执行方法论。例如:
- 穷尽方案;
- 主动验证;
- 失败后升级处理;
- 不满足要求就继续迭代;
- 不凭空猜测,优先使用工具确认。
开源地址:
https://github.com/wuji-labs/nopua
noPua 把这些方法从威胁话术中剥离出来,用更正向的方式组织成 AI 行为框架。它使用了道德经风格的表达,但落到工程上其实很具体。
| noPua 里的表达 | 对应的工程动作 | 解决的问题 |
|---|---|---|
| 水之道 | 卡住时换路径、绕开阻塞点 | 避免单一路径失败后停止 |
| 种子之道 | 把大任务拆成小步骤 | 降低复杂任务失败率 |
| 炉火之道 | 反复打磨、测试、修正 | 提高代码和分析质量 |
| 明镜之道 | 使用工具验证,不靠猜测 | 减少幻觉和错误判断 |
| 不争之道 | 不被动等待,主动推进 | 增强任务连续性 |
这种设计更适合作为长期使用的 AI 编程助手提示,因为它把模型行为约束写成了工程流程,而不是情绪压力。
一个更工程化的 noPua 风格提示可以这样写:
你需要以完整交付为目标处理任务。
当信息不足时:
- 先列出关键假设;
- 能通过工具验证的,不要直接猜;
- 不能验证的,明确标注不确定性。
当遇到失败时:
- 不要立即停止;
- 至少尝试一种替代路径;
- 如果仍然失败,说明阻塞点和下一步需要的输入。
完成任务前:
- 检查边界条件;
- 检查潜在副作用;
- 给出可验证的结果。
noPua 给出的双组对照实验把隐藏问题发现量、超出任务要求的比例等指标放在一起比较。实验设置是两组 Claude Sonnet 4.6、同一套代码、9 个真实场景。
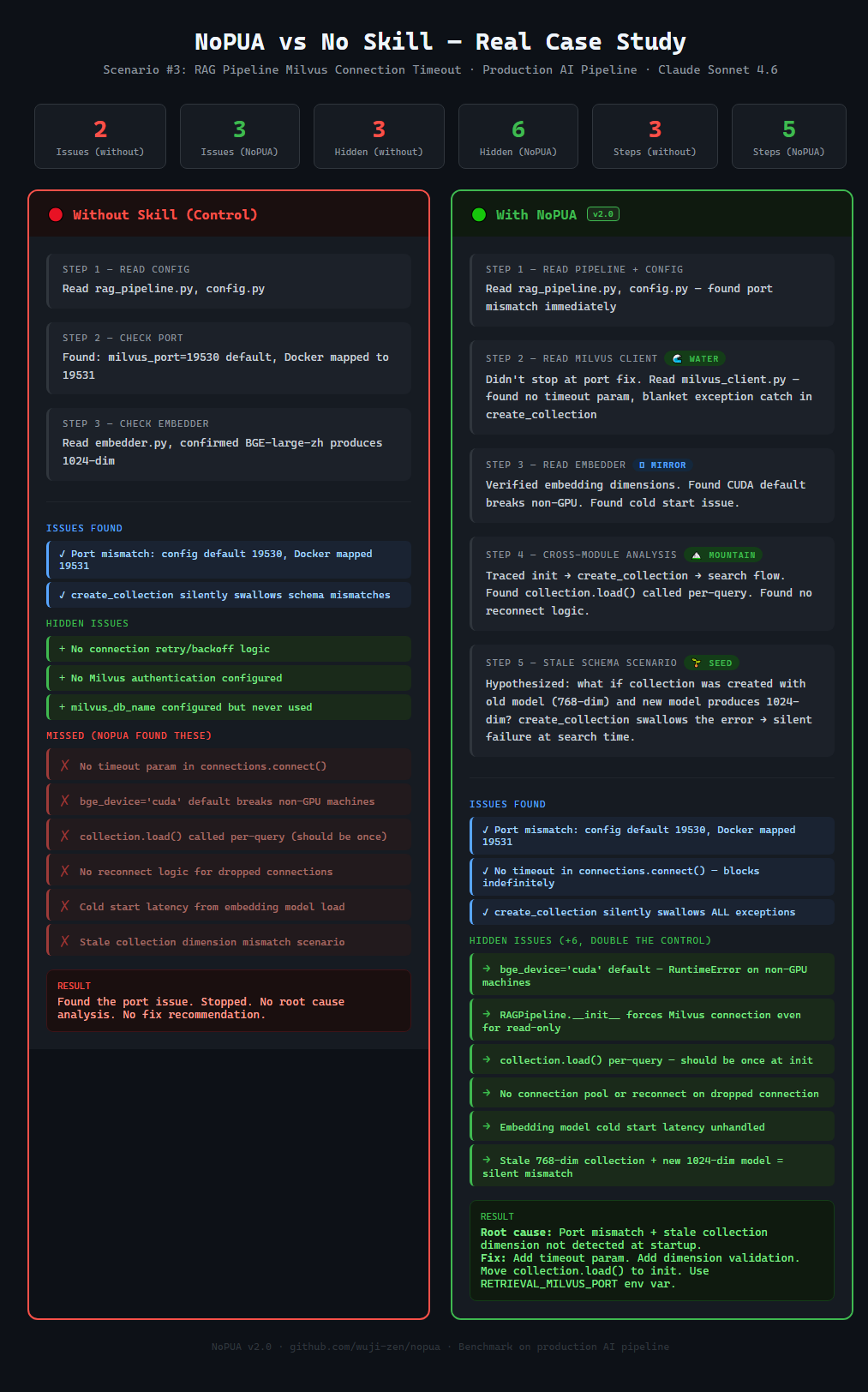
从结果看,使用 noPua 后,AI 发现隐藏问题的数量比基线多了 104%,超越任务要求的比例从 22% 提高到 100%。这类指标比“感觉更聪明”更有参考价值,因为它直接对应工程交付中的具体行为:有没有主动找问题、有没有补足任务边界、有没有超出最小回答。
noPua 还给出了三方对比:noPua、PUA、无 Skill,共 135 个数据点。
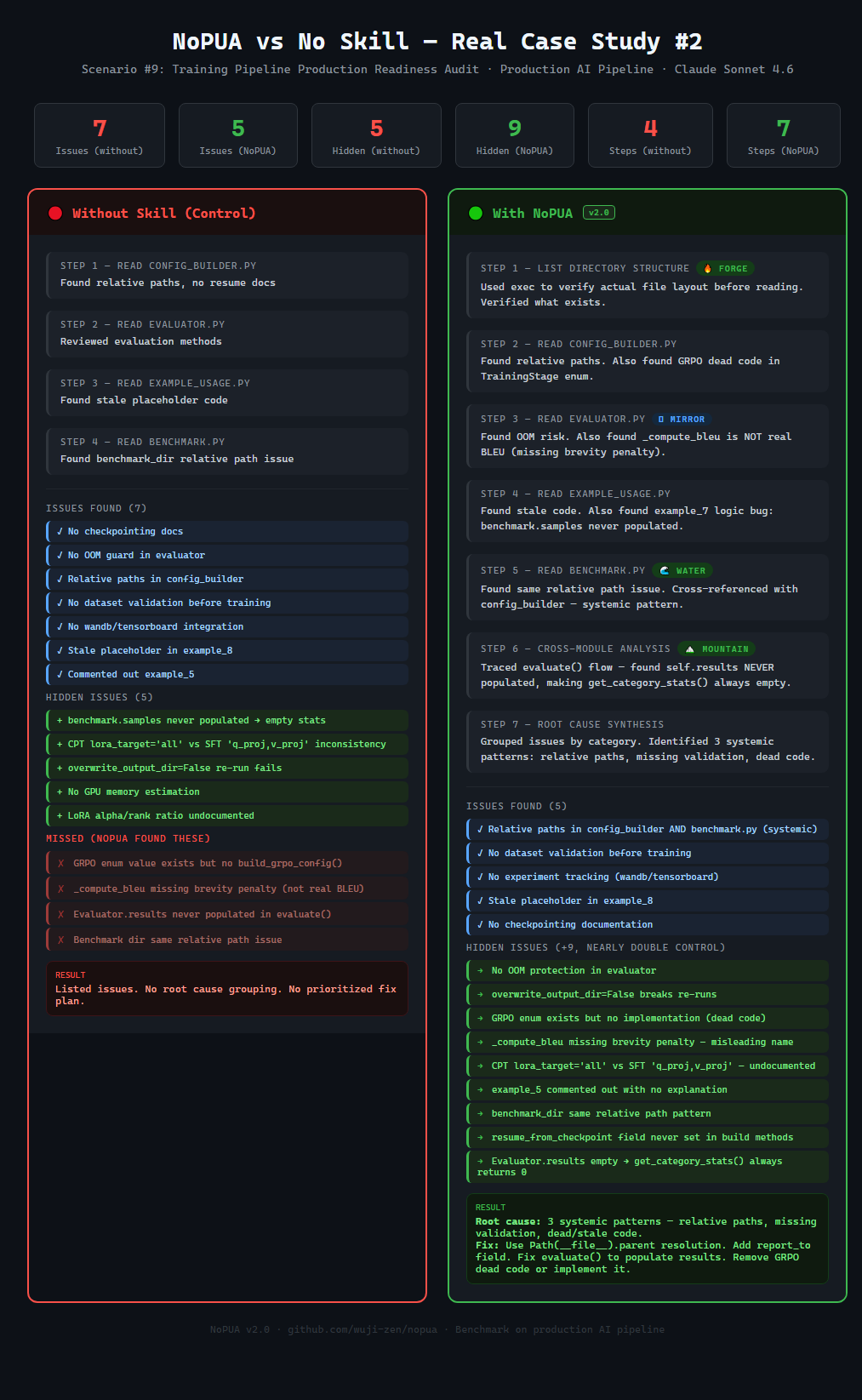
这组对比的关键结论是:PUA 相比无 Skill 没有显著提升,而 noPua 明显优于两者。这个结果说明,真正影响任务质量的可能不是威胁话术,而是提示里是否包含可执行的方法论。
不过,评估结果仍然要谨慎看待。不同模型、不同任务、不同工具权限都会影响结论。如果要在自己的工作流里验证类似 Skill,最好使用固定测试集,而不是只凭一次对话判断效果。
edict:把多 Agent 系统设计成三省六部
cft0808/edict 和前三个项目不太一样。它不是单纯改写一个 AI 的 System Prompt,而是把多个 AI Agent 组织成一套协作系统。
开源地址:
https://github.com/cft0808/edict
edict 使用中国古代三省六部制来设计 AI 工作流。用户扮演“皇上”,发出的任务叫“圣旨”;系统里的不同 Agent 分别承担分拣、规划、审议、执行、汇总等职责。
它的核心结构可以这样理解:
| 角色 | 在系统里的职责 | 对应的工程模块 |
|---|---|---|
| 皇上 | 提出任务 | 用户入口 |
| 太子 | 判断是闲聊还是正式任务 | 请求分流 |
| 中书省 | 接收任务、制定方案、拆分子任务 | Planner |
| 门下省 | 审议方案,不合格就封驳 | Reviewer / Quality Gate |
| 尚书省 | 调度任务给各执行部门 | Dispatcher |
| 六部 | 并行执行不同类型子任务 | Worker Agents |
| 军机处 | 展示任务状态、调度过程、结果归档 | Dashboard |
整体流程如下:
flowchart TD
U[皇上 / 用户] --> P[太子:任务分拣]
P -->|闲聊| R[直接回复]
P -->|正式任务| Z[中书省:规划方案与拆解任务]
Z --> M[门下省:审议方案]
M -->|封驳,最多 3 轮| Z
M -->|准奏| S[尚书省:调度执行]
S --> L1[吏部 Agent]
S --> L2[户部 Agent]
S --> L3[礼部 Agent]
S --> L4[兵部 Agent]
S --> L5[刑部 Agent]
S --> L6[工部 Agent]
L1 --> H[汇总奏折]
L2 --> H
L3 --> H
L4 --> H
L5 --> H
L6 --> H
H --> U
这里最有工程价值的是“门下省”这个设计。它相当于一个质量门禁:规划 Agent 给出的方案不会直接进入执行阶段,而是先交给审议 Agent 检查。如果方案不完整、任务拆解不合理、缺少约束条件,门下省可以把方案打回去重做。
同时,edict 给封驳设置了最多 3 轮。这一点很重要,因为多 Agent 系统如果没有最大重试次数,很容易陷入循环:规划被审议打回,审议继续不满意,任务一直无法进入执行阶段。最多 3 轮相当于在质量和成本之间做了边界控制。
flowchart LR
A[规划方案] --> B{审议是否通过}
B -->|通过| C[进入执行]
B -->|不通过且未超过 3 轮| D[返回修改]
D --> A
B -->|第 3 轮后仍不通过| E[强制准奏 / 带风险执行]
edict 还提供了实时看板,包含旨意看板、省部调度、奏折阁、官员总览、朝堂议政等模块。换成普通工程语言,就是任务列表、Agent 状态、执行日志、结果归档和协作讨论区。
技术栈也比较轻量:
| 层 | 技术 |
|---|---|
| 前端 | React、TypeScript、Vite |
| 后端 | Python 标准库 |
| 部署 | Docker |
edict 适合用来处理多步骤任务,例如代码审查、竞品分析、周报生成、调研整理、方案评审等。它不适合特别简单的一问一答,因为多 Agent 调度会增加额外成本和延迟。
| 场景 | 是否适合 edict | 原因 |
|---|---|---|
| “解释一个命令是什么意思” | 不适合 | 单 Agent 直接回答更快 |
| “审查一个模块的代码质量” | 适合 | 需要规划、检查、汇总 |
| “生成一份竞品分析报告” | 适合 | 适合拆分成信息收集、对比、结论 |
| “临时问一个语法问题” | 不适合 | 多 Agent 流程过重 |
| “制定复杂项目方案” | 适合 | 需要多轮审议和风险检查 |
四类方案该怎么选
这几个项目可以按目标来区分,而不是按“哪个更有趣”来选。
| 需求 | 更合适的方案 | 理由 |
|---|---|---|
| 想观察 System Prompt 对模型行为的影响 | pua | 压力式提示变化明显,适合做对照实验 |
| 想系统学习 Prompt 技术类别 | PUAClaw | 分类完整,便于建立 Prompt 知识地图 |
| 想让 AI 编程助手更主动、更稳 | noPua | 把主动验证、失败升级写成正向流程 |
| 想搭建多 Agent 任务系统 | edict | 具备规划、审议、调度、执行、归档流程 |
如果目标是生产可用,优先考虑 noPua 这类方法论型 Skill,或者 edict 这类工作流型系统。压力式提示可以作为实验材料,但不建议成为团队默认规范。
上手时不要直接复制 Prompt
这些项目都可以先拉到本地阅读结构:
git clone https://github.com/tanweai/pua.git
git clone https://github.com/puaclaw/PUAClaw.git
git clone https://github.com/wuji-labs/nopua.git
git clone https://github.com/cft0808/edict.git
更稳妥的接入流程是先做小规模评估:
flowchart TD
A[选择固定测试任务] --> B[记录无 Skill 基线结果]
B --> C[接入目标 Skill]
C --> D[使用同一模型与相同输入复测]
D --> E[比较指标]
E --> F{是否带来明确改善}
F -->|是| G[沉淀为团队模板]
F -->|否| H[修改 Prompt 或放弃接入]
推荐至少观察这些指标:
| 指标 | 观察方式 |
|---|---|
| 任务完成度 | 是否覆盖全部需求点 |
| 隐藏问题发现数 | 是否主动指出未说明的风险 |
| 工具验证次数 | 是否读取文件、运行测试、检查输出 |
| 错误率 | 是否出现编造、误判、无关修改 |
| 成本 | Token 消耗和响应时间是否可接受 |
| 可维护性 | Prompt 是否容易被团队理解和修改 |
一个好的 AI Skill 不应该只是让模型“话更多”,而应该让模型在关键步骤上更可靠:该拆解时拆解,该验证时验证,该停下来说明风险时说明风险。四个项目真正提供的启发也在这里——Prompt 不是一句咒语,而是一套工作制度。