OpenClaw 可以理解为一个“个人 AI 助手操作系统”:它不只是一个聊天机器人,而是把大语言模型、工具调用、聊天平台、本地设备、浏览器、定时任务、记忆、工作区和多智能体协作统一接起来,让 AI 能进入真实的个人工作流。
它的核心设计不是把所有能力都塞进一个进程里,而是采用 本地优先(Local-First)+ 多端联动 + Gateway 控制平面 的方式组织系统。Gateway 负责统一接入和路由,Agent 负责推理和执行,Channels 负责对接外部聊天平台,Nodes 负责连接设备能力,Tools 与 Skills 负责让 Agent 真正“做事”。
从架构角度看,OpenClaw 主要由这些部分组成:
| 模块 | 作用 |
|---|---|
| Gateway | 统一控制平面,承载 WebSocket、HTTP API、控制台、会话、节点和频道管理 |
| Pi Agent / Agentic Loop | Agent 的推理循环,负责调用大语言模型、处理流式响应和工具调用 |
| Cron | 定时任务系统,支持一次性任务、周期任务和 Cron 表达式 |
| Tools | 工具系统,统一管理文件、命令、浏览器、消息、记忆、画布等工具 |
| Channels | 聊天渠道适配层,连接 Telegram、Slack、Discord、WhatsApp 等平台 |
| Context | 上下文管理,处理模型窗口、压缩、剪枝和运行时注入 |
| SubAgent | 子智能体系统,用于后台并行任务和多层任务编排 |
| Nodes | 设备节点,把 macOS、iOS、Android 等设备能力暴露给 Agent |
| Sandbox | 沙箱隔离,把外部输入或不可信任务限制在容器环境内 |
OpenClaw 的总体架构
OpenClaw 的整体结构可以从这张架构图把握。Gateway 位于系统中心,向上连接控制界面和外部 API,向外连接各类聊天渠道与设备节点,向内调度 Agent、工具、定时任务和会话状态。
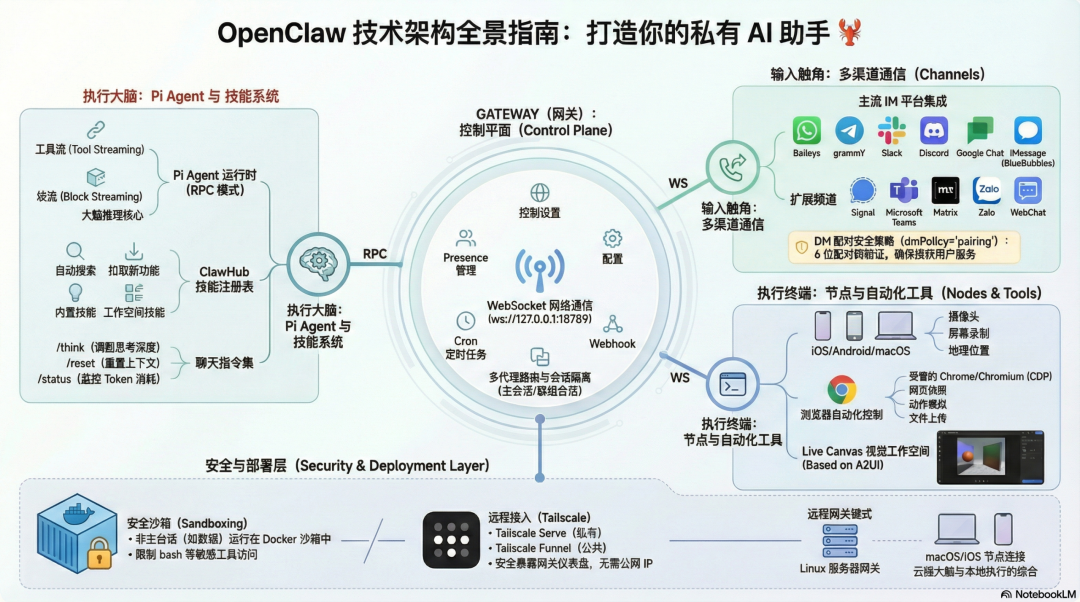
图里的关键点是:OpenClaw 并没有把 AI 助手做成单一聊天入口,而是把 Gateway 设计成一个控制平面。所有外部输入都会进入 Gateway,再由 Gateway 判断应该交给哪个 Agent、哪个会话、哪个工作区处理。Agent 在执行过程中可以调用工具、访问浏览器、控制设备节点,也可以把结果投递回原来的聊天渠道。
简化后可以画成这样:
flowchart LR
User[用户 / 外部平台] --> Channels[Channels 聊天渠道]
Apps[桌面 / 移动端应用] --> Nodes[Nodes 设备节点]
Channels --> Gateway[Gateway 控制平面]
Nodes --> Gateway
ControlUI[Control UI 控制台] --> Gateway
HTTPAPI[HTTP API] --> Gateway
Gateway --> Sessions[Sessions 会话管理]
Gateway --> Cron[Cron 定时任务]
Gateway --> Agent[Pi Agent 推理运行时]
Agent --> Tools[Tools 工具系统]
Agent --> Context[Context 上下文管理]
Agent --> SubAgents[SubAgent 子智能体]
Tools --> Browser[浏览器]
Tools --> Files[文件系统]
Tools --> Shell[命令执行]
Tools --> Memory[记忆]
这种结构解决了三个问题:
- 多入口统一接入:同一个助手可以同时服务 Telegram、Slack、Discord、WhatsApp、iMessage、Web 控制台和本地设备。
- 多会话隔离:不同群组、不同联系人、不同 Agent 可以拥有独立会话和工作区,避免上下文互相污染。
- 能力可控暴露:不同来源的消息可以匹配不同工具策略,例如主会话允许本地命令,外部群聊只能使用安全工具。
Gateway:统一控制平面
Gateway 是 OpenClaw 的中心进程。它本质上是一个 WebSocket(网页套接字)服务器,同时也提供 HTTP(超文本传输协议)API(应用程序编程接口)和控制台 UI(用户界面)。
Gateway 负责的事情很多,但可以归为五类:
| 职责 | 说明 |
|---|---|
| 消息路由 | 接收 Channels 的消息,找到对应 Agent 和会话 |
| 会话管理 | 创建、恢复、更新和删除 Agent 会话 |
| 工具协调 | 让 Agent 能通过 Gateway 调用特定工具或远程能力 |
| 节点通信 | 与 macOS、iOS、Android 等设备节点建立连接 |
| API 暴露 | 提供兼容 OpenAI 风格的 REST(表述性状态转移)接口 |
Gateway 的内部模型
Gateway 对外提供多个入口,但内部会统一进入 RPC(Remote Procedure Call,远程过程调用)路由层。RPC Router 再根据方法名和连接角色,把请求分发给 Channels、Agents、Nodes 或其他服务。
flowchart TB
subgraph Gateway[Gateway 进程]
WS[WebSocket Server]
HTTP[HTTP API / OpenAI Compatible]
UI[Control UI]
WS --> Router[RPC Router]
HTTP --> Router
UI --> Router
Router --> Channels[Channels 消息路由]
Router --> Agents[Agents 会话管理]
Router --> Nodes[Nodes 设备节点]
Router --> Cron[Cron 定时任务]
Router --> Config[配置管理]
end
一个重要设计是 单端口复用。默认情况下,WebSocket RPC、HTTP API 和 Control UI 可以共用 18789 端口。这让本地部署、远程转发、Tailscale 暴露和反向代理配置都更简单。
连接握手与帧格式
Gateway 的连接不是裸连。客户端需要声明角色、权限范围和协议版本,服务端会验证认证信息,再返回策略和设备令牌。
sequenceDiagram
participant C as Client
participant G as Gateway
G-->>C: connect.challenge,可选 nonce 挑战
C->>G: connect,请求携带 auth、role、scopes
G-->>C: hello-ok,返回 policy 和 device token
G-->>C: events,持续推送状态变化
RPC 帧主要有三种:
// 请求
{
type: "req",
id: "request-id",
method: "sessions.list",
params: {}
}
// 响应
{
type: "res",
id: "request-id",
ok: true,
payload: {}
}
// 事件
{
type: "event",
event: "presence.updated",
payload: {},
seq: 100,
stateVersion: 20
}
这种设计的好处是,控制请求、状态事件、工具调用结果都能走同一条 WebSocket 连接。客户端不需要同时维护多套协议。
角色、权限和认证
Gateway 把连接角色分为两类:
| 角色 | 作用 |
|---|---|
operator | 控制平面角色,可以读取或修改配置、会话、任务等 |
node | 能力节点角色,用于暴露设备上的摄像头、位置、录屏、系统命令等能力 |
权限通过 scopes 控制,例如:
| Scope | 含义 |
|---|---|
operator.read | 读取控制面状态 |
operator.write | 修改会话、配置或任务 |
operator.admin | 管理级操作 |
node.invoke | 允许调用设备节点能力 |
认证模式包括:
| 模式 | 使用场景 |
|---|---|
token | 默认共享令牌认证 |
password | 共享密码认证 |
trusted-proxy | 反向代理已完成身份认证,例如 Pomerium |
device-token | 设备配对后使用设备令牌连接 |
安全约束也比较明确:
- Gateway 如果绑定到非本机地址,必须开启认证。
- 明文
ws://不允许连接非本机地址,避免敏感数据在网络中裸传。 - 设备能力通过配对机制获取令牌,而不是默认信任局域网内所有设备。
绑定模式
Gateway 可以绑定到不同网络地址:
| 模式 | 地址 | 适合场景 |
|---|---|---|
loopback | 127.0.0.1 | 默认模式,仅本机访问 |
lan | 0.0.0.0 | 局域网访问 |
tailnet | Tailscale IP | 通过 Tailscale 安全访问 |
auto | 自动判断 | 根据环境选择地址 |
custom | 自定义地址 | 特殊网络环境 |
本地优先并不等于只能本地用。更常见的部署方式是 Gateway 跑在本机或小型 Linux 实例上,再通过 Tailscale Serve/Funnel、SSH 隧道或反向代理暴露给其他设备。
服务生命周期
macOS 上通常使用 launchd 管理 Gateway:
openclaw gateway install
openclaw gateway start
openclaw gateway stop
openclaw gateway restart
Linux 上可以使用 systemd:
openclaw gateway install
systemctl --user enable --now openclaw-gateway.service
常用排查命令:
# 启动网关
openclaw gateway --port 18789
# 查看状态
openclaw gateway status
openclaw gateway status --deep
# 健康检查
openclaw gateway health
openclaw channels status --probe
# 发现局域网网关
openclaw gateway discover
# 实时日志
openclaw logs --follow
配置热重载
Gateway 支持不同级别的配置重载:
| 模式 | 行为 |
|---|---|
off | 不自动重载 |
hot | 只应用安全的热更新 |
restart | 检测到需要重启的配置时自动重启 |
hybrid | 能热更新就热更新,必要时重启,默认模式 |
典型配置如下:
{
"gateway": {
"port": 18789,
"bind": "loopback",
"mode": "local",
"auth": {
"mode": "token",
"token": "your-token"
},
"tls": {
"enabled": true,
"certPath": "/path/to/cert.pem",
"keyPath": "/path/to/key.pem"
},
"reload": {
"mode": "hybrid",
"debounceMs": 300
}
}
}
对应源码位置可以按模块查:
| 模块 | 路径 |
|---|---|
| CLI(命令行接口)入口 | src/cli/gateway-cli/ |
| Gateway 客户端 | src/gateway/client.ts |
| 协议定义 | src/gateway/protocol/ |
| HTTP 服务端 | src/gateway/server-http.ts |
| Gateway 配置类型 | src/config/types.gateway.ts |
Pi Agent 与 Agentic Loop:Agent 的推理循环
Agentic Loop 是 OpenClaw 真正“思考和执行”的地方。大语言模型(LLM,Large Language Model)不是一次性生成最终回答,而是在一个循环里持续接收上下文、输出文本或工具调用、等待工具结果,再继续推理。
OpenClaw 的推理循环是事件驱动架构。整体流程如图所示:
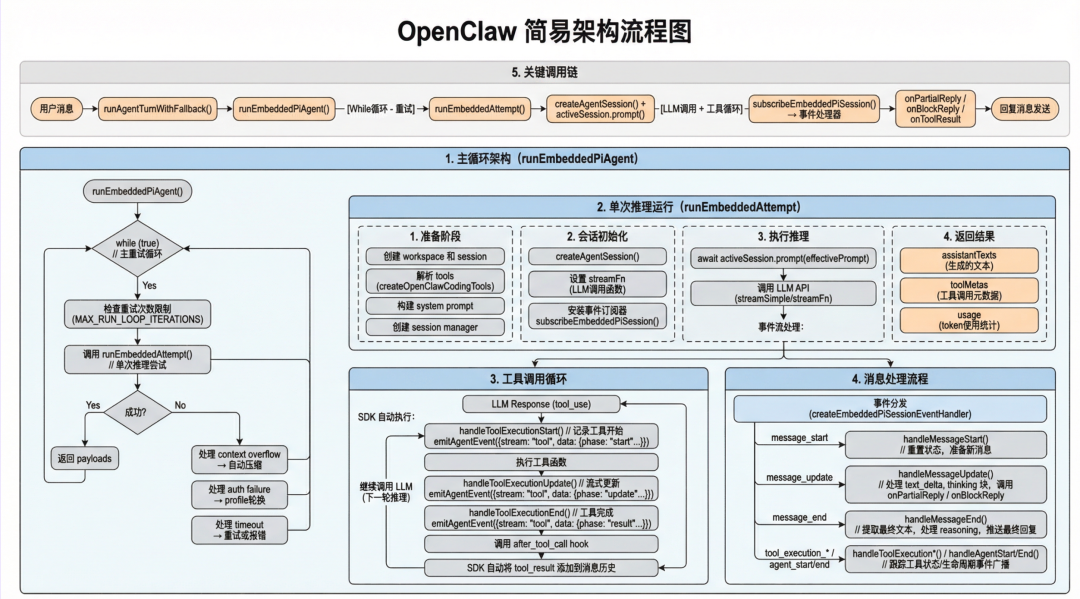
图中的核心是三层:
run.ts管主循环,负责重试、错误分类、上下文溢出处理和 profile 轮换。attempt.ts管单次推理尝试,负责创建会话、构建工具、注入系统提示词并启动模型调用。subscribe.ts管事件订阅,把模型流式输出、工具执行事件、Agent 生命周期事件转换成 OpenClaw 内部事件。
主循环:负责稳定性
主循环不是简单调用一次模型。它会用 while 循环包住一次推理尝试,并处理几类常见失败:
| 失败类型 | 处理方式 |
|---|---|
| 上下文溢出 | 触发自动压缩,再重新尝试 |
| 认证失败 | 尝试轮换 profile |
| 调用超时 | 按策略重试或返回错误 |
| 达到重试上限 | 停止运行并报告失败 |
可以用伪代码表示:
async function runEmbeddedPiAgent() {
while (true) {
if (exceedMaxLoopIterations()) {
throw new Error("too many run loop iterations");
}
try {
const result = await runEmbeddedAttempt();
return result.payloads;
} catch (err) {
if (isContextOverflow(err)) {
await compactSessionHistory();
continue;
}
if (isAuthFailure(err)) {
await rotateProfile();
continue;
}
if (isTimeout(err) && canRetry()) {
continue;
}
throw err;
}
}
}
这个结构让 Agent 在面对长会话、模型接口波动、上下文爆掉等问题时,不会轻易中断。
单次尝试:准备上下文、工具和会话
一次推理尝试大致分四步:
flowchart TD
A[准备阶段] --> B[初始化会话]
B --> C[执行推理]
C --> D[收集结果]
A --> A1[创建 workspace 和 session]
A --> A2[构建工具列表]
A --> A3[构建 system prompt]
A --> A4[创建 session manager]
B --> B1[createAgentSession]
B --> B2[设置 streamFn]
B --> B3[安装事件订阅器]
C --> C1[activeSession.prompt]
C1 --> C2[LLM 流式调用]
C2 --> C3[工具调用循环]
D --> D1[assistantTexts]
D --> D2[toolMetas]
D --> D3[usage tokens]
关键调用链可以压缩成这样:
用户消息
↓
runAgentTurnWithFallback()
↓
runEmbeddedPiAgent()
↓
runEmbeddedAttempt()
↓
createAgentSession() + activeSession.prompt()
↓
LLM 调用 + 工具循环
↓
subscribeEmbeddedPiSession()
↓
onPartialReply / onBlockReply / onToolResult
↓
回复投递
LLM 调用函数
OpenClaw 把模型调用抽象成 streamFn:
| 类型 | 说明 |
|---|---|
streamSimple | 默认流式调用函数,来自 @mariozechner/pi-ai |
createOllamaStreamFn() | 面向 Ollama 本地模型 |
applyExtraParamsToAgent() | 包装调用参数,例如添加额外模型参数 |
这样做可以让 Agentic Loop 不直接绑定某个模型供应商。只要能提供兼容的流式函数,就能接进推理循环。
工具调用循环
工具调用由底层 SDK(Software Development Kit,软件开发工具包)管理。当模型返回 tool_use 时,系统会执行工具,然后把 tool_result 写回消息历史,再继续调用模型。
sequenceDiagram
participant M as AI Model
participant SDK as Agent SDK
participant T as Tool
participant S as Subscriber
M-->>SDK: tool_use(name, args)
SDK-->>S: tool_execution_start
SDK->>T: execute(args)
T-->>SDK: streaming updates
SDK-->>S: tool_execution_update
T-->>SDK: result
SDK-->>S: tool_execution_end
SDK->>M: tool_result
M-->>SDK: 继续推理或生成最终回复
这套机制让 Agent 可以多轮调用工具。例如用户要求“查资料并生成报告”,模型可能先调用浏览器搜索,再调用文件写入工具保存草稿,最后生成回复。Agentic Loop 不需要提前知道会调用几次工具,而是由模型和工具结果共同驱动后续步骤。
流式事件处理
subscribeEmbeddedPiSession() 会订阅并分发各种事件:
| 事件 | 处理逻辑 |
|---|---|
message_start | 重置状态,准备接收新消息 |
message_update | 处理文本增量、thinking 块、局部回复 |
message_end | 提取最终文本,推送完整回复 |
tool_execution_start | 记录工具开始,广播工具事件 |
tool_execution_update | 处理工具流式进度 |
tool_execution_end | 处理工具结果,触发 after hook |
agent_start / agent_end | 广播 Agent 生命周期事件 |
这种设计把“模型输出文本”“工具正在执行”“工具已经返回”“Agent 结束”都变成统一事件。控制台、聊天渠道、日志系统、SubAgent 注册表都可以订阅这些事件。
Cron:定时任务系统
个人助手经常需要做后台任务,例如定时总结消息、每天早上生成计划、每隔一段时间检查服务状态、在某个时间提醒用户。Cron 系统负责把这些任务可靠地调度起来。
OpenClaw 的 CronService 由三部分组成:
flowchart TB
subgraph CronService
Timer[Timer 定时器]
Store[Store 持久化存储]
State[State 运行状态]
end
Timer --> Jobs[(jobs.json)]
Store --> Jobs
State --> Jobs
Timer --> Runner[Job Runner]
Runner --> Agent[Agent / Heartbeat]
Runner --> Webhook[Webhook 回调]
调度类型
Cron 支持三种调度模式:
type CronSchedule =
| { kind: "at"; at: string }
| { kind: "every"; everyMs: number; anchorMs?: number }
| { kind: "cron"; expr: string; tz?: string; staggerMs?: number };
| 模式 | 说明 | 适合场景 |
|---|---|---|
at | 指定时间执行一次,执行后自动禁用 | 明天 9 点提醒、某个时间点触发任务 |
every | 固定间隔执行 | 每 10 分钟检查状态 |
cron | 标准 Cron 表达式,支持时区和错峰 | 每天 8 点、每周一上午 |
staggerMs 用于错峰。多个任务如果集中在同一时间触发,可以通过 stagger 分散启动,避免瞬间把模型和工具调用打满。
单一定时器设计
CronService 不为每个任务维护一个 setTimeout,而是只维护一个全局定时器。每次根据所有任务的 nextRunAtMs 找到最近唤醒时间,到点后执行该执行的任务,再重新计算下一次唤醒。
const MAX_TIMER_DELAY_MS = 60_000;
const MIN_REFIRE_GAP_MS = 2_000;
export function armTimer(state: CronServiceState) {
const nextAt = nextWakeAtMs(state);
const delay = Math.max(nextAt - Date.now(), 0);
const clampedDelay = Math.min(delay, MAX_TIMER_DELAY_MS);
state.timer = setTimeout(() => {
void onTimer(state).catch((err) => {
state.logger.error(err);
});
}, clampedDelay);
}
两个常量很关键:
| 常量 | 含义 |
|---|---|
MAX_TIMER_DELAY_MS = 60_000 | 单次定时器最多等待 60 秒,减少系统休眠或时钟漂移带来的影响 |
MIN_REFIRE_GAP_MS = 2_000 | 最小重触发间隔,避免任务异常导致紧密循环 |
持久化与运行日志
任务默认存储在:
~/.openclaw/cron/jobs.json
任务运行日志存储在:
~/.openclaw/cron/runs/<jobId>.jsonl
JSONL(JSON Lines,一行一个 JSON 对象)适合记录连续运行日志,因为可以按行追加、裁剪和流式读取。
任务结构大致如下:
type CronStoreFile = {
version: 1;
jobs: CronJob[];
};
type CronJob = {
id: string;
name: string;
enabled: boolean;
schedule: CronSchedule;
sessionTarget: "main" | "isolated";
payload: CronPayload;
state: CronJobState;
};
持久化采用“临时文件 + rename”的原子写入方式。这样即使进程在写入过程中崩溃,也不容易留下半截 JSON 文件。
启动恢复
Gateway 重启后,CronService 会恢复任务状态:
flowchart TD
A[启动 CronService] --> B[加载 jobs.json]
B --> C[清理 runningAtMs 标记]
C --> D[运行错过的任务]
D --> E[重新计算 nextRunAtMs]
E --> F[启动全局定时器]
核心逻辑可以写成:
export async function start(state: CronServiceState) {
await ensureLoaded(state, { skipRecompute: true });
for (const job of state.jobs) {
if (job.state.runningAtMs) {
job.state.runningAtMs = undefined;
}
}
await runMissedJobs(state);
recomputeNextRuns(state);
armTimer(state);
}
这一步的意义是避免“任务正在运行”这种临时状态在进程崩溃后永久卡住。
两种执行模式
Cron 任务可以投递到主会话,也可以创建隔离 Agent 会话。
| 模式 | sessionTarget | 说明 |
|---|---|---|
| Main Session | main | 向主会话注入系统事件 |
| Isolated Agent | isolated | 启动独立 Agent 会话执行任务 |
主会话模式要求 payload 是系统事件:
{
"kind": "systemEvent",
"text": "现在生成今天的日程摘要"
}
隔离模式用于后台任务:
{
"kind": "agentTurn",
"message": "检查仓库中最近的错误日志,并生成摘要",
"model": "claude-sonnet-4",
"timeoutMs": 600000
}
隔离模式不会污染主会话上下文,适合长任务、周期巡检和后台分析。
超时、退避与并发控制
Cron 任务执行时会套一层超时控制:
export async function executeJobCoreWithTimeout(state, job) {
const abortController = new AbortController();
const jobTimeoutMs = resolveCronJobTimeoutMs(job);
return await Promise.race([
executeJobCore(state, job, abortController.signal),
new Promise((_, reject) => {
setTimeout(() => {
abortController.abort();
reject(new Error("cron: job execution timed out"));
}, jobTimeoutMs);
})
]);
}
失败后会按指数退避重试,例如:
30s → 1min → 5min → 15min → 60min
同时还有并发上限 maxConcurrentRuns,避免大量任务同时启动把模型调用、工具执行和本地资源打满。
与 Heartbeat 集成
Cron 可以和 Heartbeat 配合,让任务不是简单地“直接发消息”,而是唤醒 Agent 运行一次。
const cron = new CronService({
enqueueSystemEvent: (text, opts) => {
enqueueSystemEvent(text, {
sessionKey: opts.sessionKey,
contextKey: opts.contextKey
});
},
requestHeartbeatNow: (opts) => {
requestHeartbeatNow({
reason: opts.reason,
agentId: opts.agentId,
sessionKey: opts.sessionKey
});
},
runHeartbeatOnce: async (opts) => {
return await runHeartbeatOnce({
cfg,
reason: opts.reason,
agentId: opts.agentId,
sessionKey: opts.sessionKey
});
}
});
Wake 模式有两种:
| 模式 | 行为 |
|---|---|
next-heartbeat | 等待下一次心跳处理 |
now | 立即触发一次心跳 |
如果任务完成后需要通知外部系统,也可以配置 Webhook:
if (webhookTarget && evt.summary) {
await fetch(webhookTarget.url, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${webhookToken}`
},
body: JSON.stringify(evt)
});
}
常用命令:
openclaw cron status
openclaw cron list
openclaw cron add
openclaw cron edit
openclaw cron remove <id>
openclaw cron run <id>
Tools:让 Agent 真正执行动作
没有工具系统,Agent 只能生成文本。OpenClaw 的工具系统把文件读写、代码编辑、命令执行、浏览器控制、消息发送、记忆检索、画布操作、网关管理等能力统一包装成模型可以调用的工具。
工具系统可以分成六层:
flowchart TB
A[Tool Creation 创建层] --> B[Tool Definition 定义层]
B --> C[Schema Normalization 参数 Schema 规范化]
C --> D[Policy Pipeline 策略管道]
D --> E[Execution 执行层]
E --> F[Hook System 钩子]
A --> P[Plugin System 插件工具]
G[HTTP Invocation API] --> D
工具创建入口
createOpenClawCodingTools() 是工具系统主入口,负责把基础编码工具、OpenClaw 特定工具、插件工具合并起来,再经过策略过滤和 Schema 规范化。
伪代码如下:
function createOpenClawCodingTools() {
const policy = resolveEffectiveToolPolicy();
const coding = createBaseCodingTools();
const exec = createExecTool();
const openclaw = createOpenClawTools();
const plugins = resolvePluginTools();
const merged = [
...coding,
exec,
...openclaw,
...plugins
];
const filtered = applyToolPolicyPipeline(merged, policy);
const normalized = normalizeToolParameters(filtered);
return normalized.map(wrapToolWithBeforeToolCallHook);
}
常见工具可以按能力分类:
| 类型 | 示例 |
|---|---|
| 编码工具 | read、write、edit、bash |
| 浏览器工具 | 页面快照、点击、输入、上传、截图 |
| 消息工具 | 向指定渠道发送消息、回复、表情反应 |
| 记忆工具 | 搜索或写入长期记忆 |
| Gateway 工具 | 查询会话、状态、节点 |
| Canvas 工具 | 操作实时画布 |
| TTS 工具 | TTS(Text-to-Speech,文本转语音) |
| 进程工具 | 查看、启动、停止任务进程 |
工具定义
核心类型是 AnyAgentTool。一个工具至少需要名称、描述、参数 Schema 和执行函数:
type AnyAgentTool = {
name: string;
label?: string;
description: string;
parameters?: unknown;
execute?: (
id: string,
args: unknown,
signal: AbortSignal
) => Promise<unknown>;
ownerOnly?: boolean;
};
字段含义:
| 字段 | 作用 |
|---|---|
name | 工具名称,通常要求小写且唯一 |
label | 给 UI 展示的名称 |
description | 给模型看的工具说明,影响模型是否正确调用 |
parameters | JSON Schema(JavaScript Object Notation Schema,JSON 结构约束)或 TypeBox Schema |
execute | 实际执行函数 |
ownerOnly | 是否只允许所有者使用 |
工具描述非常关键。模型并不知道工具内部代码,只能根据名称、说明和参数 Schema 决定什么时候调用、怎么传参。
Schema 规范化
不同模型供应商对工具参数 Schema 的兼容程度不同。OpenClaw 在工具发送给模型前会做规范化:
| 提供商 | 处理方式 |
|---|---|
| Anthropic | 保留完整 JSON Schema draft 2020-12 兼容结构 |
| OpenAI | 确保顶层存在 type: "object" |
| Google/Gemini | 清理不支持的 format 或约束关键字 |
| 所有供应商 | 合并或转换 anyOf / oneOf 等 union schema |
如果不做这层适配,同一个工具在 Claude 上能用,在 Gemini 或 OpenAI 模型上可能会因为 Schema 不兼容而报错。
策略管道
工具能力越强,风险也越高。文件写入、命令执行、浏览器登录态、消息发送都可能造成真实影响,所以 OpenClaw 使用多级工具策略管道。
策略应用顺序为:
Profile Policy
→ Provider Profile Policy
→ Global Policy
→ Agent Policy
→ Group Policy
→ Sandbox Policy
→ Subagent Policy
策略配置结构:
type ToolPolicyConfig = {
allow?: string[];
alsoAllow?: string[];
deny?: string[];
profile?: "minimal" | "coding" | "messaging" | "full";
};
各字段含义:
| 字段 | 说明 |
|---|---|
allow | 白名单,只允许这些工具 |
alsoAllow | 在已有白名单基础上追加允许项 |
deny | 黑名单,明确禁止这些工具 |
profile | 预设工具集合,例如最小、编码、消息、完整 |
这种管道式策略可以表达很细的权限规则:
- 主会话可以使用
bash和文件编辑。 - 外部群聊只允许消息和搜索类工具。
- 沙箱会话禁止访问宿主机命令。
- 叶子 SubAgent 不能继续创建会话。
- 某个 Agent 只能使用浏览器,不能发消息。
工具调用完整流程
flowchart TD
A[用户消息进入 Gateway] --> B[构建工具列表]
B --> C[应用策略过滤]
C --> D[规范化参数 Schema]
D --> E[发送给 AI 模型]
E --> F{模型是否返回 tool_use}
F -- 否 --> G[生成文本回复]
F -- 是 --> H[before_tool_call 钩子]
H --> I{是否允许调用}
I -- 否 --> J[返回拒绝结果]
I -- 是 --> K[tool.execute 执行]
K --> L[after_tool_call 钩子]
L --> M[返回 tool_result]
M --> E
钩子系统分两类:
| 钩子 | 能做什么 |
|---|---|
before_tool_call | 修改参数、阻止调用、记录审计日志 |
after_tool_call | 记录结果、统计耗时、检测循环调用 |
工具执行事件还会被发送到流式事件系统,控制台或聊天界面可以实时显示“正在调用浏览器”“命令执行完成”等状态。
插件工具与 HTTP 调用
插件可以注册工具:
type PluginToolRegistration = {
pluginId: string;
factory: OpenClawPluginToolFactory;
names: string[];
optional: boolean;
source: string;
};
例如:
| 插件 | 工具 |
|---|---|
| Microsoft Teams | msteams-send、msteams-react |
| Matrix | matrix-send、matrix-react |
| Zalo | zalo-send |
| Voice Call | voice-call |
外部系统也可以通过 HTTP 调用工具:
POST /tools/invoke
Content-Type: application/json
Authorization: Bearer your-token
{
"tool": "browser",
"action": "screenshot",
"args": {
"url": "https://example.com"
},
"sessionKey": "agent:main"
}
这个入口仍然会经过认证和策略校验,不是绕过工具权限直接执行。
Channels:把 AI 接入聊天和协作平台
Channels 是 OpenClaw 与外部社交、办公平台连接的抽象层。它负责接收 Telegram、Discord、Slack、WhatsApp、Signal、iMessage、Microsoft Teams、Matrix、Zalo 等平台的消息,并把 Agent 回复投递回去。
ChannelPlugin 抽象
每个渠道都实现一个 ChannelPlugin,插件由元信息、能力描述和多个适配器组成。
flowchart TB
Plugin[ChannelPlugin]
Plugin --> Meta[meta: label / docsPath / aliases]
Plugin --> Cap[capabilities: chatTypes / polls / threads]
Plugin --> Config[config 账户配置]
Plugin --> Setup[setup 账户设置]
Plugin --> Outbound[outbound 消息发送]
Plugin --> Status[status 状态探测]
Plugin --> Gateway[gateway 生命周期]
Plugin --> Security[security 安全策略]
Plugin --> Pairing[pairing 配对]
Plugin --> Groups[groups 群组管理]
Plugin --> Threading[threading 线程处理]
Plugin --> Mentions[mentions 提及解析]
Plugin --> Directory[directory 目录查询]
Plugin --> Resolver[resolver 路由解析]
Plugin --> Actions[actions 消息动作]
把一个渠道拆成多个适配器,而不是写成一个巨大类,有两个好处:
- 某些平台不支持的能力可以不实现,例如有的平台没有线程。
- 路由、发送、配置、配对、安全可以单独演进,避免平台实现互相影响。
入站消息流
flowchart TD
A[外部平台消息] --> B[Channel Monitor 接收]
B --> C[去重和预处理]
C --> D[Allowlist 验证]
D --> E[resolveAgentRoute 路由解析]
E --> F[Session Key 构建]
F --> G[持久化会话元数据]
G --> H[Agent 处理消息]
H --> I[生成回复]
I --> J[Outbound Deliver]
J --> K[消息分块]
K --> L[Channel Outbound Adapter]
L --> M[外部平台]
关键是路由解析。OpenClaw 需要判断一条消息到底应该交给哪个 Agent、哪个会话。路由优先级可以按精确度排序:
| 优先级 | 匹配类型 |
|---|---|
| 1 | binding.peer,精确用户或群组 |
| 2 | binding.peer.parent,线程继承 |
| 3 | binding.guild + roles,服务器和角色 |
| 4 | binding.guild,服务器 |
| 5 | binding.team,团队 |
| 6 | binding.account,账号 |
| 7 | binding.channel,渠道 |
| 8 | default agent,默认 Agent |
Session Key 会把 Agent、主键、渠道、账号、会话对象拼在一起,例如:
{agentId}:{mainKey}:{channel}:{accountId}:{peerKind}:{peerId}
这样同一个用户在 Telegram 私聊、Discord 群组、Slack 频道里触发的会话可以完全隔离。
出站消息流
出站时不会直接把一段长文本塞给平台。不同平台有不同限制:
- Telegram、Discord、Slack 的单条消息长度不同。
- 有些平台支持线程,有些不支持。
- 有些平台支持图片、文件、投票、按钮。
- 有些平台需要回复特定消息或带 mention。
所以 OpenClaw 会经过 Outbound Deliver 和 chunker:
flowchart LR
Reply[Agent 回复] --> Deliver[Outbound Deliver]
Deliver --> Dock[ChannelDock 轻量元数据]
Deliver --> Chunker[消息分块]
Chunker --> Adapter[OutboundAdapter]
Adapter --> Platform[Telegram / Discord / Slack / WhatsApp]
ChannelDock 是轻量加载机制,只加载渠道的元数据、能力和发送配置,不必每次都加载完整插件实现。
Channel 生命周期
flowchart TD
A[注册阶段 registerChannel] --> B[初始化]
B --> B1[getChannelDock 轻量加载]
B --> B2[getChannelPlugin 完整加载]
B --> C[配置阶段]
C --> C1[resolveAccountId]
C --> C2[applyAccountConfig]
C --> D[运行阶段]
D --> D1[startAccount]
D --> D2[inbound handlers]
D --> D3[resolveAgentRoute]
D --> D4[outbound sendText/sendMedia]
D --> E[监控阶段]
E --> E1[probeAccount]
E --> E2[auditAccount]
E --> E3[checkReady]
适配器职责表
| 适配器 | 职责 |
|---|---|
config | 账户列表、账号解析、启停状态 |
setup | 账号初始化、配置校验 |
outbound | 发送文本、媒体、投票,编辑或删除消息 |
status | 探测账号状态,生成状态快照 |
gateway | 启动或停止账号连接,创建入站处理器 |
security | DM(Direct Message,私信)策略和安全警告 |
pairing | 配对码验证 |
groups | 群组 mention 策略、群组工具策略 |
threading | 线程回复模式、线程上下文 |
mentions | 提及解析和格式化 |
directory | 用户和群组目录查询 |
resolver | 自定义路由逻辑 |
actions | 消息动作,例如按钮或菜单 |
messaging | 消息元数据和格式化 |
目录结构可以按职责理解:
src/
├── channels/
│ ├── plugins/
│ │ ├── types.plugin.ts
│ │ ├── types.adapters.ts
│ │ ├── types.core.ts
│ │ └── registry-loader.ts
│ ├── dock.ts
│ ├── registry.ts
│ ├── allow-from.ts
│ ├── channel-config.ts
│ └── session.ts
├── routing/
│ ├── resolve-route.ts
│ ├── bindings.ts
│ └── session-key.ts
├── telegram/
├── discord/
├── slack/
├── signal/
├── imessage/
├── web/
├── infra/outbound/
└── plugins/
extensions/
├── msteams/
├── matrix/
├── zalo/
└── voice-call/
安全隔离
Channels 直接面对外部输入,所以安全策略不能只依赖模型判断。常见控制包括:
| 机制 | 作用 |
|---|---|
| Allowlist | 限定哪些用户、群组、账号可以触发 Agent |
| Mention gating | 群聊里只有提及机器人时才响应 |
| DM pairing | 未知私信用户必须通过配对码 |
| Group policy | 群组级工具策略 |
| Sandbox policy | 外部会话放入沙箱,限制本地能力 |
这样可以避免陌生人通过聊天平台让 Agent 执行本地命令、读取文件或访问带登录态的浏览器。
Context:上下文窗口、压缩与剪枝
Context 指一次模型调用时发送给模型的所有内容。它包括系统提示词、工具描述、会话历史、工作区文件、运行时状态、Skills 元数据等。Context 受模型上下文窗口限制。
上下文构成可以通过这张图理解:

图中的重点是:Context 不是 Memory。Memory 是持久化记忆,可以长期存储在磁盘或数据库里;Context 是当前模型窗口中真正发送给模型的内容。模型只能基于窗口里的内容直接推理。
上下文窗口解析
OpenClaw 会按优先级确定当前模型可用的上下文窗口:
| 优先级 | 来源 |
|---|---|
| 1 | 显式覆盖 contextTokensOverride |
| 2 | context1m: true,Anthropic 1M 模型使用 1,048,576 tokens |
| 3 | 模型注册表,例如 models.json 或 provider catalog |
| 4 | 配置文件覆盖 models.providers.*.models[].contextWindow |
| 5 | 默认值 |
上下文窗口守卫会做两级判断:
const CONTEXT_WINDOW_HARD_MIN_TOKENS = 16_000;
const CONTEXT_WINDOW_WARN_BELOW_TOKENS = 32_000;
| 结果 | 条件 | 含义 |
|---|---|---|
shouldWarn | 小于 32K tokens | 可以运行,但复杂任务容易出问题 |
shouldBlock | 小于 16K tokens | 阻断运行,窗口太小 |
| 来源标记 | model / modelsConfig / agentContextTokens / default | 标识窗口值来自哪里 |
自动压缩 Compaction
长会话迟早会超过上下文窗口。OpenClaw 的 Compaction 会把旧消息交给模型总结,再把摘要写入历史。
flowchart LR
Old[旧消息历史] --> Estimate[估算 token]
Estimate --> Chunk[按预算分块]
Chunk --> Summarize[LLM 总结]
Summarize --> Entry[紧凑摘要条目]
Entry --> Store[(JSONL 持久化)]
Store --> NewContext[新上下文]
核心步骤:
| 步骤 | 函数 |
|---|---|
| Token 估算 | estimateMessagesTokens |
| 分块 | chunkMessagesByMaxTokens |
| 摘要生成 | summarizeWithFallback |
| 历史裁剪 | pruneHistoryForContextShare |
自适应分块参数:
const BASE_CHUNK_RATIO = 0.4;
const MIN_CHUNK_RATIO = 0.15;
const SAFETY_MARGIN = 1.2;
如果单条消息非常大,例如一段巨大的日志或工具输出,占了上下文窗口的 50% 以上,就无法安全地直接总结:
isOversizedForSummary(message, contextWindow);
处理策略通常是:
- 尝试完整压缩。
- 如果失败,只压缩较小消息,并记录过大消息。
- 如果仍失败,回退为消息计数说明,避免整个会话崩掉。
剪枝 Pruning
Compaction 和 Pruning 容易混淆。它们解决的问题不同:
| 特性 | Compaction | Pruning |
|---|---|---|
| 作用范围 | 整个历史 | |
| 主要对象 | 用户消息、助手消息、工具结果等 | |
| 持久化 | 写入 JSONL | |
| 触发时机 | 接近上下文窗口上限 | |
| 内容变化 | 生成摘要 | |
| Pruning 作用范围 | 仅 toolResult 消息 | |
| Pruning 持久化 | 只改内存中的上下文 | |
| Pruning 触发时机 | 每次请求前,TTL 过期后检查 | |
| Pruning 内容变化 | 软修剪或硬清除 |
默认剪枝配置:
const DEFAULT_CONTEXT_PRUNING_SETTINGS = {
mode: "cache-ttl",
ttlMs: 5 * 60 * 1000,
keepLastAssistants: 3,
softTrimRatio: 0.3,
hardClearRatio: 0.5,
minPrunableToolChars: 50_000,
softTrim: {
maxChars: 4_000,
headChars: 1_500,
tailChars: 1_500
},
hardClear: {
enabled: true,
placeholder: "[Old tool result content cleared]"
}
};
剪枝流程:
flowchart TD
A[请求前检查] --> B{TTL 是否过期}
B -- 否 --> Z[不处理]
B -- 是 --> C[计算上下文占用比例]
C --> D{超过 softTrimRatio}
D -- 否 --> Z
D -- 是 --> E[软修剪工具结果,保留头尾]
E --> F{仍超过 hardClearRatio}
F -- 否 --> Z
F -- 是 --> G[硬清除旧工具结果,替换占位符]
保护机制包括:
- 不修改用户消息和助手消息。
- 跳过包含图片的工具结果。
- 保护 bootstrap 阶段消息。
- 保护最近 N 条助手消息之后的工具结果。
工具结果上下文守卫
工具结果特别容易撑爆上下文,例如网页快照、日志、代码搜索结果、命令输出。OpenClaw 对单条工具结果和总预算都做限制:
const SINGLE_TOOL_RESULT_CONTEXT_SHARE = 0.5;
const TOOL_RESULT_CHARS_PER_TOKEN_ESTIMATE = 2;
执行逻辑可以理解为:
const maxSingleToolResultChars =
contextWindowTokens * 2 * 0.5;
const contextBudgetChars =
contextWindowTokens * 4 * 0.75;
// 超预算时压缩最旧工具结果
当旧工具结果被压缩时,会替换为类似占位符:
[compacted: tool output removed to free context]
这比无节制保留工具输出更可靠。模型如果确实需要旧内容,可以重新调用工具读取更小范围的数据。
运行时上下文注入
OpenClaw 会从工作区读取一些约定文件,注入到上下文中:
| 文件 | 作用 |
|---|---|
AGENTS.md | 项目规则 |
SOUL.md | 角色定义 |
TOOLS.md | 工具使用说明 |
IDENTITY.md | 身份信息 |
USER.md | 用户偏好 |
HEARTBEAT.md | 心跳状态 |
BOOTSTRAP.md | 首次运行引导 |
默认截断配置:
{
"agents": {
"defaults": {
"bootstrapMaxChars": 20000,
"bootstrapTotalMaxChars": 150000
}
}
}
压缩完成后,系统会重新注入 AGENTS.md 里的关键章节,例如:
## Session Startup## Red Lines
这是为了避免压缩把关键规则折叠掉,导致后续模型运行忘记启动规则或安全红线。
Sandbox 上下文
沙箱会话会额外注入容器信息:
| 信息 | 示例 |
|---|---|
| 容器名称 | containerName |
| 容器工作目录 | containerWorkdir |
| 工作区映射 | workspaceDir、agentWorkspaceDir |
| Docker 配置 | docker |
| 工具权限 | tools |
| 浏览器桥接 | browser、fsBridge |
这样模型知道自己处在容器里,文件路径和工具权限也不会和宿主机混淆。
调试命令
| 命令 | 作用 |
|---|---|
/status | 查看上下文窗口占用率和会话设置 |
/context list | 查看注入文件大小、工具 Schema 大小 |
/context detail | 展开上下文组成 |
/usage tokens | 显示每次回复的 token 使用量 |
/compact | 手动触发压缩 |
典型配置:
{
"agents": {
"defaults": {
"contextTokens": 200000,
"bootstrapMaxChars": 20000,
"bootstrapTotalMaxChars": 150000,
"compaction": {
"mode": "auto",
"targetTokens": 0.7
},
"contextPruning": {
"mode": "cache-ttl",
"ttl": "5m",
"keepLastAssistants": 3,
"softTrimRatio": 0.3,
"hardClearRatio": 0.5
}
}
},
"models": {
"providers": {
"anthropic": {
"models": [
{
"id": "claude-sonnet-4",
"contextWindow": 200000
}
]
}
}
}
}
SubAgent:后台并行任务与多智能体编排
SubAgent 是从当前 Agent 会话中派生出来的后台独立运行实例。它适合处理并行研究、长任务、复杂项目拆分和多层任务编排。
它有四个关键特征:
| 特征 | 说明 |
|---|---|
| 会话隔离 | 每个 SubAgent 有独立 session key、上下文和工具策略 |
| 后台执行 | 派生后非阻塞运行,主会话可以继续工作 |
| 结果通告 | 完成后自动把结果摘要推回请求者 |
| 嵌套支持 | 可以允许 SubAgent 再派生 SubAgent,但有深度限制 |
会话键和深度
SubAgent 的会话键表达了层级关系:
| 深度 | 会话键格式 | 角色 | 是否可继续派生 |
|---|---|---|---|
| 0 | agent:<id>:main | 主智能体 | 可以 |
| 1 | agent:<id>:subagent:<uuid> | 编排者子智能体 | 取决于 maxSpawnDepth |
| 2 | agent:<id>:subagent:<uuid>:subagent:<uuid> | 叶子工作者 | 通常不允许 |
深度计算不只靠字符串解析,还会结合会话存储里的 spawnDepth 和 spawnedBy 链:
export function getSubagentDepthFromSessionStore(
sessionKey: string | undefined | null,
opts?: {
cfg?: OpenClawConfig;
store?: Record<string, SessionDepthEntry>;
}
): number {
const fallbackDepth = getSubagentDepth(sessionKey);
const entry = loadSessionEntry(sessionKey);
const storedDepth = normalizeSpawnDepth(entry?.spawnDepth);
if (storedDepth !== undefined) {
return storedDepth;
}
const parentDepth = depthFromStore(entry?.spawnedBy);
return parentDepth + 1 || fallbackDepth;
}
运行注册表
SubAgent 运行记录会进入注册表。注册表用于跟踪活跃运行、恢复未完成任务、清理孤儿运行和级联停止。
type SubagentRunRecord = {
runId: string;
childSessionKey: string;
requesterSessionKey: string;
requesterOrigin?: DeliveryContext;
task: string;
cleanup: "delete" | "keep";
label?: string;
model?: string;
runTimeoutSeconds?: number;
spawnMode?: SpawnSubagentMode;
createdAt: number;
startedAt?: number;
endedAt?: number;
outcome?: SubagentRunOutcome;
suppressAnnounceReason?: "steer-restart" | "killed";
endedReason?: SubagentLifecycleEndedReason;
};
注册表职责:
| 职责 | 说明 |
|---|---|
| 运行跟踪 | 记录活跃和历史 SubAgent |
| 生命周期监听 | 监听 agent_start、agent_end、error 等事件 |
| 持久化 | 写入磁盘,Gateway 重启后可恢复 |
| 级联停止 | 父运行停止时停止子运行 |
| 孤儿检测 | 会话缺失时清理异常记录 |
恢复流程:
flowchart TD
A[Gateway 启动] --> B[从磁盘恢复 SubAgent 运行记录]
B --> C[合并到内存注册表]
C --> D[检查孤儿运行]
D --> E[持久化修正结果]
E --> F[恢复未完成运行]
派生流程
SubAgent 派生不是简单创建一个新对话。它需要权限检查、会话创建、线程绑定、启动运行、注册记录和钩子通知。
flowchart TD
A[调用 sessions_spawn] --> B[权限和深度检查]
B --> C{是否允许}
C -- 否 --> X[返回拒绝]
C -- 是 --> D[创建子会话]
D --> E[写入 spawnDepth / spawnedBy]
E --> F[可选线程绑定]
F --> G[构建子智能体系统提示]
G --> H[gateway.agent 启动运行]
H --> I[注册 SubAgent 运行记录]
I --> J[触发 subagent_spawned 钩子]
J --> K[后台等待完成]
检查项包括:
| 检查 | 目的 |
|---|---|
调用者深度 < maxSpawnDepth | 防止无限递归派生 |
活跃子运行数 < maxChildrenPerAgent | 防止单会话创建过多后台任务 |
全局并发 < maxConcurrent | 控制系统总负载 |
agentId 允许列表 | 限定可以派生哪些 Agent |
| 工具策略 | 限定子智能体可用工具 |
子智能体系统提示
SubAgent 会得到专门的系统提示,强调它的任务边界:
function buildSubagentSystemPrompt(params: {
requesterSessionKey?: string;
childSessionKey: string;
label?: string;
task?: string;
childDepth?: number;
maxSpawnDepth?: number;
}) {
const canSpawn = params.childDepth < params.maxSpawnDepth;
const lines = [
"# Subagent Context",
"You are a subagent spawned for a specific task.",
"",
"## Your Role",
`- You were created to handle: ${params.task}`,
"- Complete this task. That's your entire purpose.",
"",
"## Rules",
"1. Stay focused.",
"2. Complete the task.",
"3. Don't initiate unrelated actions.",
"4. Be ephemeral.",
"5. Trust push-based completion.",
"6. Re-read with smaller chunks if tool output was compacted."
];
if (canSpawn) {
lines.push(
"## Sub-Agent Spawning",
"You CAN spawn your own sub-agents using sessions_spawn.",
"Use the subagents tool to steer, kill, or check status."
);
} else {
lines.push(
"## Sub-Agent Spawning",
"You are a leaf worker and CANNOT spawn further sub-agents."
);
}
return lines.join("\n");
}
这个提示的重点是把 SubAgent 限制在具体任务内。主 Agent 可以做开放式对话,SubAgent 更像一个后台 worker。
结果通告
SubAgent 完成后不会像函数调用一样同步返回结果,而是通过通告机制把结果推回请求者。
flowchart TD
A[等待 SubAgent 结束] --> B[读取最新助手回复或工具结果]
B --> C[构建通告消息]
C --> D[统计耗时 / token / 成本]
D --> E[确定投递目标]
E --> E1[线程绑定]
E --> E2[delivery target 钩子]
E --> E3[请求者来源回退]
E1 --> F[投递通告]
E2 --> F
E3 --> F
F --> G{请求者是否忙}
G -- 是 --> H[入队或 steer]
G -- 否 --> I[直接投递]
H --> J[清理或保留子会话]
I --> J
如果父 SubAgent 已经结束,通告会继续向上冒泡,直到找到仍可投递的祖先会话或原始渠道。
这种“推式通知”比轮询简单。主会话不需要不断问“子任务完成了吗”,只要等待结果通告即可。
SubAgent 管理工具
subagents 工具提供三个动作:
| 动作 | 说明 |
|---|---|
list | 列出活跃和最近的子运行 |
kill <target> | 停止指定子运行,支持级联停止 |
steer <target> <message> | 向运行中的子智能体发送指导消息 |
权限模型和深度有关:
function resolveRequesterKey(params: {
cfg: OpenClawConfig;
agentSessionKey?: string;
}) {
const callerSessionKey = resolveInternalSessionKey(params.agentSessionKey);
if (!isSubagentSessionKey(callerSessionKey)) {
return {
requesterSessionKey: callerSessionKey,
callerIsSubagent: false
};
}
const callerDepth = getSubagentDepthFromSessionStore(callerSessionKey);
const maxSpawnDepth =
params.cfg.agents?.defaults?.subagents?.maxSpawnDepth ?? 1;
if (callerDepth < maxSpawnDepth) {
return {
requesterSessionKey: callerSessionKey,
callerIsSubagent: true
};
}
const spawnedBy = loadSessionEntry(callerSessionKey)?.spawnedBy;
return {
requesterSessionKey: spawnedBy || callerSessionKey,
callerIsSubagent: true
};
}
叶子 SubAgent 通常不能管理自己的子任务,因为它不应该再派生任务。编排者 SubAgent 可以查看和控制自己派生的子运行。
级联停止会递归停止子运行和孙运行:
async function cascadeKillChildren(params: {
parentChildSessionKey: string;
}) {
const childRuns = listSubagentRunsForRequester(
params.parentChildSessionKey
);
let killed = 0;
for (const run of childRuns) {
if (!run.endedAt) {
const result = await killSubagentRun(run);
if (result.killed) {
killed += 1;
}
}
const cascade = await cascadeKillChildren({
parentChildSessionKey: run.childSessionKey
});
killed += cascade.killed;
}
return { killed };
}
配置和限制
典型配置如下:
{
agents: {
defaults: {
subagents: {
maxSpawnDepth: 2,
maxChildrenPerAgent: 5,
maxConcurrent: 8,
runTimeoutSeconds: 900,
archiveAfterMinutes: 60,
model: "claude-3-haiku",
thinking: "medium"
}
},
list: [
{
agentId: "orchestrator",
subagents: {
allowAgents: ["*"]
}
}
]
},
tools: {
subagents: {
tools: {
deny: ["gateway", "cron"],
allow: ["read", "exec"]
}
}
}
}
配置项含义:
| 配置 | 说明 |
|---|---|
maxSpawnDepth | 最大派生深度,防止无限嵌套 |
maxChildrenPerAgent | 单个会话最多活跃子运行数 |
maxConcurrent | 全局 SubAgent 并发上限 |
runTimeoutSeconds | 子运行超时时间 |
archiveAfterMinutes | 运行记录归档时间 |
model | 子智能体默认模型 |
thinking | 默认思考级别 |
allowAgents | 允许派生的目标 Agent |
默认工具策略通常是:
| 角色 | 工具策略 |
|---|---|
| 主智能体 | 可以使用 sessions_spawn 派生子智能体 |
| 深度 1 编排者 | 在允许时可用 sessions_spawn、subagents、sessions_list、sessions_history |
| 深度 2 叶子工作者 | 禁止继续派生,专注完成任务 |
插件钩子
SubAgent 生命周期提供插件钩子:
| 钩子 | 触发时机 | 用途 |
|---|---|---|
subagent_spawning | 派生前 | 准备线程绑定、验证权限 |
subagent_spawned | 派生成功后 | 记录日志、更新 UI |
subagent_delivery_target | 投递通告前 | 自定义通告路由 |
subagent_ended | 运行结束 | 清理资源 |
Discord 扩展可以用钩子为 SubAgent 创建专用线程:
export function registerDiscordSubagentHooks() {
const hookRunner = getGlobalHookRunner();
hookRunner.register("subagent_spawning", async (event) => {
const thread = await createDiscordThread({
channelId: event.requester.to,
name: `Subagent: ${event.label || event.agentId}`
});
return {
status: "ok",
threadBindingReady: true,
threadId: thread.id
};
});
hookRunner.register("subagent_delivery_target", async (event) => {
const binding = getThreadBinding(event.childSessionKey);
if (binding) {
return {
origin: {
channel: "discord",
to: binding.channelId,
threadId: binding.threadId
}
};
}
return {
origin: event.requesterOrigin
};
});
}
这种扩展方式让 SubAgent 可以在 Discord、Slack 等支持线程的平台里拥有独立讨论空间。
并发 Lane 和队列
OpenClaw 用 Lane 区分不同类型任务:
export const enum CommandLane {
Main = "main",
Cron = "cron",
Subagent = "subagent",
Nested = "nested"
}
SubAgent 使用专属 Subagent lane。这样主会话、Cron 任务和 SubAgent 后台任务可以分别限流,不会互相完全抢占。
当请求者会话正忙时,SubAgent 通告可能不会立即插入,而是进入队列:
async function maybeQueueSubagentAnnounce(params) {
const queueSettings = resolveQueueSettings(params);
const isActive = isEmbeddedPiRunActive(params.sessionId);
if (queueSettings.mode === "steer") {
const steered = queueEmbeddedPiMessage(
params.sessionId,
params.triggerMessage
);
if (steered) {
return "steered";
}
}
if (isActive && queueSettings.mode === "followup") {
enqueueAnnounce({
key: buildAnnounceQueueKey(params.sessionKey, params.origin),
item: params.announce,
settings: queueSettings,
send: sendAnnounce
});
return "queued";
}
return "none";
}
常见队列模式:
| 模式 | 行为 |
|---|---|
steer | 尝试把通告作为指导消息注入正在运行的会话 |
followup | 当前运行结束后追加一次后续消息 |
collect | 收集多条通告后统一处理 |
interrupt | 中断当前流程并处理通告 |
steer-backlog | 优先 steer,失败后进入积压队列 |
典型使用方式
并行研究:
用户:研究 A、B、C 三个主题并生成报告
主智能体:
- sessions_spawn(task: "研究主题 A", label: "research-a")
- sessions_spawn(task: "研究主题 B", label: "research-b")
- sessions_spawn(task: "研究主题 C", label: "research-c")
research-a 完成后通告结果
research-b 完成后通告结果
research-c 完成后通告结果
主智能体汇总三个结果,生成最终报告
编排者模式:
用户:重构这个大型项目
主智能体:
- sessions_spawn(
task: "协调重构工作",
agentId: "orchestrator",
label: "refactor-coordinator"
)
refactor-coordinator:
- sessions_spawn(task: "重构模块 A", label: "worker-a")
- sessions_spawn(task: "重构模块 B", label: "worker-b")
- sessions_spawn(task: "重构模块 C", label: "worker-c")
worker-a / worker-b / worker-c 完成后通告给 refactor-coordinator
refactor-coordinator 汇总后通告主智能体
主智能体向用户报告完成情况
线程绑定会话:
用户在 Discord 线程中:监控这个服务的性能
主智能体:
- sessions_spawn(
task: "启动性能监控",
thread: true,
mode: "session"
)
Discord 扩展创建专用线程
子智能体在该线程中持续运行
用户:当前状态如何?
消息路由到绑定的子智能体会话
用户:/unfocus
解除线程绑定,后续消息回到主智能体
设计取舍与容易踩坑的点
OpenClaw 这套架构很强,但也有明确代价。理解这些边界,比单纯记住模块名更重要。
| 设计 | 好处 | 代价 |
|---|---|---|
| Gateway 单控制平面 | 接入统一,状态集中,便于多端联动 | Gateway 需要稳定运行,故障会影响整体控制面 |
| WebSocket RPC | 适合双向事件流和实时状态 | 协议版本、认证和断线恢复要设计清楚 |
| 工具策略管道 | 可以精细控制不同来源的工具权限 | 策略层级多,排查“为什么工具不可用”需要看完整链路 |
| 自动上下文压缩 | 长会话可持续运行 | 摘要会丢细节,关键规则需要重新注入 |
| 工具结果剪枝 | 防止大输出撑爆窗口 | 模型可能需要重新读取旧工具输出 |
| SubAgent 推式通告 | 后台任务无需轮询,适合并行处理 | 通告路由、队列和父子会话生命周期要处理好 |
| Channel 插件化 | 新增渠道成本低,平台差异可隔离 | 每个平台的消息限制、线程、mention、权限模型都要单独适配 |
| Sandbox 隔离 | 外部输入更安全 | 文件路径、浏览器桥接、工具权限会更复杂 |
实际部署或二次开发时,优先检查这些点:
- Gateway 暴露到网络时必须开启认证和 TLS(Transport Layer Security,传输层安全协议),不要把本地控制面裸露到公网。
- 外部渠道默认使用更严格工具策略,尤其是群聊和未知私信。
- 为长任务配置超时和并发上限,Cron 与 SubAgent 都可能持续消耗模型和本地资源。
- 观察上下文占用率,工具输出和注入文件过大时,优先调剪枝和压缩配置。
- SubAgent 不要无限嵌套,一般深度 1 或 2 已经能覆盖并行研究和编排者模式。
- 插件渠道要实现状态探测和去重,消息平台经常重放 webhook 或断线重连。
OpenClaw 的核心不是某个单点能力,而是把 Agent 运行所需的控制面、推理循环、工具执行、上下文预算、外部渠道和后台子任务组合到一起。Gateway 负责“连接和调度”,Agentic Loop 负责“思考和工具循环”,Tools 负责“执行真实动作”,Context 负责“让模型在窗口内保持连续性”,SubAgent 负责“把复杂任务拆出去并行完成”。这几个部分配合起来,才构成一个能接入真实工作流的个人 AI 助手系统。