OpenClaw 这类 Agent 工具能完成代码生成、资料查询、自动化执行、文档整理等任务,但有一个问题很容易暴露出来:对话窗口里的上下文不是长期资产。
一次复杂的部署可能花了两个小时,中间经历了环境变量配置、依赖版本冲突、权限问题、服务启动失败、回滚与验证。当前对话里,Agent 能根据这些上下文继续推进;换一个新会话后,很多经验又要重新解释。
MemOS 要解决的正是这个问题:把 OpenClaw 与用户交互过程中产生的有效经验沉淀下来,变成长期记忆、任务摘要和可复用技能。这样 Agent 不只是“这次会做”,而是能在后续相似任务中直接复用过去的方法。
它提供了几个核心能力:
| 能力 | 解决的问题 |
|---|---|
| 长期记忆 | 保存用户偏好、项目背景、历史调试经验,避免每次重新说明 |
| 技能沉淀 | 把多轮对话中的成功流程整理成 SKILL.md、脚本和验证步骤 |
| 团队记忆 Hub | 多个 Agent 之间按权限共享经验,同时保留各自私有记忆 |
| 本地存储 | 敏感代码、密钥、内部架构等数据可以只留在本机 |
| Memory Viewer | 用网页面板检索、编辑、迁移和分析记忆 |
| 混合检索 | 结合全文检索和向量检索,提高记忆召回质量 |
OpenClaw 为什么需要长期记忆
大模型本身没有真正意义上的“永久记忆”。它能利用的是当前输入里的上下文,或者外部系统额外注入的资料。
如果只依赖对话上下文,实际使用中会遇到几个问题:
-
上下文窗口有限
一次任务持续时间越长,历史信息越多,越容易被截断或压缩。 -
重复解释成本高
项目结构、编码规范、部署环境、常用命令、禁用方案,每次新会话都要重新输入。 -
经验难以复用
Agent 成功解决过一次问题,但没有被沉淀成结构化资产,下次遇到类似场景仍然可能从头试错。 -
多 Agent 协作时信息不一致
写代码的 Agent 知道某个依赖版本有坑,写文档的 Agent 或自动化 Agent 未必知道。
MemOS 的设计思路不是把所有对话原样塞进数据库,而是把对话中的有效信息拆成不同类型的资产:记忆、任务、技能和团队知识。
flowchart LR
A[OpenClaw 对话与工具调用] --> B[MemOS 采集上下文]
B --> C[结构化任务摘要]
B --> D[长期记忆]
C --> E[可复用 Skill]
D --> F[检索与上下文注入]
E --> F
F --> G[OpenClaw 后续任务复用]
这里的关键点是“筛选”和“结构化”。长期记忆系统如果只是无限追加聊天记录,很快会变成噪声仓库;只有把目标、步骤、失败原因、成功配置和验证方式整理出来,后续检索时才有价值。
从一次调试到一个可复用 Skill
MemOS 比普通记忆插件更进一步的地方,在于它会尝试把一段成功经验沉淀成技能。
假设 OpenClaw 帮你完成了一次项目部署。过程中可能经历了这些信息:
- 项目使用什么技术栈;
- 部署目标是本机、云服务器还是容器环境;
- 哪些依赖版本不兼容;
- 哪些环境变量必须配置;
- 哪个启动命令最终可用;
- 如何检查服务是否真正启动成功;
- 遇到某个错误时应该怎么修。
如果这些内容只保存在聊天记录里,下次复用时仍然要靠检索片段再推理。MemOS 会进一步判断:这个流程是否足够稳定、是否有复用价值、是否可以变成标准操作。
一个可复用 Skill 通常包含三类内容:
| 组成部分 | 作用 |
|---|---|
SKILL.md | 描述技能的适用场景、输入要求、执行步骤和注意事项 |
| 执行脚本 | 把重复操作变成可调用命令,减少手工复制粘贴 |
| 验证检查 | 确认任务是否完成,例如端口检查、接口探活、日志关键字检查 |
技能沉淀的大致流程如下:
flowchart TD
A[完成一次复杂任务] --> B[提取目标、环境、步骤、问题和解决方案]
B --> C{是否适合复用}
C -- 否 --> D[保存为普通任务摘要和记忆]
C -- 是 --> E[生成 SKILL.md]
E --> F[生成脚本与验证检查]
F --> G[注册为 OpenClaw 可调用 Skill]
G --> H[后续相似任务直接调用]
H --> I[根据新结果迭代 Skill]
这种设计适合处理那些“不是一次性问答,而是一套可重复流程”的任务,例如:
- 初始化某类项目;
- 部署固定技术栈;
- 排查常见 CI(持续集成)失败;
- 生成标准 PR(Pull Request)说明;
- 按团队规范重构代码;
- 将接口文档同步到指定格式。
如果后续发现更稳的命令、更快的检查方式或新的兼容性问题,Skill 也可以继续更新,而不是永远停留在第一次成功的版本。
多 Agent 协作时,记忆要能隔离也要能共享
单个 Agent 有长期记忆已经能减少重复输入;当 OpenClaw 被用于多 Agent 协作时,记忆系统还需要解决另一个问题:哪些信息应该共享,哪些信息必须隔离。
一个典型的 Agent 团队可能长这样:
flowchart LR
U[用户] --> A[代码 Agent]
U --> B[资料 Agent]
U --> C[自动化 Agent]
U --> D[文档 Agent]
A --> H[(MemOS Hub)]
B --> H
C --> H
D --> H
A --> PA[(代码 Agent 私有记忆)]
B --> PB[(资料 Agent 私有记忆)]
C --> PC[(自动化 Agent 私有记忆)]
D --> PD[(文档 Agent 私有记忆)]
MemOS 的 Hub 可以理解为团队记忆中心。每个 Agent 仍然有自己的私有记忆,避免不同角色之间互相污染;被标记为共享的经验,则进入团队知识中枢。
这种隔离与共享的组合很重要。
| 记忆类型 | 例子 | 是否适合共享 |
|---|---|---|
| 私有记忆 | 某个 Agent 的临时推理过程、未验证猜测、角色专属偏好 | 通常不共享 |
| 项目事实 | 仓库结构、服务端口、部署环境、依赖版本 | 适合共享 |
| 调试经验 | 某个错误日志对应的修复方式 | 适合共享 |
| 标准流程 | 发布步骤、测试命令、PR 模板 | 适合共享 |
| 敏感信息 | 密钥、内部地址、账号凭据 | 应谨慎处理,默认不共享 |
共享之后,一个 Agent 踩过的坑,不需要其他 Agent 再踩一次。例如代码 Agent 发现某个依赖版本不能升级,文档 Agent 在生成升级说明时就能引用这个结论;自动化 Agent 编写部署脚本时,也能避开同样的问题。
本地存储:敏感数据不必离开机器
Agent 任务经常涉及敏感信息,例如:
- 业务代码;
- 数据库连接串;
- API Key;
- 内部服务地址;
- 私有部署架构;
- 调试日志中的用户数据。
如果长期记忆全部上传到云端,很多团队不会放心。MemOS 本地版把数据保存在用户机器上,默认位置是:
~/.openclaw/memos-local/memos.db
这是一个 SQLite 数据库文件。SQLite 是嵌入式关系型数据库,不需要单独启动数据库服务,文件本身就可以承载数据存储。
本地版的几个特点:
| 特性 | 说明 |
|---|---|
| 本地 SQLite 存储 | 记忆数据保存在本机文件中,便于备份和审计 |
| 无遥测 | 不主动收集使用数据 |
| 无第三方追踪 | 不依赖外部追踪服务 |
| 可离线运行 | 内置本地 Embedding 模型,不配置 API Key 也能跑 |
| 适合私有部署 | 可放在私有服务器、低配云主机或边缘设备上运行 |
如果有多设备同步、团队远程共享等需求,也可以选择云端版本。两种形态都适合不同场景:
| 版本 | 适合场景 | 主要代价 |
|---|---|---|
| 本地版 | 单机开发、敏感项目、离线环境、私有服务器 | 多设备同步需要自行处理 |
| 云端版 | 多设备使用、团队协作、远程访问 | 需要评估数据合规和访问权限 |
Memory Viewer:用面板管理记忆
长期记忆如果只能通过接口或文件修改,排查问题会很麻烦。MemOS 提供了 Memory Viewer,把记忆、任务、技能、日志和配置做成了网页管理界面。
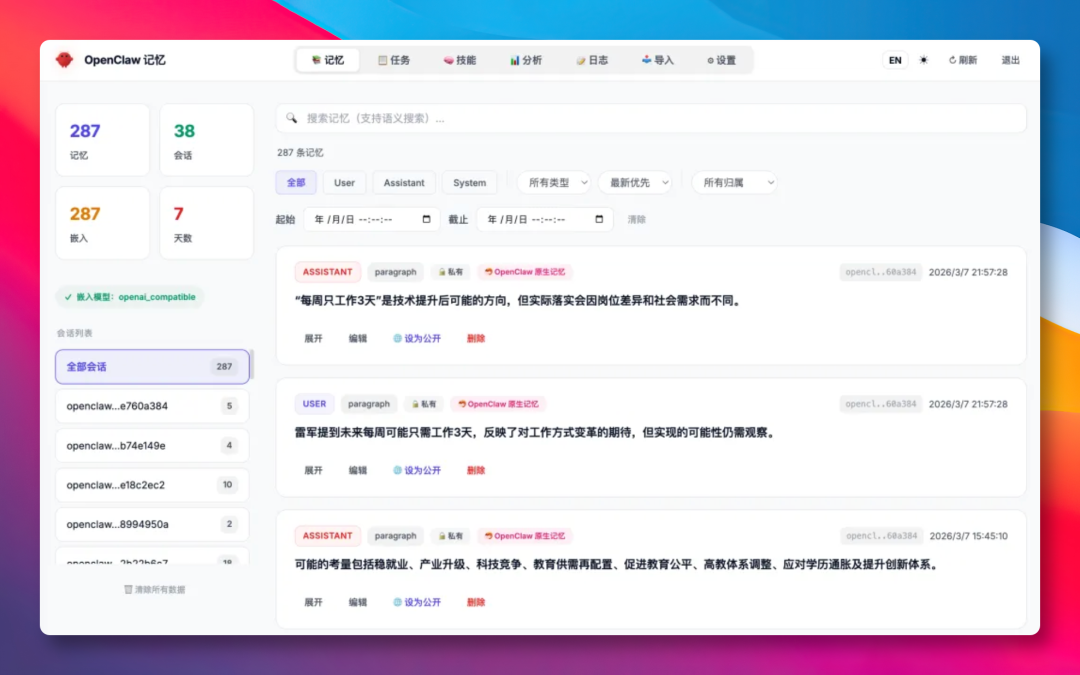
这个面板的价值不只是“看起来方便”,而是能直接处理长期记忆系统最常见的维护问题:记忆是否准确、任务是否归档、技能是否过期、检索是否正常、工具调用是否失败。
主要页面可以按功能分成六类:
| 页面 | 用途 |
|---|---|
| Memories | 按时间线查看记忆,支持新增、编辑、删除和语义搜索 |
| Tasks | 查看任务摘要,追踪每次调试或执行过程的结构化记录 |
| Skills | 管理 Skill,查看版本历史,下载可复用技能 |
| Analytics | 查看读写统计、活跃度、记忆分布等指标 |
| Logs | 查看工具调用日志、输入输出和耗时,定位执行问题 |
| Settings | 在线调整模型、检索和相关配置 |
面板默认绑定在 127.0.0.1,也就是只允许本机访问;再配合密码保护和 Session Cookie,可以降低外部网络误访问带来的风险。对于本地开发环境来说,这种默认策略比直接监听公网地址安全得多。
检索机制:全文检索与向量检索双通道
长期记忆能不能真正提高 Agent 质量,核心取决于两件事:
- 该记住的内容有没有被正确保存;
- 需要时能不能把正确记忆找出来。
MemOS 在检索层使用了“全文检索 + 向量检索”的双通道方案。
flowchart TD
A[用户新请求] --> B[查询改写与语义理解]
B --> C[FTS5 全文检索]
B --> D[向量检索]
C --> E[RRF 融合排序]
D --> E
E --> F[MMR 重排]
F --> G[选择高相关且低重复的记忆]
G --> H[注入 OpenClaw 上下文]
几个关键组件分别承担不同职责:
| 组件 | 全称 / 含义 | 解决的问题 |
|---|---|---|
| FTS5 | SQLite Full-Text Search 5,SQLite 的全文检索模块 | 精确匹配关键词、命令、错误码、文件名 |
| 向量检索 | 把文本转成 Embedding 向量后按语义相似度召回 | 找到表达不同但意思相近的记忆 |
| RRF | Reciprocal Rank Fusion,倒数排名融合 | 合并多个检索通道的结果,避免单一路径偏差 |
| MMR | Maximal Marginal Relevance,最大边际相关性 | 在相关性和多样性之间平衡,减少重复内容 |
| SHA-256 去重 | 基于内容哈希识别重复片段 | 避免相同记忆反复堆积 |
| 语义分块 | 按语义边界切分内容 | 让每条记忆保持完整含义,避免切得过碎或过长 |
全文检索适合找“精确出现过”的东西,比如错误码、函数名、文件路径:
ModuleNotFoundError: No module named 'xxx'
docker compose up
.env.local
向量检索适合找“意思相近”的东西。比如用户问“之前那个部署端口冲突怎么处理”,记忆里可能没有“端口冲突”这几个字,而是记录了“服务启动失败,因为 3000 端口被占用,改为 3001 后恢复”。语义检索能把这种记录找出来。
RRF 和 MMR 的组合,则是为了避免两个极端:
- 只靠关键词,容易漏掉语义相关内容;
- 只靠向量,可能召回看似相关但细节不准确的内容;
- 召回太多相似片段,会浪费上下文窗口。
历史记忆迁移与去重
已经使用 OpenClaw 一段时间后,历史对话里通常积累了不少经验。MemOS 的 Memory Viewer 提供 Import 入口,可以把原有记忆迁移进来。
迁移过程要重点关注两件事:不要丢数据,也不要把重复内容原样堆进去。
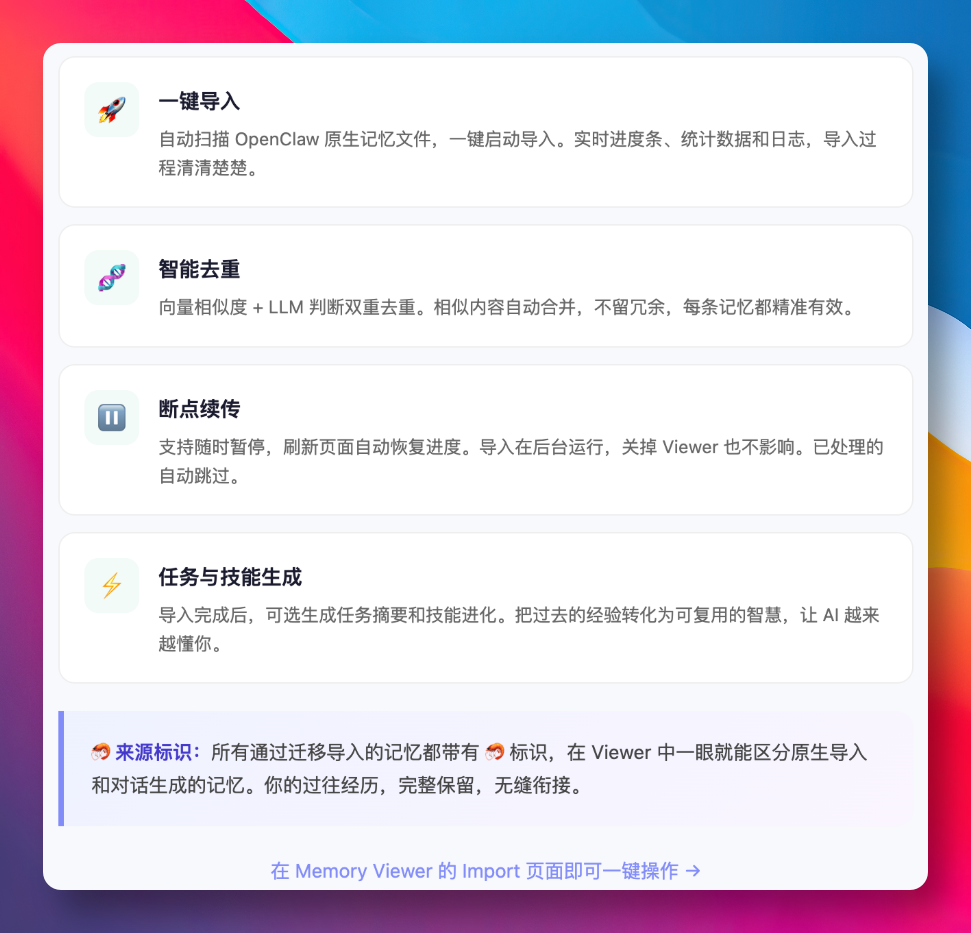
导入页面承担的是“把旧资产整理进新系统”的角色。迁移时可以对历史对话、调试经验和技术方案进行智能去重;如果导入过程被打断,也支持断点续传。迁移完成后,还可以继续生成任务摘要或沉淀 Skill,让旧对话不只是归档,而是变成可检索、可复用的知识资产。
安装与配置
MemOS OpenClaw 插件可以通过 npm 安装。安装完成后,启动 OpenClaw Gateway 即可进入管理面板。
安装插件
openclaw plugins install @memtensor/memos-lite-openclaw-plugin
openclaw gateway start
启动后访问:
http://127.0.0.1:18799
Memory Viewer 会在本机浏览器打开。
通过界面配置
Settings 页面可以配置 Embedding、摘要模型和 Skill 演化使用的模型。
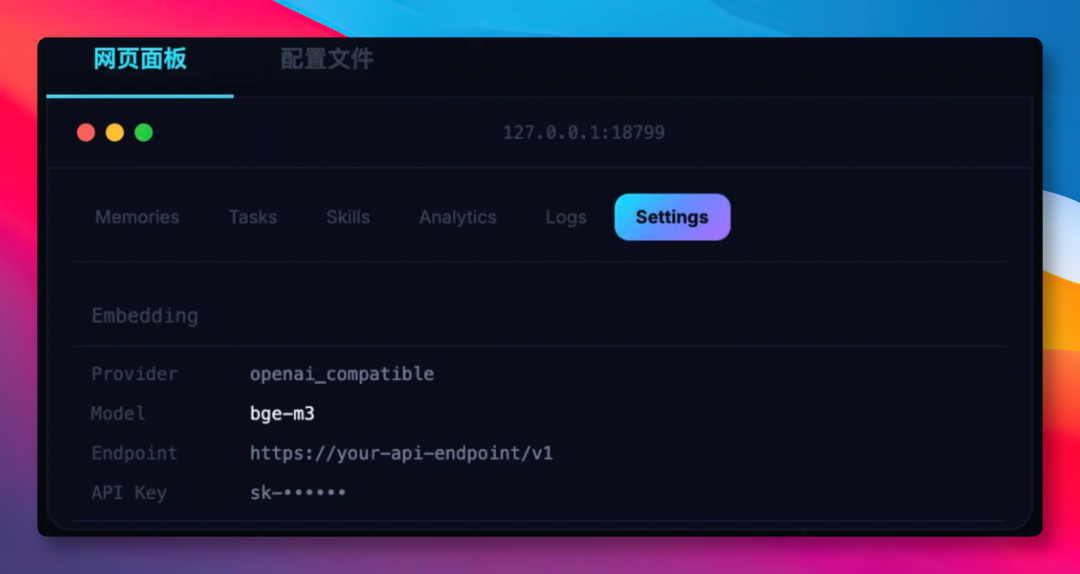
这个页面适合不想直接改 JSON 的场景。模型、接口地址和密钥可以在界面里调整,不需要手工翻配置文件。
通过 openclaw.json 配置
也可以直接编辑 openclaw.json。一个典型配置如下:
{
"plugins": {
"slots": {
"memory": "memos-lite"
},
"entries": {
"memos-lite": {
"config": {
"embedding": {
"provider": "openai_compatible",
"model": "bge-m3",
"endpoint": "https://your-api-endpoint/v1",
"apiKey": "sk-••••••"
},
"summarizer": {
"provider": "openai_compatible",
"model": "gpt-4o-mini",
"endpoint": "https://your-api-endpoint/v1",
"apiKey": "sk-••••••"
},
"skillEvolution": {
"summarizer": {
"provider": "openai_compatible",
"model": "claude-4.6-opus",
"endpoint": "https://your-api-endpoint/v1",
"apiKey": "sk-••••••"
}
}
}
}
}
}
}
配置里有三块比较关键:
| 配置项 | 作用 |
|---|---|
embedding | 把记忆文本转成向量,用于语义检索 |
summarizer | 对任务、对话和记忆进行摘要压缩 |
skillEvolution.summarizer | 用于 Skill 生成、更新和优化 |
如果使用本地内置 Embedding 模型,可以不配置外部 API Key;如果希望接入 OpenAI Compatible 接口,则需要填写对应的 endpoint 和 apiKey。
修改配置后重新启动 Gateway:
openclaw gateway start
适合与不适合的使用场景
MemOS 的收益主要来自“长期积累”和“复用”。如果任务本身是一次性的、没有上下文延续,长期记忆带来的价值不会特别明显。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 长期维护同一个代码仓库 | 适合 | 项目结构、规范、历史坑位都值得沉淀 |
| 经常做类似部署或排障 | 适合 | 可以把成功流程变成 Skill |
| 多 Agent 分工协作 | 适合 | 团队记忆能减少重复沟通 |
| 敏感项目本地开发 | 适合 | 本地 SQLite 存储更容易控制数据边界 |
| 临时问答 | 不太需要 | 没有明显长期复用价值 |
| 高度合规环境 | 需要评估 | 要确认本地文件、模型接口和访问权限符合要求 |
| 不希望维护额外服务 | 需要权衡 | Gateway、面板和数据库都需要纳入开发环境管理 |
使用时需要注意的坑
1. 不要把所有内容都当成记忆
长期记忆不是聊天记录备份。错误猜测、临时尝试、未验证方案如果被长期保存,后续可能误导 Agent。
更合理的做法是只沉淀这些内容:
- 已验证成功的命令;
- 明确失败的方案和失败原因;
- 项目长期有效的规则;
- 用户稳定偏好;
- 可复用流程;
- 关键环境约束。
2. Skill 要有验证步骤
一个 Skill 如果只有执行步骤,没有验证方式,Agent 很难判断任务是否真的完成。部署类 Skill 至少应该包含:
# 示例:检查服务端口
curl -f http://127.0.0.1:3000/health
# 示例:检查进程
ps aux | grep your-service
# 示例:检查容器状态
docker ps
验证步骤越明确,Skill 越容易自动化复用。
3. 共享记忆要控制权限
团队 Hub 不能简单理解成“所有 Agent 共用一个数据库”。共享范围需要谨慎设计,尤其是密钥、客户数据、内部网络地址等信息,应该默认保守处理。
4. 定期清理过期记忆
项目依赖、部署方式和团队规范都会变化。过期记忆如果没有清理,可能导致 Agent 继续使用旧方案。Memory Viewer 里的时间线、搜索和 Analytics 页面可以帮助定位长期未更新或重复出现的记忆。
5. 检索不是越多越好
注入上下文的记忆太多,会挤占模型处理当前任务的空间。更好的策略是召回少量高相关、低重复的内容。FTS5、向量检索、RRF 和 MMR 的组合,目的也是为了让上下文更精确,而不是更庞大。
小结
MemOS 给 OpenClaw 补上的不是简单的“聊天记录保存”,而是一套围绕 Agent 经验资产构建的基础设施:对话可以沉淀成记忆,复杂任务可以沉淀成 Skill,多 Agent 可以通过 Hub 共享已验证经验,敏感数据也可以留在本地 SQLite 中管理。
当 Agent 使用频率变高后,真正影响效率的往往不是单次回答有多快,而是过去的经验能不能在下一次任务中继续发挥作用。MemOS 的价值就在这里:让 OpenClaw 从每次重新开始,变成持续积累、持续复用。