LLM(大型语言模型)驱动的 Agent(智能体)如果没有记忆,本质上仍然是一个“输入一次、响应一次”的无状态系统。它可以在单轮任务里表现出不错的推理能力,但很难长期积累知识、复用过去经验,也很难在复杂任务中持续修正自己的行为。
Agent 记忆要解决的核心问题有三个:
- 知识会过期:LLM 的参数知识有训练截止时间,外部世界变化后,模型本身不会自动知道。
- 交互历史太长:把所有历史都塞进上下文窗口成本高,而且会带来噪声。
- 经验难以沉淀:Agent 调用工具、执行任务、失败重试之后,如果不能把经验结构化保存,下次还会犯类似错误。
传统做法常见于三类:把历史对话按时间顺序拼接进 prompt、把片段写入向量数据库、把用户偏好做成键值对。这些方案能解决一部分问题,但关系表达能力很弱。比如“用户 A 喜欢低盐饮食”“用户 A 最近血压偏高”“医生建议减少咖啡摄入”三条记忆,如果只是独立文本片段,检索时很难稳定地把它们组合成一个完整判断。
图结构记忆的思路是:把记忆拆成节点、边和属性,让 Agent 不只记住“发生过什么”,还记住“事物之间是什么关系”。
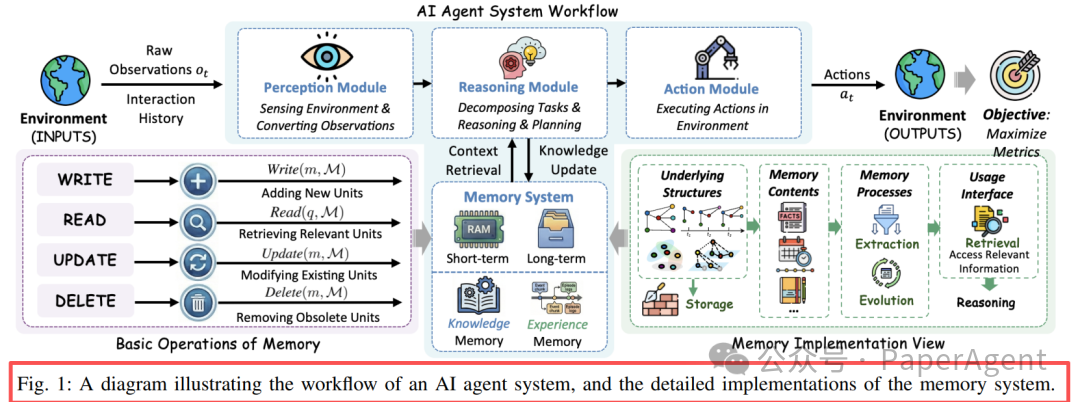
这套视图把 Agent 的工作流程拆成感知、规划、行动、反馈和记忆管理几个部分。记忆不再只是 prompt 旁边的附属缓存,而是贯穿整个 Agent 循环:Agent 从环境中观察信息,把有价值的内容写入记忆;执行任务时从记忆中检索相关上下文;任务结束后再把结果、失败原因和新的关系更新回记忆。
用一个简化流程表示,会更接近工程实现:
flowchart LR
A[环境观察/用户输入] --> B[记忆提取]
B --> C[(图结构记忆)]
C --> D[记忆检索]
D --> E[LLM 推理与规划]
E --> F[工具调用/环境行动]
F --> G[执行反馈]
G --> H[记忆演化]
H --> C
为什么图结构适合做 Agent 记忆
图由节点和边组成。节点可以表示用户、任务、工具、事实、事件、计划、错误、偏好;边表示它们之间的关系,比如“属于”“依赖”“导致”“支持”“反驳”“发生在某时间之后”。
和线性记忆相比,图结构有几个明显优势:
| 记忆形式 | 存储方式 | 擅长表达 | 主要问题 |
|---|---|---|---|
| 上下文缓冲区 | 按时间拼接文本 | 最近对话、短期连续上下文 | 长度有限,旧信息容易丢失 |
| 键值存储 | key-value | 用户偏好、配置项、状态变量 | 关系表达弱,复杂推理困难 |
| 向量数据库 | 文本片段 + embedding | 语义相似检索 | 更新粒度粗,难解释关系链 |
| 图结构记忆 | 节点 + 边 + 属性 | 实体关系、因果链、任务经验、长期演化 | 构建和维护成本更高 |
图结构并不是要完全替代向量数据库。更合理的做法是把两者结合起来:向量检索负责找到语义相近的入口节点,图遍历负责沿着关系扩展上下文。
flowchart LR
Q[查询] --> V[向量召回候选节点]
V --> G[图遍历扩展关系]
G --> R[排序与裁剪]
R --> C[组织成上下文]
C --> L[LLM 推理]
两类记忆:知识记忆和经验记忆
Agent 记忆可以先分成两大类:知识记忆和经验记忆。
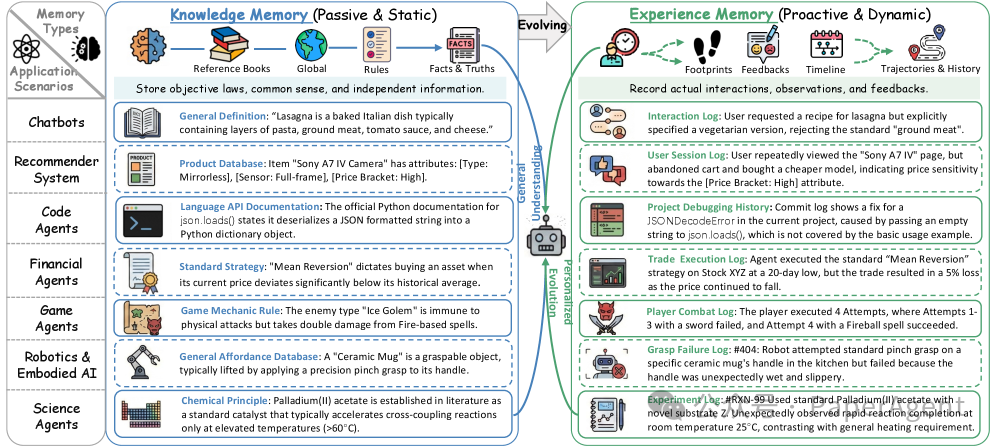
知识记忆描述相对稳定的事实、规则和概念。经验记忆描述 Agent 在任务执行过程中获得的轨迹、反馈和策略调整。两者的区别不是“一个重要、一个不重要”,而是用途不同。
| 类型 | 记什么 | 典型例子 | 作用 |
|---|---|---|---|
| 知识记忆 | 事实、概念、规则、用户偏好、领域知识 | “用户对青霉素过敏”“退款流程需要订单号”“Python 中 list 是可变对象” | 让 Agent 知道规则和背景 |
| 经验记忆 | 任务轨迹、工具调用结果、失败原因、成功策略 | “上次调用搜索 API 超时后改用本地索引成功”“某类 SQL 报错通常是字段名写错” | 让 Agent 从过去行为中学习 |
知识记忆更像“世界模型”,经验记忆更像“行动日志 + 复盘结果”。一个可靠的 Agent 通常需要同时维护两者。
例如客服 Agent 可以这样组织记忆:
知识记忆:
- 用户 U123 是高级会员
- 高级会员支持 7 天无理由退货
- 退货必须绑定订单号
经验记忆:
- 2026-05-01 用户 U123 申请退货时没有提供订单号
- Agent 先询问订单号,再调用订单查询工具
- 该流程成功完成,用户未继续追问
如果只保存知识,Agent 知道规则但不会优化流程;如果只保存经验,Agent 会记住过去发生过什么,却缺乏可迁移的规则。图结构可以把两者放在同一个记忆网络里,通过边把事实和经验连接起来。
传统记忆可以看成图的退化形式
图结构记忆有一个很有用的统一视角:很多传统记忆形式都可以看成特殊图。
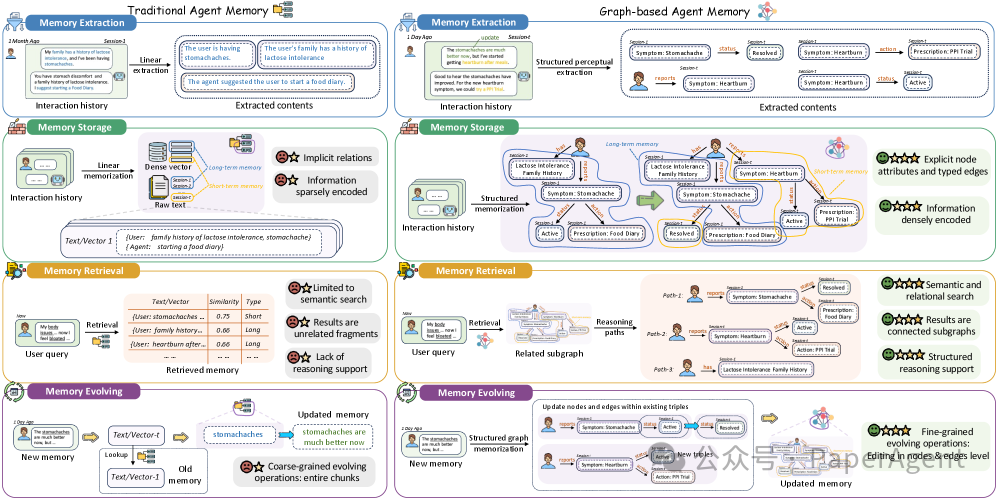
这组对比强调了传统记忆和图结构记忆在提取、存储、检索、更新上的差别。传统记忆通常把内容切成文本块,再通过相似度召回;图结构记忆会显式抽取实体、事件和关系,并允许对节点或边做细粒度更新。
几种常见存储可以这样理解:
flowchart TD
A[线性缓冲区] --> A1[一条时间链]
B[键值存储] --> B1[中心 key 指向多个 value 的星型结构]
C[向量记忆] --> C1[按相似度连接的加权图]
D[图结构记忆] --> D1[显式节点、边、属性与子图]
这意味着图结构不是孤立方案,而是更一般的表达方式。线性日志可以成为时间边,键值对可以成为属性边,向量相似度可以成为隐式加权边。工程上可以逐步迁移,不需要一次性推倒重做。
图结构记忆的生命周期
图结构记忆可以按生命周期拆成四个阶段:提取、存储、检索、演化。
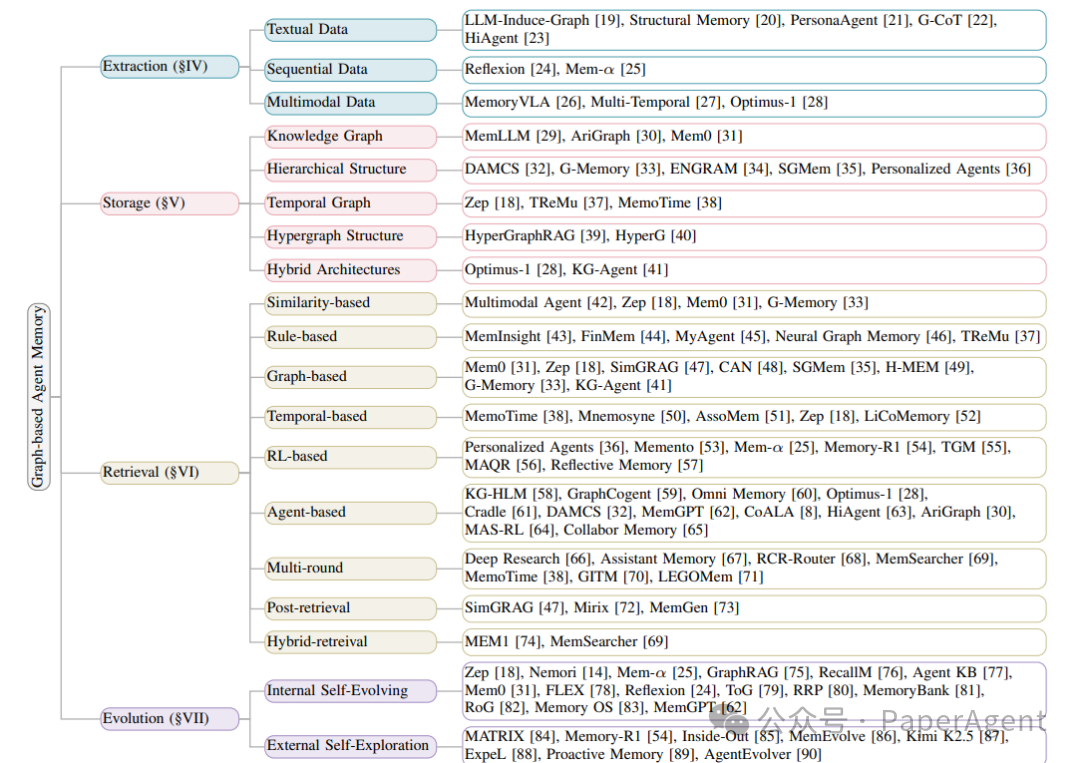
这套分类把记忆管理看成一个闭环。提取阶段把原始信息变成结构化记忆;存储阶段选择合适的图范式;检索阶段从图中找出和当前任务相关的子图;演化阶段根据新观察和任务反馈更新节点、边和权重。
flowchart LR
A[Extraction 记忆提取] --> B[Storage 记忆存储]
B --> C[Retrieval 记忆检索]
C --> D[Evolution 记忆演化]
D --> A
记忆提取:把原始观察变成结构化单元
记忆提取的输入通常很杂:用户对话、工具返回结果、网页内容、代码执行日志、环境状态、传感器数据。提取阶段要做的事情不是“全部保存”,而是识别哪些信息值得进入长期记忆,并把它们转换为可维护的结构。
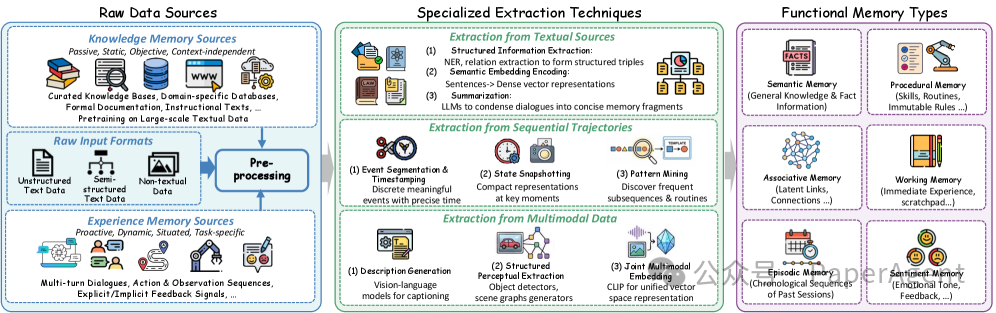
提取流程一般包含四步:
- 过滤:去掉无关内容、重复内容、临时噪声。
- 识别:抽取实体、事件、属性、意图、约束、结果。
- 归一化:把同一个实体的不同说法合并,比如“张三”“张先生”“用户 U123”。
- 结构化:生成节点、边和属性,写入图存储。
一个记忆提取结果可以设计成这样的 JSON:
{
"memory_type": "experience",
"source": "tool_call_log",
"event": {
"id": "event_20260607_001",
"action": "search_document",
"result": "timeout",
"timestamp": "2026-06-07T10:30:00+08:00"
},
"entities": [
{
"id": "tool_search",
"type": "Tool",
"name": "document_search"
},
{
"id": "task_refund_policy",
"type": "Task",
"name": "查询退款政策"
}
],
"relations": [
{
"source": "task_refund_policy",
"target": "tool_search",
"type": "USED_TOOL"
},
{
"source": "tool_search",
"target": "event_20260607_001",
"type": "RESULTED_IN"
}
],
"salience": 0.72
}
这里的 salience 表示记忆重要性。不是所有观察都应该长期保存,否则图会快速膨胀。常用判断依据包括:是否影响后续决策、是否反复出现、是否和用户偏好有关、是否包含失败经验、是否能抽象成规则。
记忆存储:选择合适的图结构
存储阶段要决定图长什么样。不同任务适合不同图范式。
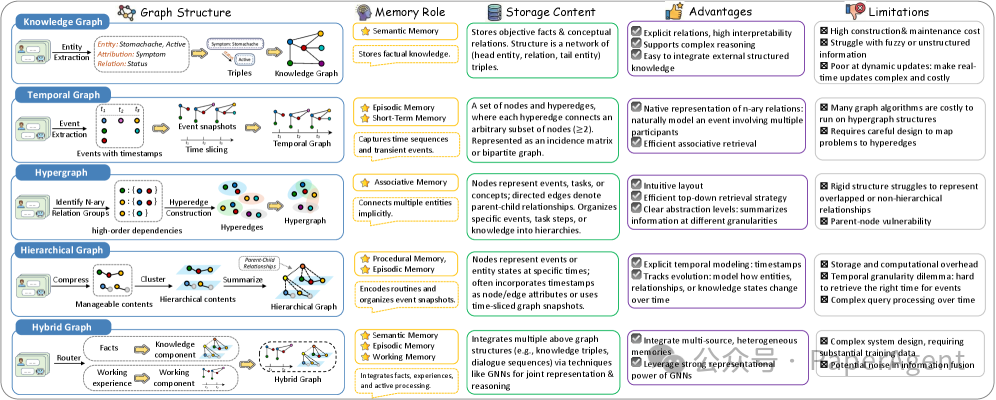
这张分类把图结构记忆常见存储方式分成五类:知识图谱、层次结构、时序图、超图和混合架构。它们解决的问题不同。
| 图结构范式 | 核心表达 | 适合场景 | 代价 |
|---|---|---|---|
| 知识图谱(Knowledge Graph) | 实体和关系 | 领域知识、用户画像、事实问答 | schema 设计要求高 |
| 层次结构 | 父子层级、摘要树 | 长文档记忆、任务分解、项目结构 | 跨层关系可能丢失 |
| 时序图 | 事件随时间变化 | 对话历史、行为轨迹、状态演化 | 需要处理过期和版本 |
| 超图 | 一条关系连接多个节点 | 多方协作、复杂事件、多实体约束 | 存储和检索实现更复杂 |
| 混合架构 | 多种图组合 | 真实 Agent 系统 | 工程复杂度最高 |
一个基础 schema 可以这样设计:
(:User)-[:HAS_PREFERENCE]->(:Preference)
(:User)-[:ASKED]->(:Question)
(:Task)-[:USES_TOOL]->(:Tool)
(:ToolCall)-[:RESULTED_IN]->(:Outcome)
(:Event)-[:MENTIONS]->(:Entity)
(:Event)-[:HAPPENED_BEFORE]->(:Event)
(:Experience)-[:GENERALIZES_TO]->(:Rule)
如果使用图数据库,可以用类似 Cypher 的方式查询:
MATCH (u:User {id: "U123"})-[:HAS_PREFERENCE]->(p:Preference)
MATCH (u)-[:ASKED]->(q:Question)-[:RELATED_TO]->(topic:Topic)
RETURN p, q, topic
LIMIT 20;
真实系统里通常还会给节点增加向量表示:
Node {
id: "pref_low_salt",
type: "Preference",
text: "用户偏好低盐饮食",
embedding: [...],
created_at: "...",
updated_at: "...",
confidence: 0.91
}
这样做的好处是,查询可以先用 embedding 找入口,再用图关系扩展。
记忆检索:从图里取出有用子图
检索阶段的目标不是“查到越多越好”,而是为当前推理构造足够相关、足够紧凑、足够可信的上下文。
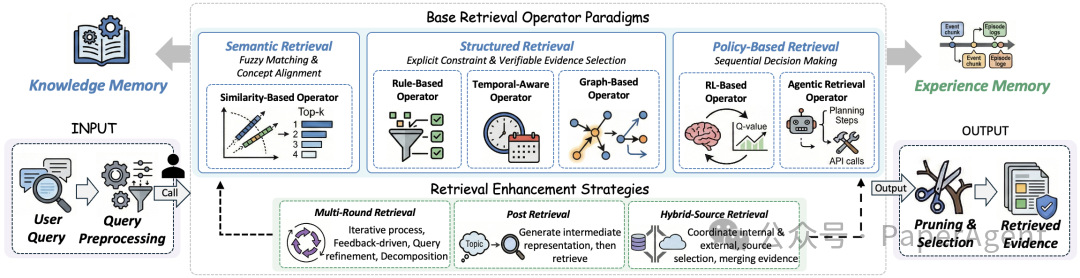
检索流程通常包含查询理解、候选召回、图扩展、排序裁剪和上下文组织。图结构记忆的检索算子比普通向量库更丰富。
| 检索算子 | 做法 | 适合问题 |
|---|---|---|
| 节点检索 | 找语义或属性匹配的节点 | 用户偏好、事实查找 |
| 邻居扩展 | 从入口节点沿边扩展一跳或多跳 | 找上下文关系 |
| 路径检索 | 找两个节点之间的关系链 | 解释因果、依赖、证据链 |
| 子图检索 | 返回一组相关节点和边 | 复杂任务推理 |
| 时序检索 | 按时间过滤或排序事件 | 最近状态、长期趋势 |
| 权重检索 | 按重要性、置信度、频率排序 | 过滤噪声记忆 |
一个简化检索函数可以写成这样:
def retrieve_memory(query, graph, vector_index, top_k=20):
# 1. 语义召回入口节点
seed_nodes = vector_index.search(query, k=top_k)
# 2. 沿图关系扩展上下文
candidate_subgraph = graph.expand(
nodes=seed_nodes,
max_hops=2,
edge_types=["RELATED_TO", "CAUSED_BY", "USED_TOOL", "HAS_PREFERENCE"]
)
# 3. 综合相关性、时间、置信度和重要性排序
ranked_items = rank_memories(
subgraph=candidate_subgraph,
query=query,
weights={
"semantic_similarity": 0.45,
"recency": 0.20,
"confidence": 0.20,
"salience": 0.15
}
)
# 4. 压缩成 LLM 可读上下文
return pack_as_context(ranked_items, token_budget=3000)
检索增强策略可以分三类:
| 策略 | 核心思想 | 例子 |
|---|---|---|
| 多轮检索 | 把检索当成迭代过程,每轮根据已有结果生成新查询 | 先找用户,再找用户相关任务,再找任务失败经验 |
| 检索后处理 | 先生成中间表示,再检索 | 先判断意图是“退款”,再检索退款规则 |
| 混合源检索 | 同时查内部记忆和外部资源 | 图记忆 + 本地文档 + 在线搜索 API(应用程序编程接口) |
多轮检索的调用顺序可以这样组织:
sequenceDiagram
participant U as 用户请求
participant A as Agent
participant M as 图记忆
participant E as 外部资源
participant L as LLM
U->>A: 提出任务
A->>M: 检索相关用户、任务、经验
M-->>A: 返回入口子图
A->>L: 生成补充查询
A->>M: 沿关系继续检索
A->>E: 必要时查询外部资源
E-->>A: 返回最新信息
A->>L: 组织上下文并推理
L-->>A: 输出计划或答案
记忆演化:让记忆随任务反馈更新
图结构记忆的关键价值在于可演化。传统向量库更新通常是“插入新文本”或“删除旧文本”,而图可以对节点、边、属性、权重和子图做局部更新。
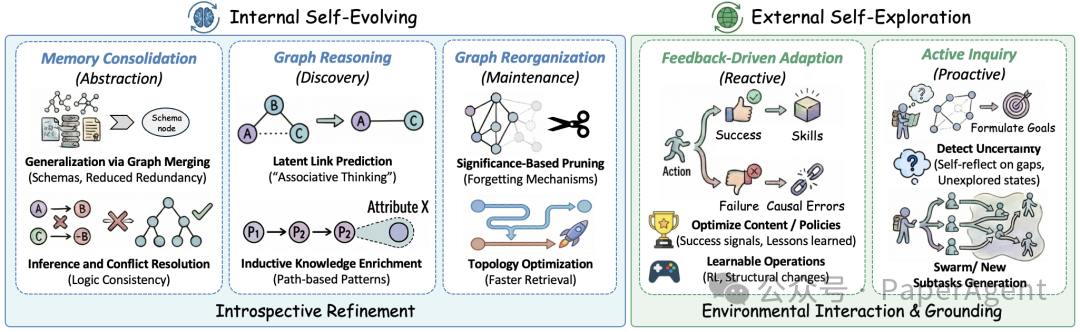
记忆演化可以分为两类:内部自我演化和外部自我探索。
内部自我演化更像记忆整理。Agent 在任务间隙对已有图进行压缩、合并、冲突检测和规则抽象。比如多次观察到“调用工具 A 查询订单经常超时”,可以把多个事件抽象成一条经验规则。
外部自我探索强调通过环境交互验证记忆。Agent 发现某条记忆置信度低,可以主动查询工具、搜索资料或执行测试,再根据结果更新图。
常见演化操作如下:
| 操作 | 含义 | 例子 |
|---|---|---|
| 新增节点 | 写入新实体、新事件、新规则 | 新增一次工具失败事件 |
| 新增边 | 建立新关系 | “失败事件 CAUSED_BY 参数缺失” |
| 更新属性 | 修改置信度、重要性、时间戳 | 将旧偏好的置信度降低 |
| 合并节点 | 解决实体重复 | “张先生”和“U123”合并 |
| 删除或归档 | 清理过期、低价值记忆 | 删除临时验证码 |
| 抽象子图 | 从多次经验中生成规则 | 多次失败经验抽象成调度策略 |
| 冲突处理 | 标记互相矛盾的记忆 | 新偏好覆盖旧偏好 |
记忆演化不能只靠追加,否则图会越来越乱。工程系统里至少需要三个机制:
flowchart TD
A[新记忆写入] --> B{是否重复?}
B -- 是 --> C[合并节点或更新属性]
B -- 否 --> D[新增节点和边]
D --> E{是否与旧记忆冲突?}
E -- 是 --> F[保留版本并降低旧记忆置信度]
E -- 否 --> G[更新重要性和时间戳]
G --> H[周期性压缩与归档]
F --> H
一个可落地的图结构记忆架构
一个工程可用的 Agent 记忆系统可以拆成五层:
flowchart TB
A[数据源层<br/>对话、工具日志、文档、环境反馈] --> B[提取层<br/>实体、事件、关系、规则]
B --> C[存储层<br/>图数据库 + 向量索引 + 元数据]
C --> D[检索层<br/>语义召回、图遍历、路径排序]
D --> E[推理层<br/>上下文组装、规划、工具调用]
E --> F[演化层<br/>合并、冲突处理、抽象、归档]
F --> C
每层的职责要边界清晰:
| 层级 | 职责 | 关键设计 |
|---|---|---|
| 数据源层 | 收集 Agent 观察和行动结果 | 保留来源、时间、任务 ID |
| 提取层 | 把非结构化内容转为图元素 | schema、实体消歧、重要性评分 |
| 存储层 | 保存节点、边、向量和版本 | 图数据库、向量索引、权限控制 |
| 检索层 | 取出相关子图 | 多跳扩展、排序、token 预算 |
| 推理层 | 把子图变成 LLM 上下文 | 去噪、压缩、引用证据 |
| 演化层 | 维护长期质量 | 合并、冲突、过期、规则抽象 |
一个上下文组装模板可以这样写:
# 与当前任务相关的用户信息
- 用户 U123 偏好:低盐饮食,置信度 0.91
- 用户 U123 历史问题:咨询过高血压饮食建议
# 相关领域规则
- 高血压饮食建议通常需要控制钠摄入
- 咖啡因摄入可能影响部分用户的血压管理
# 相关经验
- 上次回答健康建议时,缺少免责声明导致用户追问
- 更稳妥的回答方式:提供一般性建议,并提醒咨询专业医生
# 当前推理约束
- 不生成诊断结论
- 不替代医生建议
这样的上下文比简单拼接历史更可控。每条信息都有来源、类型和置信度,LLM 更容易基于结构化证据推理。
什么时候适合用图结构记忆
图结构记忆不是所有 Agent 的默认选项。任务越复杂、关系越多、生命周期越长,图的价值越明显。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 单轮问答机器人 | 不一定 | 上下文短,向量检索已足够 |
| 长期个人助手 | 适合 | 用户偏好、历史任务、状态变化需要长期维护 |
| 代码 Agent | 适合 | 文件、函数、依赖、错误日志天然是图 |
| 医疗、法律、金融辅助系统 | 适合但要谨慎 | 需要可解释关系和证据链,同时要严格权限与合规 |
| 多 Agent 协作系统 | 适合 | 子任务、角色、消息、结果之间关系复杂 |
| 简单表单自动化 | 不太适合 | 图维护成本可能高于收益 |
评测图结构记忆时看什么
记忆系统不能只看“召回率”。Agent 记忆最终要服务任务完成质量,因此评测维度要覆盖检索、推理、更新和长期稳定性。
| 维度 | 评测问题 | 可观察指标 |
|---|---|---|
| 相关性 | 检索结果是否真正帮助当前任务 | precision、人工标注相关性 |
| 完整性 | 是否漏掉关键关系 | recall、路径覆盖率 |
| 可解释性 | 能否给出关系链和来源 | 证据路径长度、引用准确率 |
| 时效性 | 旧记忆是否会误导新任务 | 过期记忆命中率、版本冲突率 |
| 更新质量 | 新经验能否正确写入 | 节点重复率、错误边比例 |
| 任务收益 | Agent 是否完成得更好 | 成功率、重试次数、工具调用成本 |
| 成本 | 检索和维护是否可接受 | 延迟、存储量、token 消耗 |
如果一个图记忆系统让检索结果变多,但任务成功率没有提高,通常说明子图裁剪、排序或上下文组织存在问题。
工程中的常见坑
schema 设计过细
一开始就设计几十种节点和边,系统会很难维护。更稳妥的方式是从少量稳定类型开始:
Node: User, Task, Event, Entity, Tool, Outcome, Rule
Edge: RELATED_TO, USED_TOOL, RESULTED_IN, CAUSED_BY, HAPPENED_BEFORE, SUPPORTS, CONTRADICTS
等数据量和任务模式稳定后,再扩展更细的类型。
只追加,不合并
图记忆如果只写入新节点,很快会出现大量重复实体。实体消歧和节点合并必须作为基础能力存在,否则检索会返回一堆相似但不一致的信息。
没有置信度和来源
记忆不应该只有内容,还要有来源、时间和置信度。尤其在高风险场景里,Agent 需要知道一条记忆来自用户陈述、工具返回、外部网页还是模型推断。
图检索扩展太宽
多跳扩展容易把无关节点带进上下文。常用限制包括:
max_hops: 2
allowed_edge_types: ["HAS_PREFERENCE", "RELATED_TO", "RESULTED_IN"]
min_confidence: 0.7
time_window: "最近 90 天"
token_budget: 3000
旧记忆污染新任务
用户偏好、环境状态、工具行为都会变化。长期记忆必须有过期策略。常见做法是对旧记忆降低权重,而不是直接删除;当新旧记忆冲突时,优先使用时间更新、来源更可靠、置信度更高的记忆。
结语
图结构记忆把 Agent 的记忆从“文本片段集合”提升为“可检索、可解释、可更新的关系网络”。它适合长期任务、复杂关系推理、多工具调用和多 Agent 协作场景。
落地时可以从一个小闭环开始:先抽取实体和事件,写入简单知识图谱;再加入向量入口检索和一跳关系扩展;等数据稳定后,引入冲突处理、经验抽象和周期性归档。图结构的价值不在于把所有东西都画成图,而在于让关键知识和关键经验能够被 Agent 稳定地找回、组合和修正。