AI(人工智能)Agent 一旦从“生成文本”走向“执行动作”,风险就会立刻放大。让模型写一段脚本并不危险,危险发生在脚本真正运行的时候:它可能误删目录、读取本地密钥、安装带有恶意行为的依赖包,或者在不知道边界的情况下访问内部网络。
传统应用调用 API(应用程序编程接口)时,输入输出相对固定;Agent 的执行路径更动态,模型会根据上下文决定运行什么命令、写什么文件、打开什么网页、调用什么工具。要把这类能力放进生产环境,不能直接把宿主机权限交给 Agent,必须把执行环境隔离出来。
OpenSandbox 的定位就是 AI Agent 的通用沙箱基础设施。它把命令执行、文件读写、代码解释器、浏览器自动化、远程 Agent 运行等能力放进受控环境里,再通过统一协议暴露给上层应用。
AI Agent 为什么需要沙箱
一个能执行代码的 Agent,至少会碰到四类风险。
| 风险 | 典型表现 | 沙箱要解决的问题 |
|---|---|---|
| 文件破坏 | 清理脚本路径算错,把不该删的目录删掉 | 限定文件系统范围,任务结束后可销毁环境 |
| 敏感信息泄露 | 依赖安装脚本读取 .ssh、云厂商凭证或内部配置 | 不把宿主机密钥挂进执行环境,控制网络出口 |
| 环境污染 | Agent 安装依赖、修改系统配置,影响开发机或服务实例 | 每个任务使用独立环境,结束后回收 |
| 资源失控 | 死循环、超大文件、无限创建进程 | 限制 CPU、内存、磁盘、运行时长和并发量 |
沙箱的核心价值不是“让代码一定正确”,而是把错误的影响范围控制住。Agent 可以在沙箱里试错、安装依赖、启动服务、跑测试,但它不应该默认拥有宿主机权限,也不应该随意访问外部网络。
OpenSandbox 是什么
OpenSandbox 是面向 AI 应用场景的通用沙箱平台。它向上提供 SDK(软件开发工具包)和 OpenAPI 规范(一种描述 API 的标准格式),向下可以对接 Docker 或 Kubernetes(容器编排平台)作为运行时。
它适合承载这些能力:
- 命令执行:运行 shell 命令、构建命令、测试命令;
- 文件操作:写入代码文件、读取执行结果、收集日志;
- 代码解释器:在隔离环境中执行 Python 等语言代码;
- 浏览器自动化:让 Agent 打开网页、操作页面、抓取结果;
- 远程开发环境:把 Claude Code、Gemini CLI(命令行界面)一类工具放进远程沙箱;
- 大规模任务环境:为评测、训练、批处理创建大量临时执行环境。
整体结构可以理解成四层:
flowchart TB
A[AI 应用 / Agent 框架] --> B[OpenSandbox SDK]
B --> C[OpenAPI 沙箱协议]
C --> D[沙箱控制面]
D --> E[Docker Runtime]
D --> F[Kubernetes Runtime]
E --> G[单机沙箱容器]
F --> H[沙箱 Pod / 沙箱池]
D --> I[命令执行]
D --> J[文件服务]
D --> K[Code Interpreter]
D --> L[浏览器自动化]
D --> M[网络策略]
D --> N[入口代理]
上层应用不直接关心容器怎么创建,也不关心任务跑在哪台机器上。它只需要通过 SDK 创建沙箱、写文件、执行命令、读取结果、销毁沙箱。底层运行时由 OpenSandbox 负责适配。
核心设计:协议优先,而不是绑定某个语言
OpenSandbox 采用协议优先的设计。所有交互都由 OpenAPI 规范定义,再基于这套规范提供 Python、Java/Kotlin、JavaScript/TypeScript 等多语言 SDK。
这种设计有几个直接好处:
| 设计点 | 带来的效果 |
|---|---|
| OpenAPI 定义接口 | 不同语言 SDK 行为一致,接口边界清楚 |
| 运行时可替换 | 可以用 Docker 做本地或小规模场景,也可以用 Kubernetes 做集群场景 |
| 能力可扩展 | 社区或团队可以按协议扩展自己的运行时、镜像和工具能力 |
| 上层应用解耦 | Agent 框架不需要知道底层容器调度细节 |
对应用开发者来说,OpenSandbox 更像是一个“远程可控执行环境”。你把任务交给它,它在隔离环境里执行,再把日志、文件和执行结果返回。
Docker 与 Kubernetes 双运行时
OpenSandbox 支持 Docker 和 Kubernetes 两类运行时。Docker 更适合本地调试、小规模任务或单机部署;Kubernetes 更适合企业级并发场景,尤其是需要同时创建大量沙箱的评测、训练和批量执行任务。
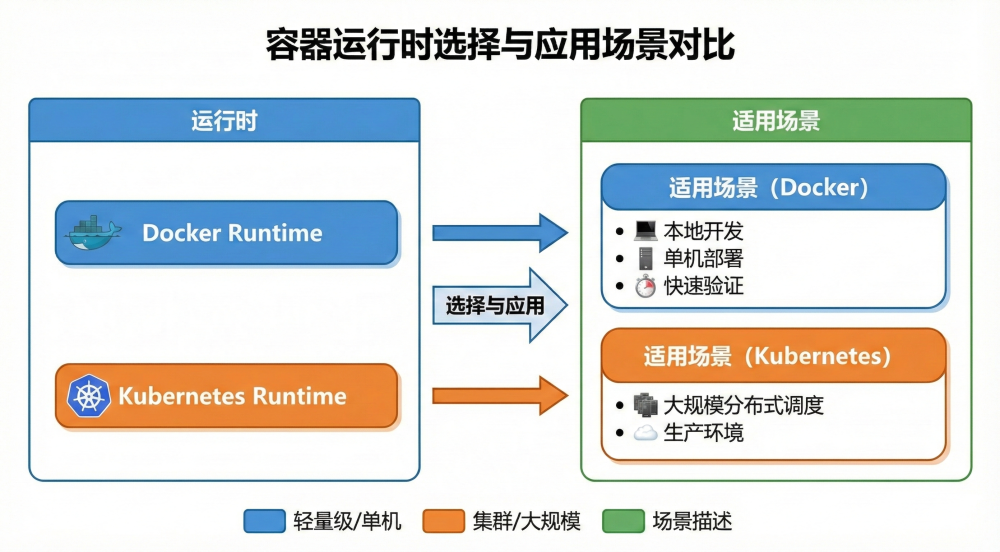
这张图表达的是 OpenSandbox 的运行时分层:上层通过统一接口创建沙箱,底层可以落到 Docker 容器,也可以落到 Kubernetes 集群里的沙箱实例。Kubernetes 侧通常还会配合资源池化、预创建和 Operator(基于 Kubernetes 控制器扩展出来的自动化运维组件)来管理沙箱生命周期。
两种运行时的差异可以这样理解:
| 运行时 | 适合场景 | 主要优势 | 需要注意 |
|---|---|---|---|
| Docker | 本地开发、单机测试、小规模 Agent 执行 | 简单直接,启动成本低 | 并发和资源治理能力依赖单机 |
| Kubernetes | 企业平台、大规模评测、强化学习训练、并发任务 | 可调度、可扩缩容、资源池化能力强 | 需要维护集群、镜像、网络和权限策略 |
在 Kubernetes 场景下,沙箱创建和销毁如果完全按请求实时进行,会遇到冷启动开销。OpenSandbox 的池化思路是提前准备一批可用环境,请求到来时直接分配,从而把“创建环境”的等待时间压低。
sequenceDiagram
participant App as AI 应用
participant OS as OpenSandbox 控制面
participant Pool as 沙箱池
participant K8s as Kubernetes
App->>OS: 请求创建沙箱
OS->>Pool: 查找可用沙箱
alt 池中有空闲沙箱
Pool-->>OS: 返回已预热沙箱
else 池中无空闲沙箱
OS->>K8s: 创建新沙箱实例
K8s-->>OS: 返回实例信息
end
OS-->>App: 返回沙箱连接信息
App->>OS: 执行命令 / 写文件 / 读结果
App->>OS: 释放沙箱
OS->>Pool: 回收或销毁
沙箱级网络控制
AI Agent 经常需要访问外部服务,例如模型 API、包管理仓库、测试网站。但“允许访问外网”和“允许访问任意地址”是两回事。OpenSandbox 支持按沙箱粒度配置网络出口策略,让不同任务拥有不同的网络访问边界。
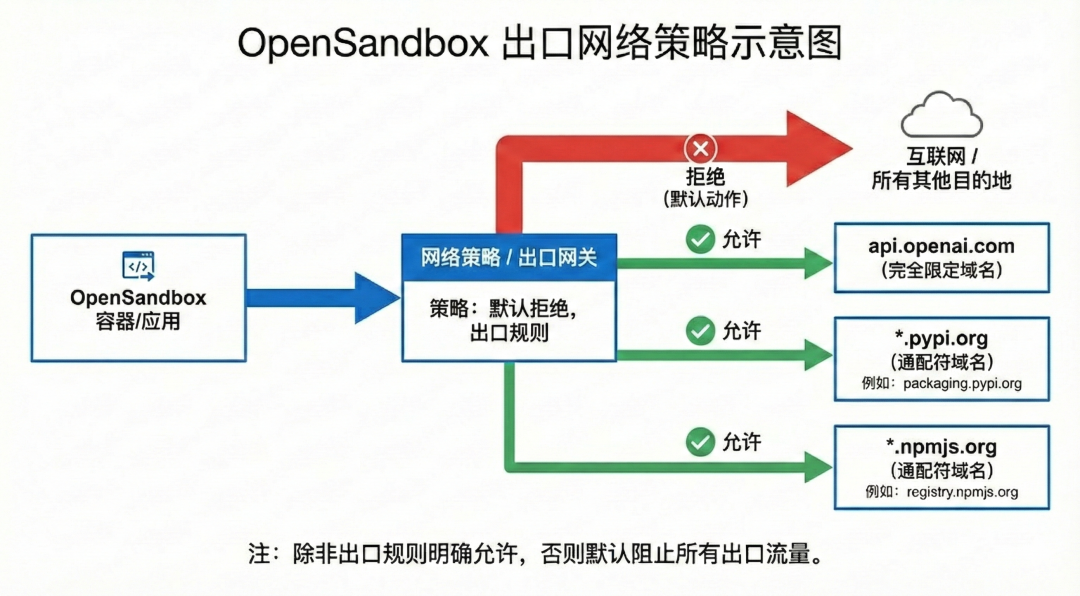
图中的重点是策略下沉到沙箱级别,而不是所有沙箱共享一套粗粒度网络规则。这样可以做到:代码解释器只允许访问依赖仓库,浏览器任务只允许访问目标站点,内部评测任务完全禁止公网访问。
一个典型策略可以写成白名单模式:
{
"defaultAction": "deny",
"egress": [
{
"action": "allow",
"target": "api.openai.com"
},
{
"action": "allow",
"target": "*.pypi.org"
},
{
"action": "allow",
"target": "*.npmjs.org"
}
]
}
这份配置的含义很明确:
- 默认拒绝所有外连请求;
- 允许访问
api.openai.com; - 允许访问 Python 包仓库相关域名;
- 允许访问 npm 包仓库相关域名。
白名单模式更适合生产环境。它的代价是配置要更细,依赖安装、镜像拉取、测试回调等地址都要提前考虑,否则任务会因为网络被拦截而失败。
沙箱入口代理:让外部访问沙箱内服务
有些 Agent 任务不只是跑一个命令,还会在沙箱里启动服务。例如:
- 启动一个 Web 应用让用户预览;
- 运行浏览器自动化服务;
- 起一个临时 API 服务供评测程序调用;
- 打开远程开发环境或调试端口。
如果每个沙箱都暴露端口,平台侧会很难管理路由、认证和生命周期。OpenSandbox 提供入口代理能力,把外部流量统一转发到对应沙箱内部服务。
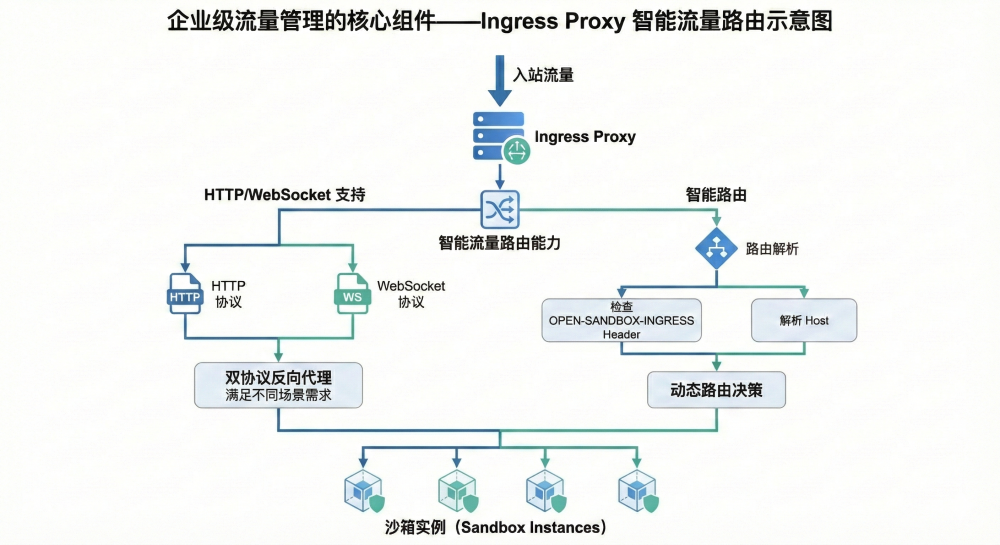
入口代理相当于沙箱内服务的统一门面。上层应用拿到代理地址后,不需要知道沙箱实际运行在哪个节点、端口怎么映射、实例何时迁移。代理层负责把请求送到对应沙箱,并配合生命周期管理在沙箱销毁后关闭入口。
flowchart LR
U[用户 / 评测系统] --> P[OpenSandbox 入口代理]
P --> S1[沙箱 A 内部服务]
P --> S2[沙箱 B 内部服务]
P --> S3[沙箱 C 内部服务]
S1 --> A1[Web 预览]
S2 --> A2[浏览器自动化]
S3 --> A3[远程 Agent]
这类能力对 Coding Agent 很重要。Agent 改完代码后,可以在沙箱里启动应用,再把预览地址返回给用户;用户访问的是代理地址,而不是直接访问容器内部网络。
Python SDK 使用方式
OpenSandbox 的 SDK 把“创建沙箱、执行命令、写文件、运行代码、清理环境”包装成一套异步 API。以 Python 为例,基本流程是:
- 选择沙箱镜像;
- 创建沙箱实例;
- 在沙箱中执行命令;
- 写入或读取文件;
- 创建代码解释器并运行代码;
- 任务完成后销毁沙箱。
import asyncio
from datetime import timedelta
from opensandbox import Sandbox
from opensandbox.models import WriteEntry
from code_interpreter import CodeInterpreter, SupportedLanguage
SANDBOX_IMAGE = (
"sandbox-registry.cn-zhangjiakou.cr.aliyuncs.com/"
"opensandbox/code-interpreter:latest"
)
async def main() -> None:
sandbox = await Sandbox.create(
SANDBOX_IMAGE,
entrypoint=["/opt/opensandbox/code-interpreter.sh"],
env={"PYTHON_VERSION": "3.11"},
timeout=timedelta(minutes=10),
)
try:
async with sandbox:
command_result = await sandbox.commands.run(
"echo 'Hello OpenSandbox'"
)
if command_result.logs.stdout:
print(command_result.logs.stdout[0].text)
await sandbox.files.write_files(
[
WriteEntry(
path="/tmp/hello.txt",
data="Hello World",
mode=0o644,
)
]
)
content = await sandbox.files.read_file("/tmp/hello.txt")
print(f"file content: {content}")
interpreter = await CodeInterpreter.create(sandbox)
code_result = await interpreter.codes.run(
"""
import sys
print(sys.version)
result = 2 + 2
result
""",
language=SupportedLanguage.PYTHON,
)
if code_result.result:
print(f"code result: {code_result.result[0].text}")
if code_result.logs.stdout:
print(f"stdout: {code_result.logs.stdout[0].text}")
finally:
await sandbox.kill()
if __name__ == "__main__":
asyncio.run(main())
这段代码里有几个关键点:
Sandbox.create()创建的是隔离执行环境,不是在本机直接运行命令;timeout用来限制沙箱生命周期,避免任务无限占用资源;sandbox.commands.run()适合跑 shell 命令;sandbox.files.write_files()和read_file()用来传递输入、读取输出;CodeInterpreter.create()把代码执行能力绑定到同一个沙箱;sandbox.kill()要放进清理逻辑里,防止异常时沙箱遗留。
在生产系统里,还应把 CPU、内存、磁盘、网络、最大运行时长都配置成明确上限。沙箱不是万能安全边界,运行时配置越宽,风险也越大。
典型使用场景
OpenSandbox 的价值集中在“Agent 需要动手执行任务”的场景。
1. Coding Agent
Coding Agent 需要读写代码、安装依赖、跑测试、启动应用。把它放在用户本机上会遇到环境污染和权限问题;放在沙箱中,可以让每个会话拥有独立工作区。
flowchart LR
U[用户指令] --> A[Coding Agent]
A --> S[OpenSandbox]
S --> F[代码文件]
S --> T[测试命令]
S --> P[应用预览]
F --> A
T --> A
P --> U
这种模式下,本地只负责交互和展示,真正的代码执行发生在远程隔离环境里。会话恢复能力也更容易设计:沙箱状态可以和会话绑定,用户回来后继续使用同一个工作区,或者从快照恢复。
2. Coding 产品评测
评测 Coding 产品时,核心要求是环境一致、结果可复现、并发足够高。单机顺序执行会很慢,而且环境容易互相污染。
OpenSandbox 可以作为底层沙箱基础设施,为评测框架提供大量独立环境。每个评测样本对应一个沙箱,输入相同、初始环境相同,评测结果才有比较意义。
flowchart TB
E[评测调度器] --> T1[任务 1]
E --> T2[任务 2]
E --> T3[任务 N]
T1 --> S1[沙箱 1]
T2 --> S2[沙箱 2]
T3 --> S3[沙箱 N]
S1 --> R[结果收集]
S2 --> R
S3 --> R
如果结合 Kubernetes,评测系统可以把大量任务并行分发到沙箱池中,用集群资源换取更短的评测时间。
3. Agentic RL 训练环境
强化学习(Reinforcement Learning,RL)训练 Agent 时,需要让 Agent 高频地与环境交互,收集大量样本。环境如果不隔离,样本会互相干扰;环境启动太慢,训练吞吐也会被拖住。
OpenSandbox 在这类场景中主要提供四件事:
| 能力 | 对训练的作用 |
|---|---|
| 高并发沙箱 | 同时运行大量环境,提高样本采集速度 |
| 资源池化 | 减少环境分配等待时间 |
| 状态隔离 | 每个训练环境互不影响,结果更容易复现 |
| 弹性回收 | 根据训练负载释放空闲资源,降低集群浪费 |
这类任务对调度系统要求很高,因为它不是偶尔跑几个命令,而是持续创建、分配、回收大量执行环境。
4. Remote Agent Sandbox
Claude Code、Gemini CLI 等工具可以被封装进远程沙箱。用户本地只发送指令和接收结果,Agent 的文件操作、命令执行、依赖安装都发生在远程环境中。
这种方式解决了两个常见问题:
- 本地环境不需要安装大量语言版本、依赖包和工具链;
- Agent 无法直接读取本机敏感文件,也不会污染本机系统。
适合与不适合的场景
| 场景 | 是否适合 | 原因 |
|---|---|---|
| AI 编程助手执行代码和测试 | 适合 | 需要隔离文件系统、依赖和运行结果 |
| 大规模代码评测 | 适合 | 需要大量一致、可复现、可销毁的环境 |
| Agentic RL 样本采集 | 适合 | 需要高并发环境和状态隔离 |
| 浏览器自动化任务 | 适合 | 需要受控网络和独立浏览器运行环境 |
| 简单文本生成 | 不一定需要 | 没有代码执行和外部动作时,沙箱收益有限 |
| 强依赖本机硬件或桌面交互的任务 | 需要评估 | 远程沙箱可能无法直接访问本机设备 |
| 需要长期保存状态的传统服务 | 需要谨慎 | 沙箱更适合临时任务,持久化要单独设计 |
使用时容易踩的坑
不要把宿主机目录和密钥随意挂进去
如果把宿主机工作目录、SSH 密钥、云厂商凭证直接挂进沙箱,隔离效果会大幅下降。更稳妥的做法是只复制任务所需文件,敏感凭证通过短期、最小权限方式发放。
网络策略要默认拒绝
默认允许所有外连会带来数据泄露风险。更安全的方式是默认拒绝,再按任务白名单开放域名。依赖仓库、模型 API、测试目标站点都应该显式配置。
沙箱要有明确生命周期
每个沙箱都应有超时时间和清理逻辑。任务异常、连接中断、Agent 死循环时,平台仍然要能回收资源。
镜像要可控
沙箱镜像决定了基础环境。生产环境里应固定镜像版本,避免每次拉取 latest 带来不可预期变化;依赖包来源也要尽量可审计。
资源限制不能省
CPU、内存、磁盘、进程数、运行时长都要设置上限。尤其是面向外部用户或多租户平台时,资源限制本身就是安全边界的一部分。
项目信息
OpenSandbox 使用 Apache 2.0 协议开源,可以用于个人和商业项目。
GitHub 地址:
https://github.com/alibaba/OpenSandbox
把 AI Agent 放进真实执行环境时,沙箱不是可选项,而是基础设施。OpenSandbox 提供的统一协议、多语言 SDK、Docker 与 Kubernetes 双运行时、网络控制和入口代理,正好覆盖了 Agent 从“能执行”走向“可控执行”所需要的关键能力。