大语言模型本身并不会天然“记住”用户。一次对话里输入过的内容,可以通过上下文窗口传给模型;但新的会话开始后,历史上下文通常就消失了。即使模型支持很长的上下文,把所有历史消息都塞进去也不是一个好办法:token 成本会越来越高,模型也未必能稳定抓住真正重要的信息。
长期记忆层要解决的就是这个问题:把对话中值得长期保留的事实、偏好、关系和经验抽取出来,持久化保存;之后用户再次提问时,只召回和当前问题相关的记忆,再注入到模型提示词里。
Mem0 是一个面向 AI Agent 的记忆层框架,Milvus 是向量数据库。两者组合起来,可以形成一套比较清晰的长时记忆链路:
flowchart LR
A[用户输入] --> B[Mem0 抽取长期记忆]
B --> C[Embedding 模型向量化]
C --> D[(Milvus 向量数据库)]
A --> E[Mem0 检索相关记忆]
D --> E
E --> F[拼接到 Prompt]
F --> G[LLM 生成回答]
G --> B
为什么不能只依赖 LLM 上下文窗口
LLM(Large Language Model,大语言模型)的上下文窗口适合保存当前对话里的临时信息,比如刚刚说过的需求、上一轮工具调用结果、正在执行的任务状态。但它不适合作为长期记忆系统。
原因主要有三个:
-
会话结束后上下文会丢失
大多数应用里,一次请求只会携带当前会话的消息列表。新开会话后,如果应用没有额外保存和注入历史内容,模型并不知道用户以前说过什么。 -
把全部历史塞进上下文会浪费 token
用户可能聊过很多内容,但当前问题只需要其中一小部分。如果每次都把完整历史传给模型,成本和延迟都会随对话增长。 -
长上下文不等于稳定记忆
模型面对很长的输入时,可能忽略中间细节,也可能无法区分哪些信息是长期事实、哪些只是临时表达。
Mem0 的位置可以理解为上下文窗口之外的一层持久化记忆系统。当前轮对话只保留必要上下文,跨会话信息由 Mem0 负责存取。
这张图展示了没有记忆层和引入记忆层后的区别:

没有记忆层时,模型只能看到当前请求携带的上下文;有 Mem0 之后,历史对话中被抽取出来的重要信息会进入持久化存储,后续对话可以按需召回。这样,用户不需要重复说明自己的偏好,应用也不需要把所有历史消息都塞进上下文窗口。
Mem0 在 Agent 架构里的位置
RAG(Retrieval-Augmented Generation,检索增强生成)常用于从文档库中检索外部知识,再辅助模型回答问题。Mem0 和 RAG 都会用到检索,但目标不同。
RAG 更像“查资料”:它面向相对静态的知识库,比如产品文档、企业制度、论文、代码仓库。Mem0 更像“记住用户和交互过程”:它面向动态产生的个人偏好、事实、行为记录和跨会话上下文。
Mem0 在 Agent 中通常和上下文、检索器、LLM 一起工作:
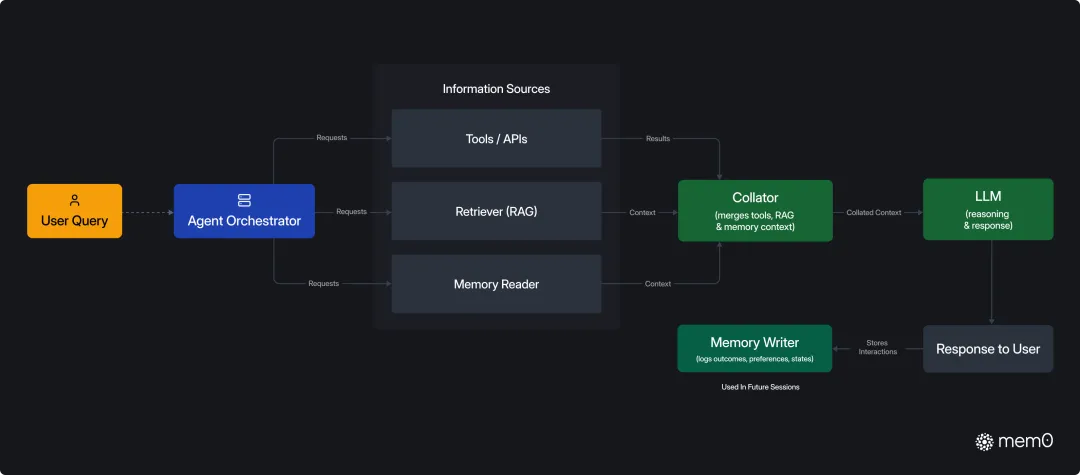
这套结构里,Mem0 不会把所有历史对话原封不动地传给模型,而是根据当前输入检索相关记忆,然后把少量高相关内容合并到 prompt 中。这样既能保持个性化,又能控制 token 消耗。
LLM 上下文窗口和 Mem0 记忆存储的差异可以放在一张表里看:
| 对比项 | LLM 上下文窗口 | Mem0 记忆存储 |
|---|---|---|
| 生命周期 | 当前请求或当前会话 | 跨会话持久化 |
| 存储内容 | 原始消息居多 | 抽取后的事实、偏好、关系 |
| token 消耗 | 历史越长消耗越高 | 只召回相关记忆 |
| 召回方式 | 依赖模型从长上下文里理解 | 通过语义检索找到相关内容 |
| 个性化能力 | 需要每次重新输入背景 | 可持续记录用户偏好 |
| 更新方式 | 请求结束后通常不保留 | 每次交互后可新增、更新或合并记忆 |
Mem0 和传统 RAG 的区别
Mem0 并不是把 RAG 换个名字。它更关注“长期交互中不断变化的信息”,而不是只检索一批静态文档。
| 能力 | 传统 RAG | Mem0 记忆层 |
|---|---|---|
| 数据来源 | 文档、网页、知识库 | 用户对话、Agent 行为、历史交互 |
| 更新频率 | 通常批量导入或定期更新 | 每次交互后都可以更新 |
| 信息类型 | 外部知识 | 用户偏好、事实、关系、经验 |
| 检索目标 | 找到能回答问题的资料片段 | 找到和当前用户、当前情境相关的记忆 |
| 个性化 | 依赖额外用户画像或过滤条件 | 记忆天然按 user_id 等维度隔离 |
| 关系表达 | 主要依赖文本相似度 | 可结合图谱记忆表达实体关系 |
举个例子,用户说过:“我不喜欢惊悚片,更喜欢轻松一点的电影。”
这句话放在 RAG 里不像一份知识文档,但对一个推荐型 Agent 很重要。Mem0 会把它抽取成长期偏好,之后用户问“周末看什么电影”时,系统可以主动避开惊悚片。
Mem0 的核心工作流程
Mem0 的记忆流程可以拆成写入和读取两条链路。
写入时,系统从用户输入和模型回答中抽取值得保存的信息;读取时,系统根据当前问题检索相关记忆并注入 prompt。
flowchart TD
A[用户与 Agent 对话] --> B[LLM 判断哪些信息值得保存]
B --> C[抽取事实、偏好、关系]
C --> D[Embedding 模型生成向量]
D --> E[(Milvus 存储向量和元数据)]
F[新的用户问题] --> G[Embedding 模型生成查询向量]
G --> H[Milvus 相似度检索]
H --> I[取回相关记忆]
I --> J[合并到系统提示词]
J --> K[LLM 生成个性化回答]
核心步骤如下:
| 步骤 | 作用 |
|---|---|
| 语义捕获 | 使用 LLM 从会话里提取长期有价值的信息,例如偏好、身份、关系、约束 |
| 内容向量化 | 使用 Embedding 模型把文本记忆编码成向量 |
| 向量存储 | 把向量、记忆文本、用户标识、元数据写入 Milvus |
| 语义检索 | 新问题到来后,根据向量相似度检索相关历史记忆 |
| 上下文增强 | 把检索到的记忆合并到 prompt,让 LLM 生成更贴合用户背景的回答 |
| 记忆更新 | 对新交互继续抽取,新增、合并或更新记忆 |
这里的关键点是:Mem0 保存的不是完整聊天记录,而是经过抽取和压缩后的“记忆”。这会让检索更接近用户真实意图,也更容易控制上下文长度。
Milvus 为什么适合作为记忆存储
Mem0 需要一个能存储向量并做语义相似度搜索的数据库。Milvus 的核心能力正好覆盖这个需求:大规模向量存储、向量索引、低延迟检索、分布式扩展。
Milvus 是面向向量相似性搜索的数据库,常见能力包括:
- ANN(Approximate Nearest Neighbor,近似最近邻)搜索:通过 HNSW、IVF、PQ 等索引算法,在速度和召回精度之间做平衡。
- 多种索引类型:例如 FLAT、IVF_FLAT、IVF_PQ、HNSW,适配不同数据规模和延迟要求。
- 分片与并行查询:向量数据可以分片存储,并通过分布式执行提高吞吐。
- 存算分离架构:计算节点和存储层解耦,便于按负载扩缩容。
阿里云 Milvus 的架构可以分成接入、协调、执行、存储几层:
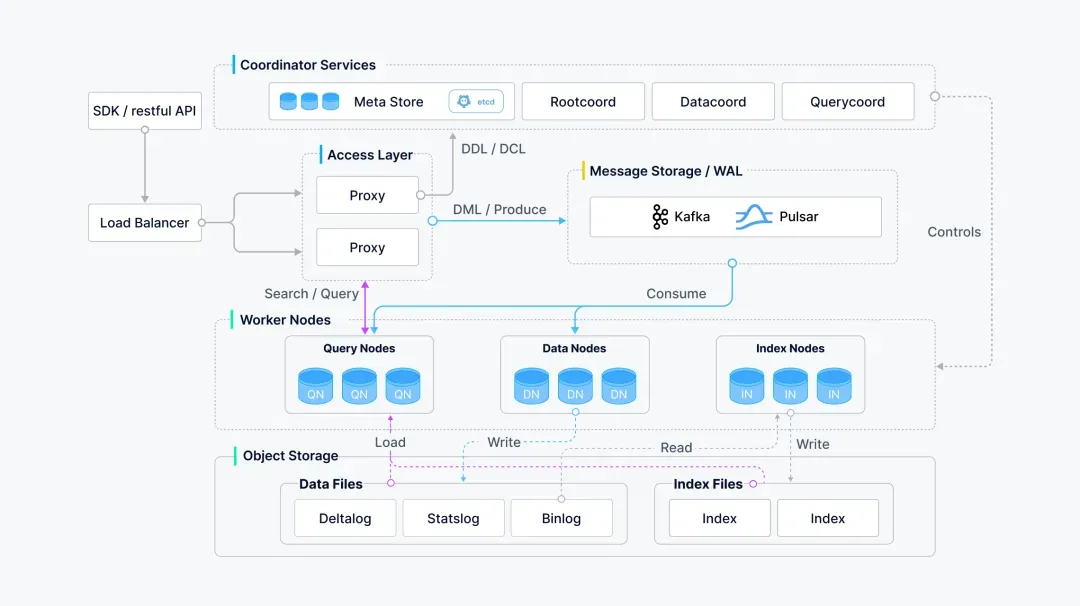
接入层负责处理客户端请求,协调层负责元数据、任务调度和集群状态管理,执行层负责写入、索引和查询,存储层则保存对象数据、元数据和消息队列中的中间数据。对 Mem0 来说,Milvus 主要承担两件事:保存记忆向量,以及按当前问题做相似度检索。
Milvus 不只适用于 AI 记忆,也适合所有需要“找相似内容”的场景:
| 场景 | 检索对象 |
|---|---|
| 文本语义搜索 | 文档片段、问答、代码、知识库内容 |
| 图片和视频搜索 | 图片特征、视频帧特征、人脸特征 |
| 推荐系统 | 用户兴趣向量、商品向量、内容向量 |
| 安全检测 | 异常行为特征、欺诈模式、流量特征 |
| 多模态数据挖掘 | 点云、图像、音频、传感器数据 |
实践一:用 Mem0、Milvus 和 LangGraph 构建长期记忆 Agent
目标是构建一个简单的客服式对话 Agent。它可以在第一轮对话中记住用户偏好,并在后续重新启动程序后,从 Milvus 里召回相关记忆。
准备条件
需要准备:
- Python 3.10 或更高版本
- 一个可访问的 Milvus 实例
- DashScope API Key
- Mem0、LangGraph、LangChain OpenAI 兼容客户端
安装依赖:
pip install langgraph langchain-openai mem0ai
DashScope 提供 OpenAI 兼容调用方式,可以通过环境变量配置:
export DASHSCOPE_API_KEY="sk-xxxxxxxx"
export OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
生产环境不要把 API Key 直接写进代码,可以使用环境变量、密钥管理服务或配置中心。
配置 Mem0
Mem0 的配置里有三块最重要:
| 配置项 | 作用 |
|---|---|
| llm | 用于记忆抽取、合并和判断 |
| embedder | 把记忆文本转换成向量 |
| vector_store | 保存和检索记忆向量,这里使用 Milvus |
示例配置:
import os
from mem0 import Memory
os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY", "")
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
mem0_config = {
"llm": {
"provider": "openai",
"config": {
"model": "qwen-plus",
"temperature": 0.2,
"max_tokens": 2000,
},
},
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-v3",
"embedding_dims": 128,
},
},
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "mem0_agent_memory",
"embedding_model_dims": 128,
"url": "http://c-xxx.milvus.aliyuncs.com:19530",
"token": "root:xxx",
"db_name": "default",
},
},
"version": "v1.1",
}
memory = Memory.from_config(mem0_config)
embedding_dims 和 Milvus collection 中的向量维度必须一致。如果已经创建过 collection,再改 embedding 维度,通常需要重新建 collection,否则写入或检索时会出现维度不匹配错误。
用 LangGraph 编排对话流程
LangGraph 用来描述 Agent 的状态和节点。这个示例只有一个节点:收到用户输入后,先从 Mem0 检索相关记忆,再调用 LLM 生成回答,最后把本轮交互写回 Mem0。
import os
from typing import Annotated, TypedDict
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import END, START, StateGraph
from langgraph.graph.message import add_messages
from mem0 import Memory
os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY", "")
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
llm = ChatOpenAI(
model="qwen-plus",
temperature=0.2,
max_tokens=2000,
)
mem0_config = {
"llm": {
"provider": "openai",
"config": {
"model": "qwen-plus",
"temperature": 0.2,
"max_tokens": 2000,
},
},
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-v3",
"embedding_dims": 128,
},
},
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "mem0_agent_memory",
"embedding_model_dims": 128,
"url": "http://c-xxx.milvus.aliyuncs.com:19530",
"token": "root:xxx",
"db_name": "default",
},
},
"version": "v1.1",
}
memory = Memory.from_config(mem0_config)
class State(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
mem0_user_id: str
def normalize_memories(search_result):
"""兼容不同 Mem0 版本的 search 返回结构。"""
if isinstance(search_result, dict):
return search_result.get("results", [])
return search_result or []
def build_memory_context(memories: list[dict]) -> str:
if not memories:
return "No relevant long-term memory found."
lines = []
for item in memories:
text = item.get("memory") or item.get("text") or str(item)
score = item.get("score")
if score is None:
lines.append(f"- {text}")
else:
lines.append(f"- {text} (score={score:.4f})")
return "\n".join(lines)
def chatbot(state: State):
messages = state["messages"]
user_id = state["mem0_user_id"]
latest_user_message = messages[-1].content
search_result = memory.search(
latest_user_message,
user_id=user_id,
)
memories = normalize_memories(search_result)
memory_context = build_memory_context(memories)
system_message = SystemMessage(
content=f"""
You are a helpful customer support assistant.
Use the long-term memory below only when it is relevant to the user's current request.
Do not expose internal memory IDs or vector search details to the user.
Long-term memory:
{memory_context}
""".strip()
)
response = llm.invoke([system_message] + messages)
interaction = [
{"role": "user", "content": latest_user_message},
{"role": "assistant", "content": response.content},
]
save_result = memory.add(
interaction,
user_id=user_id,
)
added = 0
if isinstance(save_result, dict):
added = len(save_result.get("results", []))
print(f"[memory] saved {added} memories")
return {"messages": [AIMessage(content=response.content)]}
graph = StateGraph(State)
graph.add_node("chatbot", chatbot)
graph.add_edge(START, "chatbot")
graph.add_edge("chatbot", END)
compiled_graph = graph.compile()
def run_conversation(user_input: str, mem0_user_id: str):
state = {
"messages": [HumanMessage(content=user_input)],
"mem0_user_id": mem0_user_id,
}
for event in compiled_graph.stream(state):
for value in event.values():
if value.get("messages"):
answer = value["messages"][-1].content
print(f"Assistant: {answer}")
if __name__ == "__main__":
user_id = "alice"
print("Customer Support is ready. Type 'exit' to quit.")
while True:
user_input = input("You: ").strip()
if user_input.lower() in {"quit", "exit", "bye"}:
print("Assistant: Thank you. Have a great day!")
break
run_conversation(user_input, user_id)
这个流程里有两个关键调用:
memory.search(latest_user_message, user_id=user_id)
它负责按用户隔离检索相关长期记忆。
memory.add(interaction, user_id=user_id)
它负责把本轮用户输入和模型回答交给 Mem0,由 Mem0 判断哪些内容值得保存,再写入 Milvus。
第一次对话:写入用户偏好
可以先输入一段带有明确偏好的话:
You: 我想看一部轻松一点的电影,不要惊悚片。我比较喜欢喜剧或者温馨的家庭片。
模型正常回答后,控制台会出现类似日志:
[memory] saved 2 memories
这表示 Mem0 从交互中提取出了可长期保存的信息。此时进入 Milvus collection,可以看到已经产生了对应实体。
Milvus 中的记录会保存记忆内容、用户标识、元数据和向量字段:
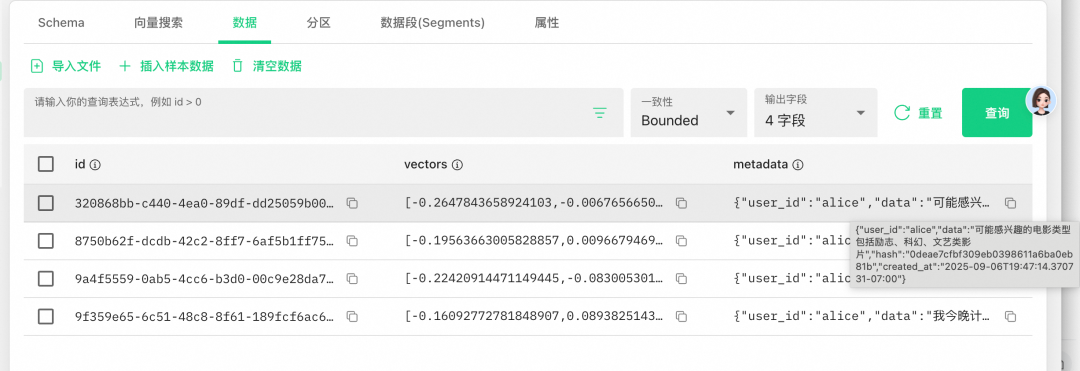
这里最重要的是两类字段:一类是可读的元数据,比如用户是谁、记忆文本是什么;另一类是向量字段,用于后续相似度检索。Mem0 检索时会把用户的新问题向量化,再到 Milvus 中找语义最接近的记忆。
重新启动后:召回历史记忆
停止程序后重新启动,再输入:
You: 我喜欢什么类型的电影?
因为用户 ID 仍然是 alice,Mem0 会从 Milvus 中检索到之前保存的电影偏好,并把它注入到系统提示词中。
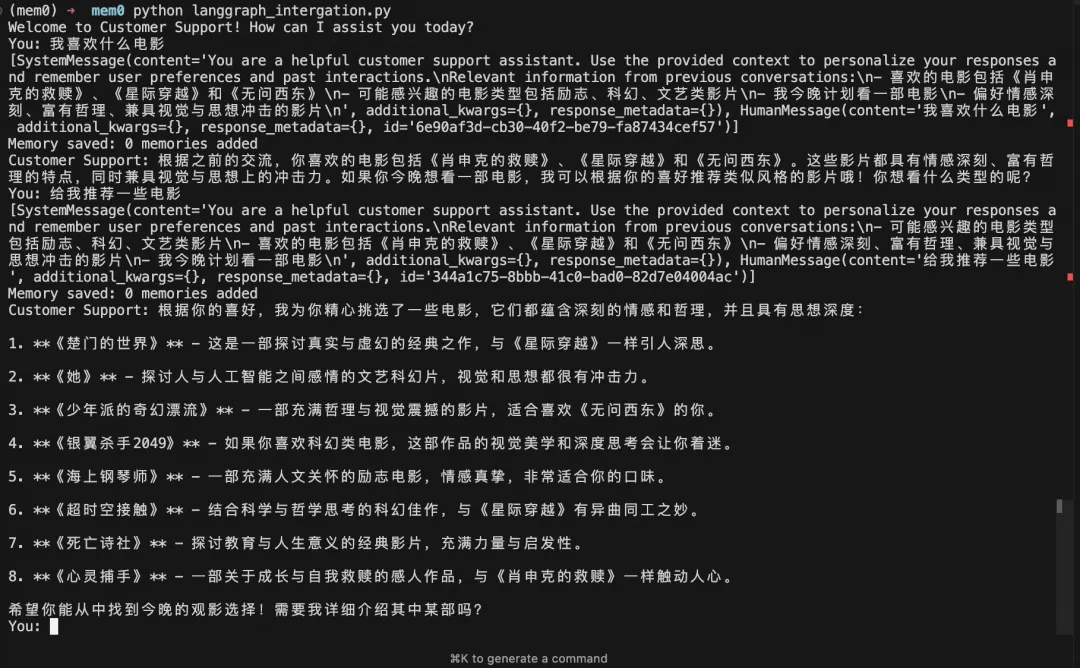
从这个结果可以看出,模型不需要用户再次说明“不喜欢惊悚片、喜欢轻松电影”,仍然可以基于历史偏好回答。这里的记忆不是保存在 Python 进程内存里,而是持久化在 Milvus 中,所以程序重启后依然可用。
实践二:用图谱记忆补充实体关系推理
向量检索擅长找语义相似内容,但它不总是擅长处理清晰的实体关系问题。
例如:
我的朋友彼得是蜘蛛侠。
当用户问:
谁是蜘蛛侠?
向量检索可能能找到相似句子,但它并没有显式理解“彼得”和“蜘蛛侠”之间的关系。如果记忆系统能把这句话解析成三元组:
彼得 -> 是 -> 蜘蛛侠
检索会更直接。
Mem0 支持图谱记忆(Graph Memory)。它可以在写入记忆时,同时做两件事:
- 把文本记忆向量化后写入 Milvus;
- 从文本中提取实体和关系,写入图数据库。
写入链路如下:
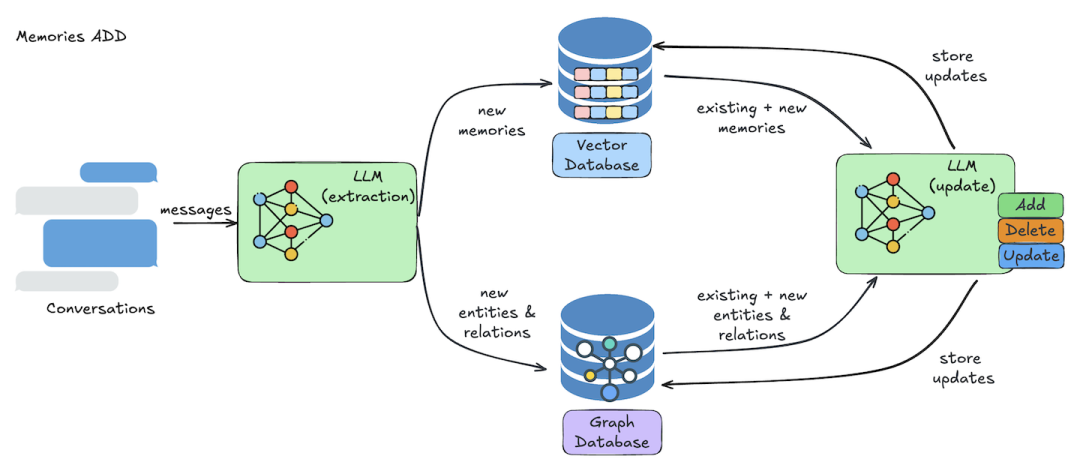
这张图表达的是双写过程:Mem0 使用 LLM 抽取记忆后,一路生成 embedding 写入向量库,另一路抽取实体和关系写入图数据库。向量库负责语义相似检索,图数据库负责关系查询。
检索时也会走双路:
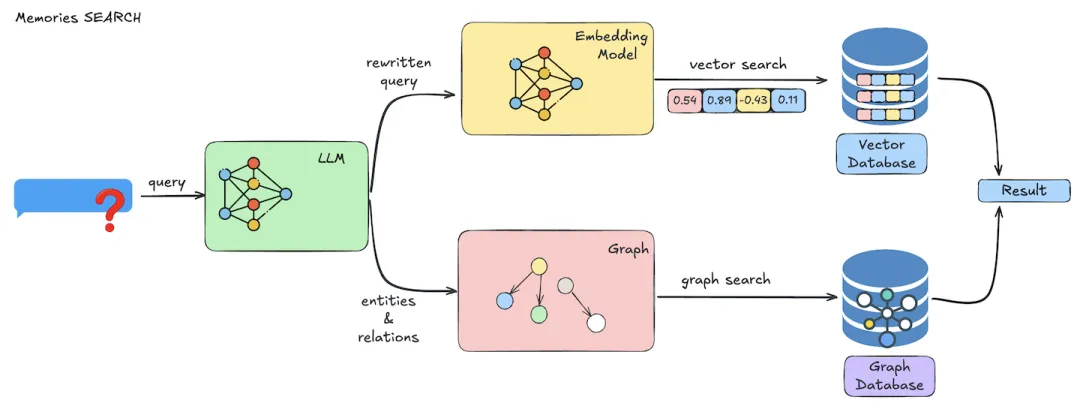
用户问题进入 Mem0 后,一路被向量化并到 Milvus 检索相似记忆,另一路被解析成实体或关系查询并到图数据库检索。两个结果合并后返回给应用,模型就能同时利用语义相似信息和结构化关系信息。
安装依赖
这里使用 Kuzu 作为本地图数据库:
pip install kuzu rank-bm25 mem0ai
如果代码中还要直接使用 LangChain 的 OpenAI 兼容客户端,可以额外安装:
pip install langchain-openai
配置向量库和图数据库
配置比纯向量记忆多了一个 graph_store:
import json
import os
from mem0 import Memory
os.environ["OPENAI_API_KEY"] = os.getenv("DASHSCOPE_API_KEY", "")
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"
config = {
"llm": {
"provider": "openai",
"config": {
"model": "qwen-plus",
"temperature": 0.2,
"max_tokens": 2000,
},
},
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-v3",
"embedding_dims": 128,
},
},
"vector_store": {
"provider": "milvus",
"config": {
"collection_name": "mem0_graph_memory",
"embedding_model_dims": 128,
"url": "http://c-xxx.milvus.aliyuncs.com:19530",
"token": "root:xxx",
"db_name": "default",
},
},
"graph_store": {
"provider": "kuzu",
"config": {
"db": "./mem0-example.kuzu",
},
},
"version": "v1.1",
}
memory = Memory.from_config(config)
graph_store 指向本地 Kuzu 数据库路径。生产环境如果需要多人协作、备份、权限控制和高可用,需要换成适合线上部署的图数据库方案。
写入测试数据
写入一些带有偏好、身份和朋友关系的句子:
user_id = "alice123"
memory.add("我喜欢去徒步旅行", user_id=user_id)
memory.add("我喜欢打羽毛球", user_id=user_id)
memory.add("我讨厌打羽毛球", user_id=user_id)
memory.add("我的朋友叫约翰,约翰有一只叫汤米的狗", user_id=user_id)
memory.add("我的名字是爱丽丝", user_id=user_id)
memory.add("约翰喜欢徒步旅行,哈利也喜欢徒步旅行", user_id=user_id)
memory.add("我的朋友彼得是蜘蛛侠", user_id=user_id)
这些数据里有几类信息:
| 句子 | 可能形成的记忆 |
|---|---|
| 我喜欢去徒步旅行 | 用户偏好:喜欢徒步 |
| 我的名字是爱丽丝 | 用户身份:名字是爱丽丝 |
| 约翰有一只叫汤米的狗 | 实体关系:约翰拥有汤米 |
| 彼得是蜘蛛侠 | 实体关系:彼得是蜘蛛侠 |
为了更方便观察返回结果,可以按分数排序后打印:
def print_ranked(result):
if isinstance(result, dict) and "results" in result:
result["results"] = sorted(
result["results"],
key=lambda item: item.get("score", 0),
reverse=True,
)
print(json.dumps(result, ensure_ascii=False, indent=2))
print_ranked(memory.search("我的名字是什么?", user_id=user_id))
print_ranked(memory.search("谁是蜘蛛侠?", user_id=user_id))
查询身份关系
查询:
我的名字是什么?
返回结果中通常会包含两部分:results 是向量检索结果,relations 是图谱关系结果。
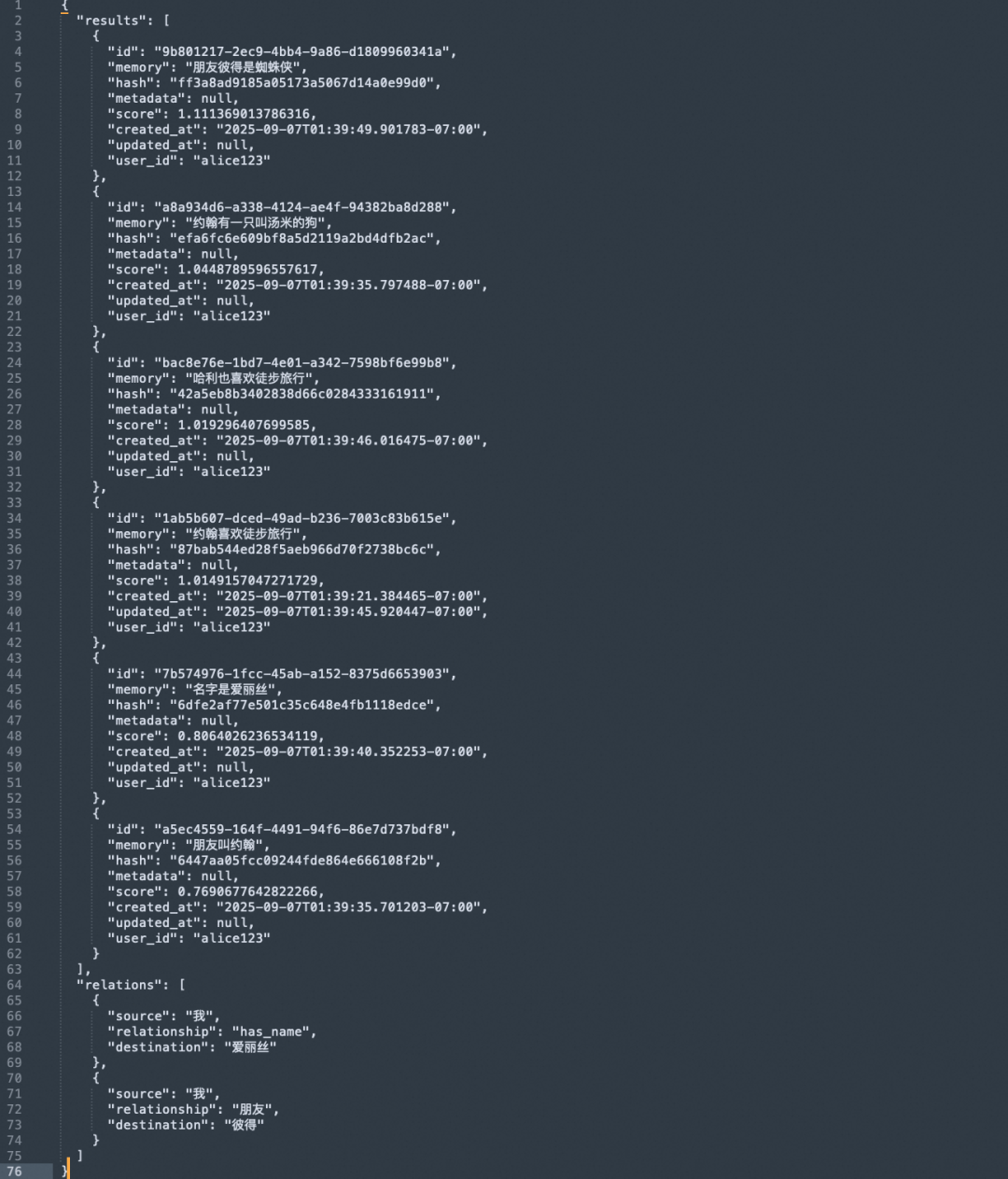
向量检索可能会返回“我的名字是爱丽丝”这类相似记忆,但分数不一定总是最高;图谱结果可以把“我”和“爱丽丝”的关系表达得更明确,例如 has_name。对于身份、所有权、亲属、朋友、从属这类关系,图谱结果通常比纯相似度更容易解释。
查询实体别名或身份
查询:
谁是蜘蛛侠?
返回结果如下:
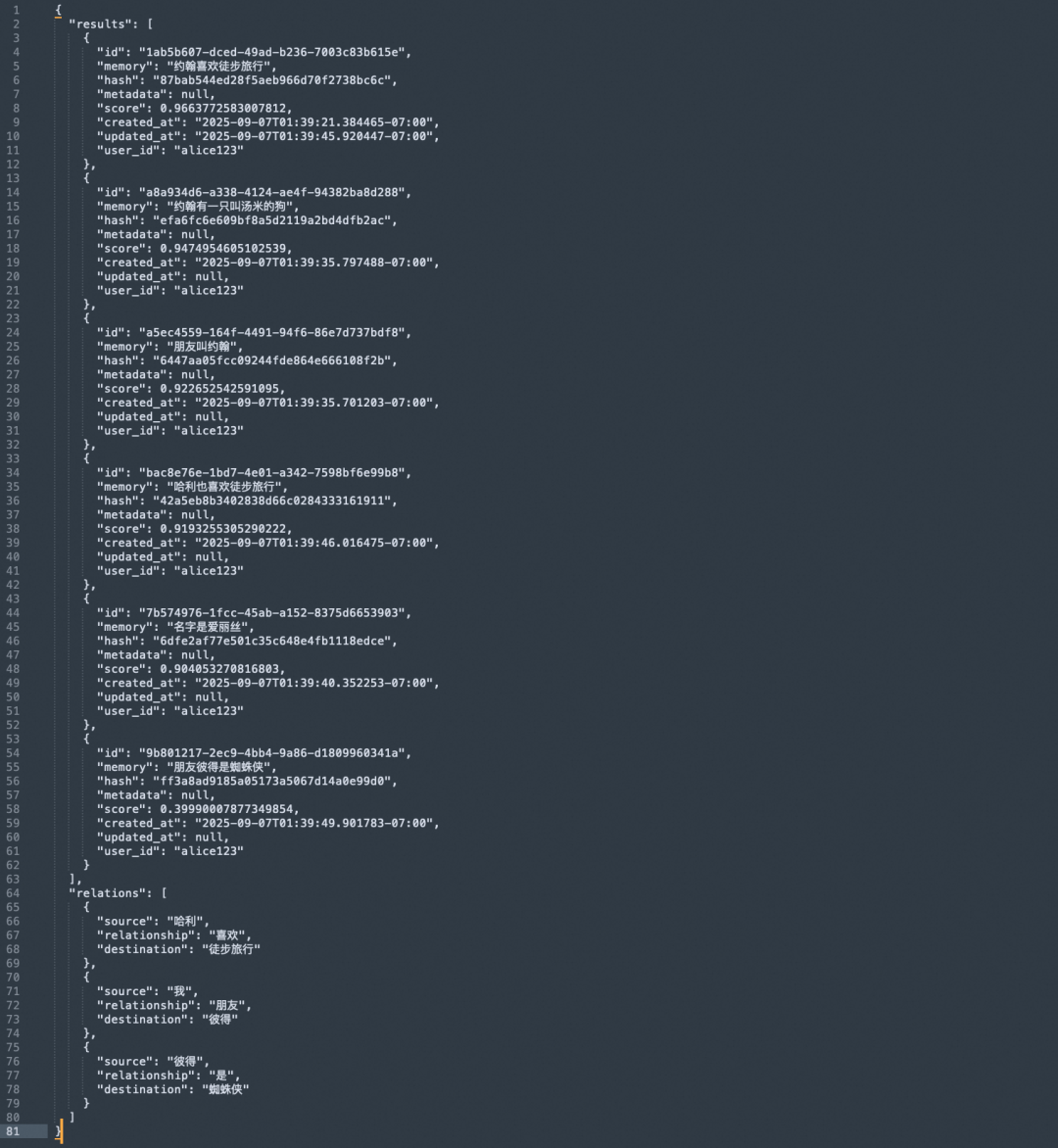
向量检索可以找到包含“蜘蛛侠”的句子,但图谱关系能更直接地给出“彼得 是 蜘蛛侠”。这种结构化关系对问答很有价值,因为模型不需要只依赖相似文本去猜测答案,而是可以读取明确的实体关系。
向量记忆和图谱记忆怎么选
不是所有长期记忆都需要图谱。选择方式可以按问题类型判断。
| 需求 | 推荐方案 | 原因 |
|---|---|---|
| 记住用户偏好 | 向量记忆 | 偏好表达通常是自然语言,语义检索足够好用 |
| 记住历史任务摘要 | 向量记忆 | 摘要内容更适合按相似度召回 |
| 查询人物、组织、物品关系 | 图谱记忆 + 向量记忆 | 图谱能显式表示实体关系 |
| 处理“谁是谁”“谁拥有什么” | 图谱记忆 | 关系查询比相似度匹配更稳定 |
| 构建普通客服知识库 | RAG + 向量库 | 主要检索静态文档,不一定需要用户长期记忆 |
| 构建个人助手或陪伴型 Agent | Mem0 + 向量库,可叠加图谱 | 需要跨会话保存用户状态和偏好 |
一个实用组合是:
flowchart LR
A[静态产品文档] --> B[RAG 知识库]
C[用户历史交互] --> D[Mem0 长期记忆]
D --> E[(Milvus)]
D --> F[(Graph Store)]
B --> G[Prompt]
E --> G
F --> G
G --> H[LLM]
静态知识交给 RAG,用户长期信息交给 Mem0。需要关系推理时,再给 Mem0 增加图谱存储。
常见坑和工程建议
user_id 必须稳定且隔离
Mem0 检索和写入都应该带上 user_id:
memory.search(query, user_id="alice")
memory.add(messages, user_id="alice")
如果多个用户共用同一个 ID,记忆会串;如果同一个用户每次使用随机 ID,系统就无法召回历史记忆。实际业务里通常会使用登录用户 ID、租户 ID、设备 ID 或它们的组合。
Embedding 维度要保持一致
Embedding 模型输出维度必须和 Milvus collection 的向量字段维度一致。比如配置了:
"embedding_dims": 128
Milvus 中对应 collection 的向量维度也要是 128。维度不一致会导致插入失败或检索失败。
不要把所有记忆都注入 prompt
长期记忆不是越多越好。每次只应该注入和当前问题相关的少量记忆,否则会重新制造长上下文问题。
可以控制:
- 检索 top_k;
- 最低相似度阈值;
- 记忆类型过滤;
- 时间范围;
- 用户或租户隔离条件。
记忆内容要当作不可信输入处理
用户说过的话会进入记忆系统,如果直接把记忆无条件放进系统提示词,可能出现记忆污染或提示词注入问题。
更稳妥的方式是:
- 在系统提示词中说明“记忆只作为参考,不覆盖安全规则”;
- 对敏感指令类记忆做过滤;
- 对关键事实增加确认机制;
- 给用户提供查看、删除记忆的能力。
矛盾记忆需要更新策略
用户可能先说“我喜欢羽毛球”,后来又说“我讨厌羽毛球”。长期记忆系统需要决定:
- 保留两条,并按时间排序;
- 新记忆覆盖旧记忆;
- 标记冲突,等待用户确认;
- 按场景区分,例如“以前喜欢,现在不喜欢”。
Mem0 可以帮助抽取和管理记忆,但业务侧仍然要定义冲突处理策略,尤其是医疗、金融、客服工单这类严肃场景。
Milvus 索引类型要按规模选择
小规模测试可以使用简单索引,数据量上来后需要按延迟、召回率和内存占用选择索引。
| 索引 | 特点 | 适合场景 |
|---|---|---|
| FLAT | 精确搜索,速度随数据量增长变慢 | 小数据集、评估召回 |
| IVF_FLAT | 聚类后检索,速度和召回可调 | 中大型数据集 |
| IVF_PQ | 压缩向量,省存储和内存 | 超大规模、可接受一定精度损失 |
| HNSW | 图结构近邻搜索,查询快 | 低延迟检索,内存相对更高 |
小结
Mem0 负责把对话中的长期信息抽取、更新和召回,Milvus 负责持久化保存向量并提供语义检索。两者结合后,AI Agent 不再只能依赖当前上下文窗口,而是可以跨会话记住用户偏好、身份信息和历史交互。
如果应用只需要记住偏好、事实和任务摘要,Mem0 + Milvus 已经足够;如果还需要回答实体关系问题,例如“谁是谁”“谁拥有什么”“某人和某物是什么关系”,可以给 Mem0 增加图谱记忆,让向量检索和关系查询一起工作。