DeepSeek-R1 的核心价值不只是“模型会做难题”,而是展示了一条训练推理模型的路线:不把人类写好的推理过程当作唯一标准,而是让大语言模型在可验证任务里通过强化学习不断试错,逐渐形成自己的解题策略。
这条路线背后的关键问题是:如果模型总是模仿人类给出的思维链,它学到的可能只是人类已经写出来的推理模式;如果奖励信号只关心最终答案是否正确,模型就有机会探索更多解法,包括人类不一定会提前设计出来的中间步骤。
DeepSeek-R1 的训练过程可以拆成三件事:
- 用强化学习(RL,Reinforcement Learning)直接训练基础模型,让模型在数学、编程等可验证任务上通过奖励信号提升推理能力。
- 用 GRPO(Group Relative Policy Optimization,群体相对策略优化)降低强化学习训练成本,让一组回答之间相互比较,而不是额外训练一个价值模型。
- 用多阶段训练修复 R1-Zero 的可读性、语言混用和通用能力问题,最终得到更接近实际使用需求的 DeepSeek-R1。
为什么大模型推理不能只靠人工思维链
大语言模型(LLM,Large Language Model)在复杂推理任务上的一个常见做法,是让模型输出思维链(CoT,Chain-of-Thought)。思维链的直观含义是:不要只给答案,而是把中间推导步骤写出来。
例如一道数学题,如果模型直接输出 42,我们很难判断它是算出来的,还是碰巧猜中;如果模型写出分解、计算、验证过程,就更容易发现错误,也更容易让模型在中间步骤上受益。
但思维链训练有一个问题:高质量推理过程通常需要人工标注或由更强模型生成,再经过筛选。这会带来几个限制。
| 方法 | 学习信号来自哪里 | 优点 | 局限 |
|---|---|---|---|
| 基于提示的方法 | 人在提示词里告诉模型“逐步思考” | 成本低,不一定重新训练模型 | 能力受模型已有知识和提示质量影响 |
| 监督微调(SFT,Supervised Fine-Tuning) | 人工或模型生成的标准答案与推理过程 | 输出格式稳定,容易控制风格 | 依赖标注数据,可能让模型只模仿已有推理路径 |
| 强化学习 | 根据答案正确性给奖励或惩罚 | 模型可以通过试错探索策略 | 奖励设计、训练稳定性和可读性都更难处理 |
DeepSeek-R1 最值得关注的地方,是它证明了一个基础模型可以在没有人工推理过程标注的情况下,仅靠可验证任务上的奖励信号,发展出复杂推理行为。这里的“可验证”很重要:数学题可以检查最终答案,代码题可以跑测试用例,选择题可以比对标准选项。只要答案能被自动评分,强化学习就有了明确反馈。
强化学习如何训练推理能力
强化学习训练推理模型时,可以把模型看成一个玩家,把每道题看成一个关卡。模型生成回答,相当于采取一连串动作;评分器检查答案是否正确,相当于给分。正确答案得到更高奖励,错误答案得到更低奖励,模型参数再根据奖励更新。
这个过程不是告诉模型“每一步应该怎么想”,而是告诉模型“这个结果好不好”。如果某些中间推理习惯经常通向正确答案,例如自我检查、重新计算、尝试替代解法,模型就会逐渐增加这些行为出现的概率。
强化学习框架可以抽象成下面的循环:
flowchart LR
A[题目 / Prompt] --> B[大语言模型生成回答]
B --> C[自动评分器]
C --> D{奖励信号}
D -->|高奖励| E[增强类似回答的概率]
D -->|低奖励| F[降低类似回答的概率]
E --> G[更新模型参数]
F --> G
G --> B
DeepSeek-R1 的强化学习框架中,评分器主要依赖规则化反馈。数学题可以匹配最终答案,编程题可以运行测试,部分任务可以检查格式是否符合要求。这样做的好处是奖励不需要再训练一个复杂的神经网络模型,反馈来源更直接。
DeepSeek-R1 的 RL 框架如下图所示:
这套框架的关键结构是“生成—评分—更新”。模型对同一个问题生成回答,奖励模块根据答案正确性和格式要求打分,训练算法再根据奖励调整策略。久而久之,模型会倾向于输出更容易拿高分的推理过程,而不是只学习某个固定模板。
GRPO:用“组内比较”替代单独的价值模型
很多大模型强化学习方法会使用 PPO(Proximal Policy Optimization,近端策略优化)。PPO 通常需要一个价值模型来估计某个回答未来能带来多少奖励,这个价值模型本身也要训练,成本不低。
DeepSeek-R1 使用的 GRPO 思路更直接:对同一个问题一次采样多个回答,把这些回答组成一个组,然后比较它们在组内的相对表现。得分高于组平均水平的回答被强化,得分低于组平均水平的回答被抑制。
简化后的过程如下:
for prompt in prompts:
answers = policy.sample(prompt, n=group_size)
rewards = []
for answer in answers:
reward = rule_based_score(prompt, answer)
rewards.append(reward)
mean_reward = mean(rewards)
std_reward = std(rewards)
advantages = []
for reward in rewards:
advantage = (reward - mean_reward) / (std_reward + 1e-8)
advantages.append(advantage)
policy.update(prompt, answers, advantages)
GRPO 的核心不是“这个回答绝对有多好”,而是“这个回答比同组其他回答好多少”。如果同一个题目生成了 8 个答案,其中 2 个答案正确、推理完整,另外 6 个答案错误或格式混乱,那么正确答案就会在组内获得更高相对优势。
可以把它理解成下面的结构:
flowchart TB
A[同一道题] --> B1[回答 1]
A --> B2[回答 2]
A --> B3[回答 3]
A --> B4[回答 4]
B1 --> C[规则评分]
B2 --> C
B3 --> C
B4 --> C
C --> D[计算组内平均分和标准差]
D --> E[得到每个回答的相对优势]
E --> F[更新策略模型]
这种方法有两个直接好处:
| 设计 | 作用 |
|---|---|
| 组内相对奖励 | 不需要为每个回答估计复杂的长期价值,只比较同题回答的好坏 |
| 不单独训练价值模型 | 减少训练资源和工程复杂度 |
| 保留策略约束 | 避免模型为了奖励过度偏离原有语言能力 |
不过,GRPO 也依赖奖励信号的质量。如果评分器只奖励最终答案,而完全不约束语言和格式,模型可能会出现可读性差、夹杂多种语言、输出冗长等问题。R1-Zero 的局限正好说明了这一点。
R1-Zero:纯强化学习能激发推理,但不等于直接可用
DeepSeek-R1-Zero 是一个重要实验:它从 DeepSeek-V3 Base 出发,不依赖人工标注的推理过程,直接通过强化学习训练推理能力。
训练后,R1-Zero 自然出现了不少高级推理行为:
- 自我反思:发现前一步可能有问题后重新检查。
- 验证答案:在给出最终答案前反复核对。
- 探索替代方案:一种解法不稳定时尝试另一种路径。
- 更长的推理轨迹:复杂题目上愿意展开更多中间步骤。
这说明模型不是只能被动模仿人类提供的推理样本。只要任务有明确奖励,模型可以通过试错形成有用的推理习惯。
但 R1-Zero 也暴露了纯强化学习的副作用。它的回答可能难读,可能混用语言,也可能过度关注数学和代码这类可评分任务,对写作、开放域问答、通用对话等任务不够稳定。
所以,R1-Zero 更像是一个科学验证:纯 RL 可以激发推理能力。要得到真正可用的通用推理模型,还需要后续训练阶段把能力“整理”成稳定、可读、符合人类使用习惯的形式。
从 R1-Zero 到 DeepSeek-R1:多阶段训练补齐可用性
DeepSeek-R1 并不是只靠一轮强化学习训练出来的。完整路线包含拒绝采样、强化学习、监督微调等多个阶段,每个阶段解决一个具体问题。
DeepSeek-R1 的多阶段训练 pipeline 如下图所示:
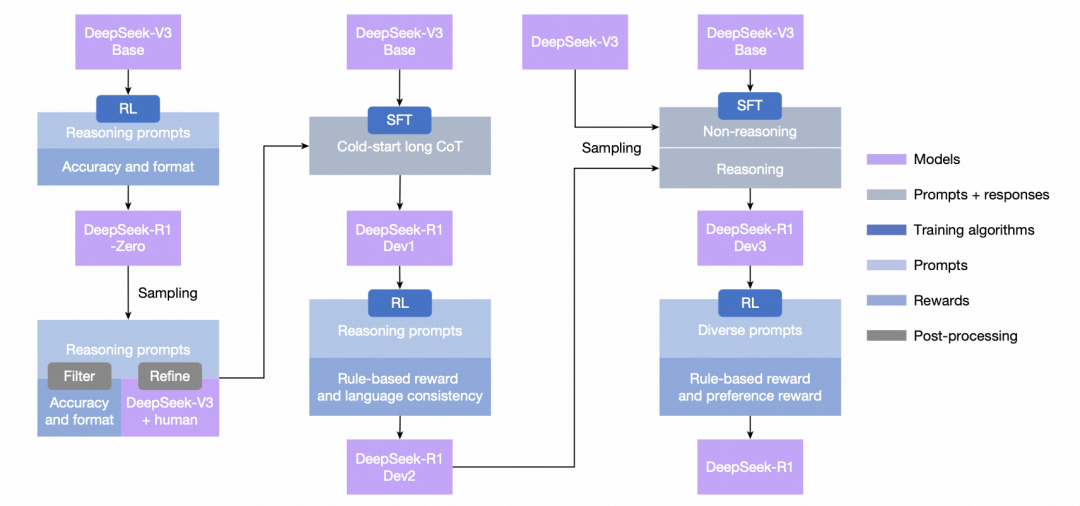
这条 pipeline 可以理解为:先证明推理能力可以通过 RL 涌现,再通过数据筛选、监督微调和进一步强化学习,把推理能力、通用语言能力和偏好对齐合在一起。
几个阶段的作用可以整理成表格:
| 阶段 | 主要目标 | 解决的问题 |
|---|---|---|
| DeepSeek-R1-Zero | 用纯 RL 激发推理能力 | 验证模型是否能通过试错学会推理策略 |
| DeepSeek-R1 Dev1 | 改善指令遵循与输出可读性 | 缓解 R1-Zero 的格式混乱、语言混用问题 |
| DeepSeek-R1 Dev2 | 强化代码、数学和 STEM 推理 | 提升高难任务上的稳定性 |
| DeepSeek-R1 Dev3 | 加入非推理语料和代码工程数据 | 补齐写作、问答、通用生成和工程能力 |
| DeepSeek-R1 | 综合推理能力与人类偏好 | 在强推理能力之外,提升可用性和安全边界 |
这里需要区分两个概念:
- R1-Zero 的意义在于证明纯强化学习能够让推理能力出现。
- R1 的意义在于把这种能力变成更适合真实使用的模型行为。
也就是说,纯 RL 是能力发现机制,多阶段训练是工程化落地机制。
为什么数学和代码适合训练推理模型
强化学习最怕奖励信号不可靠。开放式写作任务很难自动判断好坏,因为“好文章”“好回答”往往带有主观标准;数学和代码则不同,它们天然更容易评分。
| 任务类型 | 是否容易自动评分 | 适合 RL 的原因 |
|---|---|---|
| 数学题 | 高 | 最终答案可比对,过程可通过格式约束辅助检查 |
| 编程题 | 高 | 可以编译、运行单元测试或隐藏测试 |
| 选择题 | 高 | 选项可直接匹配 |
| 开放域写作 | 低 | 好坏标准复杂,容易依赖偏好模型 |
| 长篇对话 | 中低 | 需要同时考虑事实性、帮助性、安全性和上下文一致性 |
这也是 DeepSeek-R1 路线的重要前提:先在可验证任务里训练推理能力,再把这些能力迁移到更广泛的任务中。数学和代码不是全部应用场景,但它们提供了一个高质量训练场。
评测结果说明了什么
DeepSeek-R1 在多个主流 benchmark 上进行了评估,包括 MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)、MMLU-Pro、C-Eval(中文综合评测)、GPQA Diamond(研究生级高难问答子集)、SimpleQA、SWE-bench Verified(软件工程任务评测集的人工验证子集)、LiveCodeBench 和 AIME(American Invitational Mathematics Examination,美国数学邀请赛)2024 等。
评测覆盖通用知识、中文能力、研究生级科学问题、软件工程、在线编程和数学竞赛等不同维度,不是只看单一榜单。
DeepSeek-R1 各训练阶段的评测结果如下:
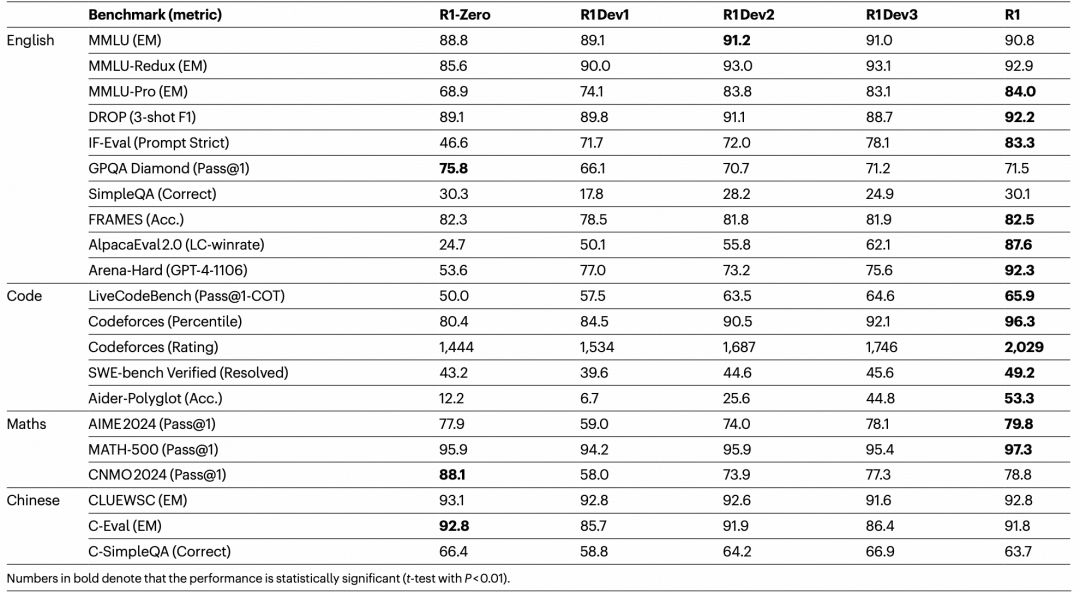
从阶段性结果可以看到,多阶段训练并不是单纯堆数据,而是在不同能力之间做平衡:早期阶段突出推理能力,后续阶段逐渐改善通用语言生成、指令遵循和更复杂场景下的表现。最终模型在多数 benchmark 上取得更强结果,支持了“RL 激发推理能力 + 多阶段补齐可用性”这一路线。
评测也需要谨慎看待。大模型 benchmark 可能受到测试集污染、题目泄露、训练数据重叠和选择性汇报影响。如果训练数据里包含测试题目或答案,模型分数就可能高估真实能力。因此,评测结果只有在数据来源、测试流程和失败样例都足够透明时,才更有参考价值。
同行评审为什么对大语言模型很重要
DeepSeek-R1 的另一个特殊之处,是相关研究经过了独立同行评审。对于大语言模型来说,这件事不只是学术流程,而是直接关系到模型能力声明是否可信。
大模型行业里常见几类问题:
| 问题 | 风险 |
|---|---|
| 只展示最有利的 benchmark | 用户难以判断模型在真实任务中的稳定性 |
| 训练数据与测试集重叠 | 榜单分数可能被高估 |
| 缺少安全测试细节 | 很难评估模型被滥用的门槛 |
| 能力声明过大 | 使用者可能在医疗、法律、科研等高风险场景中过度信任模型 |
| 闭源或信息不足 | 外部研究者无法复现实验,也难以定位缺陷 |
同行评审不能保证模型没有问题,但它能迫使研究团队回答更具体的问题:训练数据怎么来,评测是否公平,基准是否有污染,安全性怎么测,失败案例是什么,哪些结论有证据支持,哪些只是推测。
对于开放权重模型,这一点更关键。开放权重意味着外部研究者和普通用户可以下载、测试、微调和部署模型。开放带来两个方向的影响:
| 影响 | 具体表现 |
|---|---|
| 积极面 | 社区可以复现实验、发现缺陷、做安全评估、开发改进版本 |
| 风险面 | 恶意用户也可能移除安全限制,构建更危险的变体 |
所以,开放权重模型不应该只公布性能分数,还应该说明安全测试、滥用风险、限制条件和防护策略。透明不是把所有商业秘密公开,而是让关键能力声明经得起证据检验。
DeepSeek-R1 路线带来的启发
DeepSeek-R1 的技术路线可以概括为一句话:用可验证任务上的强化学习发现推理能力,再用多阶段训练把这种能力整理成可读、通用、相对安全的模型行为。
它带来的启发主要有三点。
第一,推理能力不一定完全来自人工标注的推理过程。
当任务可以自动评分时,模型能够通过试错学会自我检查、验证和策略调整。人工数据仍然有价值,但不再是唯一来源。
第二,纯强化学习能激发能力,但不等于最终产品形态。
R1-Zero 展示了能力涌现,DeepSeek-R1 则说明工程化模型还需要可读性、指令遵循、通用能力和安全对齐。
第三,大模型能力需要更透明的验证机制。
benchmark 分数只是证据的一部分。训练数据、评测方法、安全测试、失败案例和外部审查同样重要。模型越强,影响范围越大,越需要可复核的能力声明。
DeepSeek-R1 的意义不只在于某些榜单成绩,而在于它把“强化学习如何激发大模型推理能力”这件事做成了可讨论、可评审、可复现度更高的技术路线。对于后续推理模型训练来说,这比单次分数领先更有长期价值。