Agent(智能体)不是“一个大模型加一段提示词”这么简单。只要任务从单轮问答变成长程执行,比如改代码、操作浏览器、调用接口、写文件、提交 Pull Request,模型外面的工程系统就会决定它到底能不能稳定工作。
可以把关系写成一个简单公式:
Model + Harness = Agent
这里的 Harness 指模型外部的运行外壳和控制系统,包括沙箱、工具协议、上下文管理、任务编排、监控、评估、安全策略等。模型负责推理和生成动作,Harness 负责让这些动作在真实系统里可执行、可追踪、可回滚、可约束。
换句话说,模型像“大脑”,Harness 像神经系统、操作系统、权限系统和质量体系的组合。没有 Harness,Agent 只能停留在演示;有了 Harness,Agent 才能进入生产环境。
为什么 Harness 会成为 Agent 的关键约束
早期很多 Agent 方案默认一个前提:只要大语言模型(LLM,Large Language Model)足够强,配上好的 Prompt(提示词),复杂任务自然就能完成。这个判断在短任务里有一定道理,但在长程任务里会很快失效。
长程任务有几个特点:
- 需要多次模型调用;
- 需要多次工具调用;
- 中间状态会变化;
- 某一步失败可能影响后续所有步骤;
- 成功不只取决于最终回答,还取决于执行轨迹是否安全、合规、可复现。
因此,决定 Agent 表现的变量不只是模型参数,还有它被放进了怎样的系统里。
几个实验现象能说明这个问题:
| 案例 | 固定不变的部分 | Harness 改动 | 结果 | 说明 |
|---|---|---|---|---|
| Bölük 2026a | 15 个模型权重不变 | 调整编辑工具格式和周边执行外壳 | 编码基准最高提升 10 倍 | 工具接口和执行方式会大幅影响模型能力释放 |
| Trivedy 2026 | 固定 GPT-5.2-Codex | 重构系统提示、中间件上下文注入、自验证钩子 | Terminal-Bench 2.0 从 52.8% 到 66.5%,提升 13.7pp(百分点) | 不换模型也能靠系统设计获得明显收益 |
| Meta-Harness | 模型不是优化重点 | 自动搜索并优化 Harness 结构 | Terminal-Bench-2 达到 76.4% | Harness 本身可以成为优化对象 |
这类现象可以概括为“绑定约束”:对长程 Agent 任务来说,执行系统经常比模型本身更容易成为瓶颈。模型升级通常带来几个百分点的提升,而 Harness 调整可能改变任务是否能完整跑通。
从 Prompt Engineering 到 Harness Engineering
Agent 工程大致经历了三个关注点的变化。
| 阶段 | 时间 | 关注的问题 | 优化对象 | 典型手段 |
|---|---|---|---|---|
| Prompt Engineering | 2022-2024 | 模型输入应该怎么写 | 单次模型调用的文本 | 指令模板、Few-shot 示例、思维链提示 |
| Context Engineering | 2025 | 模型每一步应该看到什么 | 多轮任务中的信息流 | 检索、压缩、记忆、上下文裁剪 |
| Harness Engineering | 2026 | 模型如何在系统中可靠运行 | 跨组件基础设施 | 沙箱、工具协议、编排、观测、评估、治理 |
Harness Engineering 不是替代 Prompt Engineering 和 Context Engineering,而是把它们放进更大的系统里统一处理。
一个生产级 Agent 不能只回答“提示词怎么写”,还要回答这些问题:
- 生成的代码在哪里执行?
- 工具调用参数如何校验?
- 文件系统、网络和密钥权限如何限制?
- 上下文窗口放哪些信息,不放哪些信息?
- 多个子任务如何调度?
- 每一步调用如何追踪成本和错误?
- 失败案例如何进入回归测试?
- 高风险操作由谁审批,审批记录存在哪里?
这些问题合起来,就是 Harness Engineering 的范围。
ETCLOVG:Agent Harness 的七层架构
ETCLOVG 是一套用于拆解 Agent Harness 的七层结构:
- E:Execution Environment & Sandbox,执行环境与沙箱
- T:Tool Interface & Protocol,工具接口与协议
- C:Context & Memory Management,上下文与记忆管理
- L:Lifecycle & Orchestration,生命周期与编排
- O:Observability & Operations,可观测性与运维
- V:Verification & Evaluation,验证与评估
- G:Governance & Security,治理与安全
其中 E/T/C/L 是 Agent 执行链路上的结构层,O/V/G 是贯穿整个系统的控制层。
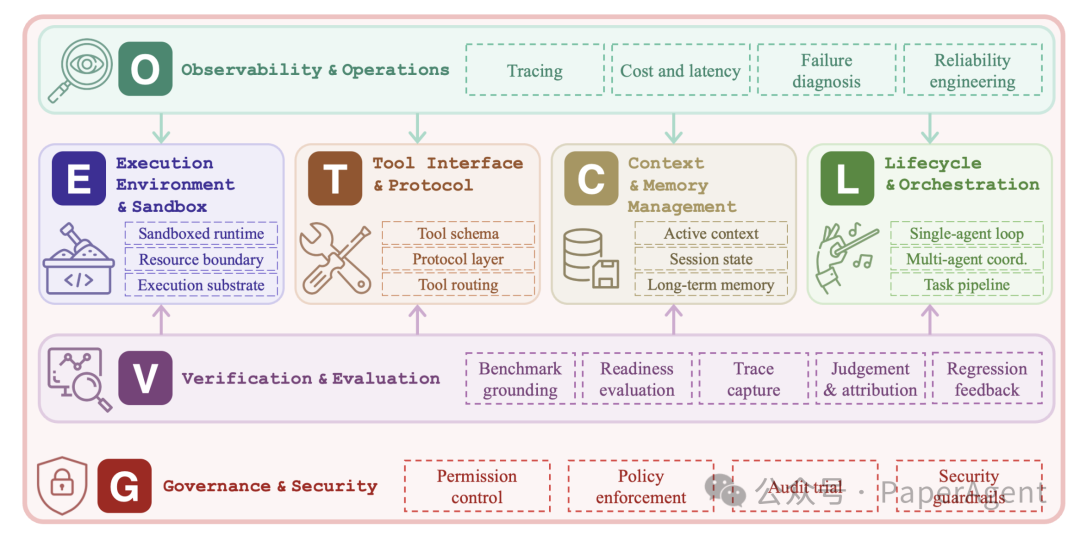
图里的关键关系是:执行环境、工具、上下文和编排共同支撑 Agent 的运行;可观测性负责把运行过程变成可分析数据;验证与评估负责判断任务是否真的完成;治理与安全负责限制 Agent 能做什么、不能做什么,以及高风险动作如何审计。
也可以用一个简化结构表示:
flowchart TB
U[用户任务] --> L[生命周期与编排 L]
L --> C[上下文与记忆 C]
L --> T[工具接口与协议 T]
T --> E[执行环境与沙箱 E]
E --> R[外部环境:代码库、浏览器、Shell、API]
O[可观测性与运维 O] -.追踪/指标/日志.-> L
O -.追踪/指标/日志.-> T
O -.追踪/指标/日志.-> E
V[验证与评估 V] -.任务评估/故障归因.-> L
V -.回归测试.-> C
G[治理与安全 G] -.权限/策略/审计.-> T
G -.权限/策略/审计.-> E
七层各自解决的问题不同:
| 层 | 核心问题 | 产物 | 缺失时的典型故障 |
|---|---|---|---|
| E 执行环境与沙箱 | 动作在哪里安全执行 | 容器、虚拟机、浏览器环境、权限隔离 | 命令误删文件、环境不可复现、权限过大 |
| T 工具接口与协议 | Agent 如何发现和调用能力 | Function Calling、OpenAPI、MCP、A2A | 参数错误、工具过多、调用链混乱 |
| C 上下文与记忆 | 模型每一步看到什么 | 活跃窗口、会话状态、长期记忆 | 忘记目标、上下文污染、成本失控 |
| L 生命周期与编排 | 多步任务如何推进 | ReAct 循环、多 Agent 调度、工作流 | 卡死、重复尝试、子任务协作失败 |
| O 可观测性与运维 | 运行过程如何被看见 | Trace、日志、指标、成本归因 | 失败不可诊断、成本异常无法定位 |
| V 验证与评估 | 怎么判断 Agent 真的完成任务 | Benchmark、评估器、回归集 | 只看最终答案,无法知道哪里错 |
| G 治理与安全 | Agent 在什么约束下行动 | 权限模型、护栏、审计、人审 | Prompt 注入、越权访问、风险动作无人负责 |
E 层:执行环境与沙箱
Agent 会生成代码、执行 Shell 命令、读写文件、访问网页,甚至调用内部接口。如果这些动作直接落到真实环境里,风险会非常高。
沙箱在 Agent 系统里至少承担三件事。
1. 安全隔离
LLM 生成的代码具有不确定性。它可能误删文件,也可能在 Prompt 注入攻击下执行攻击者诱导的命令。沙箱需要把文件系统、网络、进程、环境变量和密钥访问控制在边界内。
常见限制包括:
sandbox:
filesystem:
mode: workspace-only
readonly_paths:
- /etc
- /usr
network:
default: deny
allowlist:
- api.github.com
process:
timeout_seconds: 120
max_memory_mb: 2048
secrets:
expose:
- GITHUB_TOKEN_READONLY
2. 可复现
评估 Agent 时,环境状态必须能重置到已知基线。比如同一道 SWE-bench 任务,如果第一次运行后改坏了代码库,第二次评估就不能直接复用这个目录。沙箱快照、容器镜像和环境重置机制可以保证每次任务都从同一起点开始。
3. 活性
没有沙箱时,每个风险动作都需要人工确认。确认太频繁会产生“权限疲劳”:用户要么放弃使用,要么不看内容就全部批准。沙箱把低风险动作限制在安全边界内,可以减少人工确认次数。Anthropic 曾报告 Claude Code 引入沙箱后,权限提示减少 84%,同时仍保持安全边界。
执行环境常见类型如下:
| 类型 | 适合场景 | 关键能力 |
|---|---|---|
| 通用托管沙箱 | 执行脚本、运行命令 | 隔离、超时、资源限制 |
| Computer-Use 环境 | 操作桌面或浏览器 | 屏幕状态、鼠标键盘事件、截图 |
| 代码专用沙箱 | 编码任务、单元测试 | 依赖安装、测试执行、代码回滚 |
| 框架集成运行时 | Agent 框架内置执行 | 与编排、日志、工具系统打通 |
| 浏览器评估环境 | WebArena、网页自动化 | DOM、页面状态、网络请求 |
| OS 级权限沙箱 | 本地 Agent | 文件、网络、进程、系统调用限制 |
| 沙箱抽象层 | 多种执行后端切换 | 统一 API、环境适配 |
T 层:工具接口与协议
工具层相当于 Agent 的“系统调用层”。模型不能直接操作外部世界,它必须通过工具完成动作,例如搜索、读文件、调用数据库、提交代码、发邮件。
工具层要解决四个问题:
- 工具如何描述;
- 工具如何发现;
- 工具如何调用;
- 工具执行结果如何返回给模型。
一个简单工具描述可能长这样:
{
"name": "read_file",
"description": "Read a text file from the workspace.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "Relative file path under the workspace."
}
},
"required": ["path"]
}
}
工具描述越清晰,模型越容易选对工具。但工具不是越多越好。生产系统里经常出现“工具菜单过大”的问题:可用工具太多会增加 Token 开销,也会放大规划错误。模型可能在多个相似工具之间选错,或者为了完成一个简单动作绕很远的调用路径。
工具协议可以按集成边界划分:
| 集成边界 | 代表标准 | 解决的问题 |
|---|---|---|
| Model ↔ Function | Function Calling、OpenAPI | 把模型输出变成结构化函数调用 |
| Agent ↔ Capability | MCP(Model Context Protocol,模型上下文协议)、OpenAPI | 让 Agent 与外部能力运行时解耦 |
| Agent ↔ Agent | A2A(Agent-to-Agent,智能体到智能体)、ACP、ANP | 跨 Agent 委托、协作和消息传递 |
| Agent ↔ Repo/Env | AGENTS.md、AGENT.md | 在代码仓库或环境里声明 Agent 行为约定 |
工具层设计时要特别注意:
- Schema 要严格:参数类型、必填字段、枚举值都应该明确。
- 工具要分级暴露:默认只给当前任务需要的工具,高风险工具按需申请。
- 长任务要支持会话:比如浏览器、远程 Shell、数据库连接都需要上下文状态。
- 工具结果要可压缩:返回内容太长会污染上下文窗口。
- 调用失败要结构化:错误码、错误原因、是否可重试都应该清楚。
C 层:上下文与记忆管理
上下文窗口不是越大越好。长上下文会带来三个问题:
- Transformer 注意力计算成本通常随长度二次增长;
- 模型对上下文中间位置的信息不一定敏感,常见现象是开头和结尾更容易被利用;
- 上下文长期堆积会产生污染,旧信息、错误总结和无关工具输出会干扰后续决策。
所以,上下文管理的目标不是“把所有东西塞进去”,而是让模型在每一步看到最该看的内容。
可以把 Agent 记忆分成三层:
| 记忆层 | 保存内容 | 生命周期 | 例子 |
|---|---|---|---|
| 短期活跃窗口 | 当前步骤必须用的信息 | 单次或少量模型调用 | 当前目标、最近观察、待执行动作 |
| 中期会话状态 | 当前任务中的稳定状态 | 一次任务或会话 | 已修改文件、已尝试方案、失败原因 |
| 长期持久记忆 | 跨任务复用的知识 | 多次任务 | 用户偏好、项目结构、常用命令 |
上下文构造可以设计成一条流水线:
flowchart LR
A[任务目标] --> B[检索相关资料]
B --> C[过滤无关内容]
C --> D[压缩与摘要]
D --> E[按重要性排序]
E --> F[放入上下文窗口]
F --> G[模型生成动作]
G --> H[执行结果]
H --> I[写入会话状态或长期记忆]
I --> B
关键策略包括:
- 检索前置:不要等模型忘了再补,任务开始时就检索相关代码、文档和历史记录。
- 位置管理:高优先级指令和当前任务状态放在模型更容易利用的位置。
- 工具输出摘要:长日志、长网页、长 diff 不要原样塞入。
- 记忆写入要审查:不能把模型猜测、错误结论直接写入长期记忆。
- 上下文预算要显式化:为系统指令、任务状态、工具结果、历史轨迹分别设置预算。
L 层:生命周期与编排
编排层负责让任务跨多次模型调用和工具调用持续推进。一个 Agent 往往不是一次生成就结束,而是不断经历“思考、行动、观察、修正”的循环。
典型单 Agent 内循环可以表示为:
sequenceDiagram
participant User as 用户
participant Orchestrator as 编排器
participant Model as 模型
participant Tool as 工具
participant Env as 环境
User->>Orchestrator: 提交任务
Orchestrator->>Model: 构造上下文并请求下一步动作
Model-->>Orchestrator: 返回计划或工具调用
Orchestrator->>Tool: 校验并执行工具
Tool->>Env: 读写文件/运行命令/访问 API
Env-->>Tool: 返回环境结果
Tool-->>Orchestrator: 返回结构化观察
Orchestrator->>Model: 注入观察并请求修正
Model-->>Orchestrator: 输出结果或继续行动
Orchestrator-->>User: 返回最终产物
常见编排模式有三类。
| 编排模式 | 说明 | 适合场景 | 风险 |
|---|---|---|---|
| 单 Agent 内循环 | 一个 Agent 反复规划、行动、观察 | 代码修改、资料整理、命令执行 | 容易陷入循环,需要预算和停止条件 |
| 多 Agent 编排 | 多个 Agent 分工协作 | 研究、软件开发、复杂分析 | 协调成本高,责任边界容易模糊 |
| 全生命周期流水线 | 从需求到交付端到端串联 | Issue 到 PR、自动测试、自动发布 | 需要强评估、强审计、强回滚 |
多 Agent 又可以继续细分:
- 层级编排:一个管理者 Agent 拆任务,多个执行 Agent 完成子任务。
- 团队编排:多个角色平行协作,比如规划、编码、测试、审查。
- 图编排:用有向图定义节点和状态转移,适合可控流程。
- 扇出编排:同一任务并行生成多个候选结果,再合并或投票。
编排层必须有明确的停止条件:
orchestration:
max_steps: 30
max_tool_calls: 80
max_cost_usd: 3.00
stop_when:
- tests_passed
- user_goal_satisfied
retry:
max_attempts_per_tool: 2
backoff: exponential
没有预算和停止条件,Agent 很容易在错误路径上反复尝试,造成成本失控。
O 层:可观测性与运维
普通应用的可观测性关注请求延迟、错误率、CPU、内存。Agent 系统还要关注更多维度:模型输入输出、工具调用、上下文大小、重试次数、成本、失败轨迹、安全拦截。
可观测性需要回答几个问题:
- Agent 为什么做出这个动作?
- 哪个工具调用失败了?
- 是模型没理解任务,还是上下文缺信息?
- 成本花在了哪个步骤?
- 某次部署后成功率为什么下降?
- 高风险动作有没有被拦截或审批?
常见工具栈包括 Langfuse、Arize Phoenix、OpenLLMetry、OpenTelemetry(开放遥测标准)、Prometheus、Jaeger、Grafana 等。它们分别覆盖 Trace、指标、日志、成本归因和可视化。
Agent 运行时至少应该记录这些信号:
| 信号 | 示例 | 用途 |
|---|---|---|
| Trace | 每次模型调用、工具调用、重试 | 还原执行轨迹 |
| Token | 输入 Token、输出 Token、上下文长度 | 控制成本,发现上下文膨胀 |
| 成本 | 每步调用费用、总费用 | 预算管理和归因 |
| 延迟 | 模型响应耗时、工具执行耗时 | 找到慢步骤 |
| 工具结果 | 成功、失败、错误码、输出摘要 | 判断失败来源 |
| 安全事件 | 权限拒绝、策略命中、人审记录 | 审计和合规 |
| 评估结果 | 成功率、轨迹评分、失败分类 | 回归分析 |
一个可观测性事件可以设计成结构化格式:
{
"trace_id": "run_20260607_001",
"step": 12,
"event_type": "tool_call",
"tool": "run_tests",
"input_summary": "pytest tests/test_parser.py",
"status": "failed",
"error_code": "TEST_FAILURE",
"latency_ms": 8421,
"tokens_in": 1832,
"tokens_out": 214,
"cost_usd": 0.018,
"policy_decision": "allowed"
}
如果没有这些数据,Agent 失败时只能看到“任务没完成”,很难知道是模型、工具、上下文、权限还是环境出了问题。
V 层:验证与评估
传统 LLM 评估通常看最终输出,比如答案是否正确、摘要是否覆盖要点。Agent 评估更复杂,因为它要评估整个 episode(一次完整执行过程)。
一次 Agent 执行可能最终答案正确,但中间用了危险命令;也可能最终失败,但规划路径合理,只是环境依赖缺失。因此,Agent 评估必须同时看结果、轨迹和评估器本身。
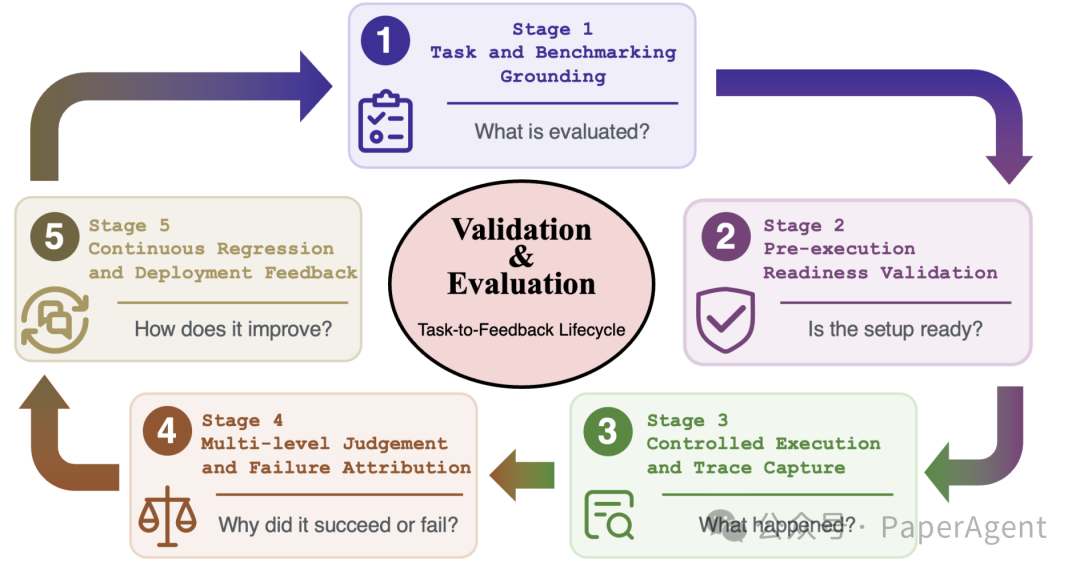
图中的 Task-to-Feedback(任务到反馈)生命周期强调:评估不是打一个最终分数,而是把任务定义、执行准备、轨迹捕获、故障归因和回归反馈串起来。
五个阶段可以这样落地:
| 阶段 | 要做的事 | 产物 |
|---|---|---|
| 任务与基准锚定 | 定义初始环境、可用工具、成功标准 | Benchmark、任务配置、评分规则 |
| 执行前就绪验证 | 检查沙箱、依赖、权限、预算、评估器 | Readiness Check |
| 受控执行与追踪捕获 | 记录模型输出、工具调用、环境变化、错误和成本 | Trace、日志、环境 diff |
| 多级判断与故障归因 | 判断结果是否完成,轨迹是否安全高效,评估器是否可信 | 成功率、轨迹评分、失败分类 |
| 持续回归与部署反馈 | 把失败样本变成回归测试,阻止同类问题再次上线 | Regression Suite、发布门禁 |
Agent 评估不要只保留一个成功率。更有用的是失败分类:
| 失败类型 | 典型表现 | 改进方向 |
|---|---|---|
| 规划失败 | 任务拆解错误,走错方向 | 改编排策略、补充任务约束 |
| 工具选择失败 | 选错工具或参数错误 | 优化工具描述、减少工具菜单 |
| 上下文失败 | 忘记目标或遗漏关键文件 | 改检索、压缩和记忆策略 |
| 环境失败 | 依赖缺失、权限不足、状态污染 | 强化沙箱和就绪检查 |
| 安全失败 | 执行越权动作或泄露敏感信息 | 加权限模型、护栏和审计 |
| 评估失败 | 评估器误判成功或失败 | 校准评估器,引入人工抽检 |
G 层:治理与安全
Agent 的风险来自它能行动。一个只能聊天的模型造成的直接损害有限,而一个能执行 Shell、发邮件、改代码、调接口的 Agent 必须受到治理。
治理层要回答两个问题:
- Agent 在什么约束下行动?
- 约束失败时如何追责和恢复?
常见治理机制包括:
| 机制 | 作用 |
|---|---|
| 权限模型 | 定义 Agent 能访问哪些文件、接口、网络和密钥 |
| 生命周期 Hook | 在输入、动作、输出、人审环节插入安全检查 |
| 组件加固 | 加强工具、沙箱、记忆库、日志系统的防护 |
| 声明式规则 | 用策略文件描述允许和禁止的行为 |
| 审计基础设施 | 记录谁授权、何时执行、执行了什么、结果如何 |
| Agent 安全测试 | 针对 Prompt 注入、数据泄露、越权调用进行专项测试 |
单次工具调用通常可以设置四个治理点:
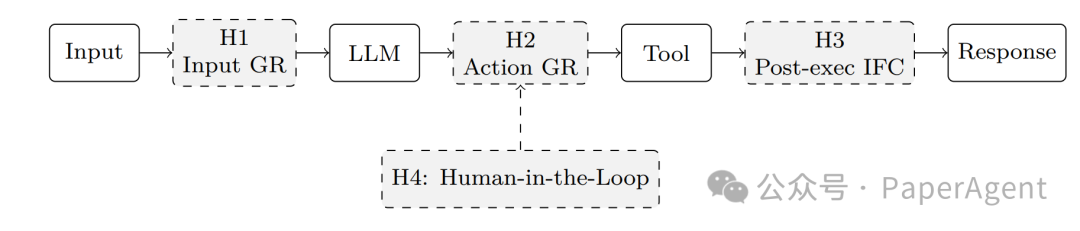
图中的 H1 到 H4 对应工具调用前后的关键拦截位置:输入进入模型前要做护栏检查;动作执行前要做权限判断;执行后要控制信息流,避免敏感结果继续传播;高风险动作需要人参与审批。
可以用流程表示:
flowchart LR
A[用户输入/环境观察] --> H1[H1 输入护栏]
H1 --> B[模型生成动作]
B --> H2[H2 动作护栏]
H2 --> C[工具执行]
C --> H3[H3 后执行信息流控制]
H3 --> D[结果进入上下文]
H2 -->|高风险| H4[H4 人在回路审批]
H4 -->|批准| C
H4 -->|拒绝| E[终止或改写计划]
一个治理策略可以写成声明式配置:
governance:
filesystem:
default: deny
allow:
- path: "./src/**"
actions: ["read", "write"]
- path: "./tests/**"
actions: ["read", "write", "execute"]
deny:
- path: "./.env"
actions: ["read", "write"]
network:
default: deny
allow_domains:
- "api.github.com"
- "pypi.org"
commands:
require_approval:
- "rm -rf *"
- "git push *"
- "curl * | sh"
secrets:
no_model_echo: true
audit:
record_tool_inputs: true
record_tool_outputs: "summary"
治理不是单纯“禁止危险操作”。更合理的做法是按风险分层:
| 风险等级 | 示例动作 | 处理方式 |
|---|---|---|
| 低风险 | 读取工作区文件、运行只读检查命令 | 自动允许,记录日志 |
| 中风险 | 修改代码、安装依赖、访问外部 API | 沙箱内允许,限制范围 |
| 高风险 | 删除大量文件、提交代码、发送邮件 | 人工审批 |
| 禁止 | 读取密钥、访问未授权网络、绕过审计 | 直接拒绝并告警 |
如何设计一个最小可用的 Agent Harness
一个可落地的 Harness 不需要一开始就做得很复杂,但七层都应该有最小实现。缺任何一层,系统都会留下明显短板。
1. 先定义任务边界
明确 Agent 要解决什么任务,以及不解决什么任务。
task:
type: coding_agent
goal: "Fix a bug and submit a patch"
allowed_repositories:
- "workspace/project"
success_criteria:
- "unit_tests_pass"
- "no_security_policy_violation"
out_of_scope:
- "production_deployment"
- "database_migration"
2. 准备可重置执行环境
execution:
backend: docker
image: "python:3.12"
reset_strategy: snapshot
timeout_seconds: 600
resource_limits:
cpu: 2
memory_mb: 4096
3. 暴露少量高质量工具
tools:
registry: mcp
allowlist:
- read_file
- write_file
- search_code
- run_tests
- git_diff
selection:
max_visible_tools: 8
hide_unrelated_tools: true
4. 建立上下文预算
context:
max_tokens: 64000
budget:
system_instruction: 4000
task_state: 6000
retrieved_files: 30000
tool_observations: 12000
scratchpad_summary: 8000
memory:
session_summary: true
long_term_write_requires_verification: true
5. 设置编排循环
lifecycle:
pattern: react
max_steps: 40
max_retries_per_step: 2
stop_conditions:
- "success_criteria_met"
- "budget_exceeded"
- "policy_blocked"
6. 打开追踪与成本归因
observability:
tracing: true
metrics:
- tokens
- latency
- tool_errors
- cost
- policy_blocks
export:
- openTelemetry
- langfuse
7. 把失败变成回归测试
evaluation:
benchmark: custom_bugfix_suite
capture:
- final_result
- full_trace
- environment_diff
- test_output
failure_taxonomy:
- planning
- tool_use
- context
- environment
- safety
regression:
add_failed_cases: true
8. 加上权限和审计
governance:
approval_required:
- "network_write"
- "git_push"
- "send_email"
audit_log:
enabled: true
retention_days: 180
policy_on_violation: "stop_and_report"
把这些配置连起来,一个最小 Harness 的运行逻辑大致如下:
def run_agent(task):
sandbox = sandbox_manager.reset(task.environment)
trace = tracer.start(task.id)
state = task_state.init(task)
memory.load_session(task.session_id)
for step in range(task.max_steps):
context = context_builder.build(
task=task,
state=state,
memory=memory,
budget=task.context_budget,
)
action = model.next_action(context)
policy_decision = governance.check_action(action, state)
trace.record_action(action, policy_decision)
if policy_decision.requires_approval:
approved = human_review.request(action)
if not approved:
state.add_observation("Action rejected by human reviewer.")
continue
if policy_decision.blocked:
return finish("blocked_by_policy", trace)
result = tool_runtime.execute(action, sandbox=sandbox)
trace.record_tool_result(result)
state.update(result)
memory.maybe_write(state.verified_facts())
if evaluator.success(task, state, sandbox):
return finish("success", trace)
if budget.exceeded(trace):
return finish("budget_exceeded", trace)
return finish("max_steps_reached", trace)
这段伪代码体现了 Harness 的核心思想:模型不直接接触外部环境,所有动作都经过上下文构造、策略检查、工具运行、观测记录和评估反馈。
常见坑
| 问题 | 现象 | 处理办法 |
|---|---|---|
| 工具太多 | 模型频繁选错工具,Token 成本升高 | 按任务动态暴露工具,给工具分组和优先级 |
| 上下文堆积 | 模型忘记目标,被旧信息干扰 | 设置上下文预算,压缩工具输出,清理过期状态 |
| 没有沙箱 | 执行不可复现,权限风险高 | 使用容器、快照、网络隔离和资源限制 |
| 只看最终成功率 | 失败原因不可诊断 | 保存完整 Trace,做故障归因 |
| 没有停止条件 | Agent 无限尝试,成本失控 | 限制步数、工具次数、时间和费用 |
| 人审过多 | 用户产生权限疲劳 | 低风险自动允许,高风险再审批 |
| 记忆污染 | 错误结论进入长期记忆 | 记忆写入前做验证,只保存事实 |
| 评估器不可信 | 错误任务被判成功 | 评估器抽检,加入轨迹级评估 |
| 审计不完整 | 出事后无法追责 | 记录输入、动作、策略决策、审批和结果 |
Harness Engineering 的核心判断
Agent 能力由模型和系统共同决定。模型越强,越需要 Harness 把能力约束在可控范围内;任务越长,越不能只依赖 Prompt。
ETCLOVG 七层架构提供了一种拆解方法:
E:让动作安全执行
T:让能力可被可靠调用
C:让模型看到正确上下文
L:让任务持续推进
O:让过程可观测
V:让结果可验证
G:让行为受约束、可审计
如果一个 Agent 只是 Demo,Prompt 和工具调用可能已经够用;如果它要处理真实代码、真实数据、真实用户和真实权限,Harness 就会变成工程主战场。模型负责“想做什么”,Harness 决定“能不能做、怎么做、做错了怎么办”。