用户说一句“帮我点杯霸王茶姬的伯牙绝弦,少糖去冰,送到公司”,AI(人工智能)Agent(智能体)并不是只调用一次大模型就结束了。它需要识别意图、解析地址、搜索门店和商品、匹配规格、维护购物车、确认订单,过程中还可能和用户来回确认几轮。
这些步骤有一个共同前提:Agent 必须知道前面发生过什么。
如果上一轮已经确认了“少糖去冰”,下一轮下单时不能忘;如果前面已经选中了某个门店和商品,后续修改规格时也不能重新开始搜索。这里的“记住”就是 AI Agent 的短期记忆。
短期记忆不是简单保存聊天记录。它同时包含两类信息:
| 记忆类型 | 例子 | 主要使用方 |
|---|---|---|
| 对话历史 | 用户说过什么、Agent 回复过什么、上一轮推荐了哪些商品 | 大语言模型推理 |
| 业务上下文 | 当前地址、购物车、已选 SKU(库存量单位)、优惠券、会话阶段 | 工具调用、意图处理、订单流程 |
Tair 可以作为这类短期记忆层的存储引擎。它兼容 Redis 协议,提供低延迟内存读写、丰富数据结构、TTL(Time To Live,过期时间)和集群弹性能力,适合承载会话级状态。
短期记忆层要解决哪些问题
以点外卖 Agent 为例,一次会话可能长这样:
sequenceDiagram
participant U as 用户
participant A as Agent
participant M as Memory Service
participant T as 工具服务
U->>A: 帮我点杯奶茶,送到公司
A->>M: 读取历史对话和业务上下文
A->>T: 定位地址、搜索门店和商品
T-->>A: 返回门店、商品、配送信息
A->>M: 写入搜索结果、候选商品、会话阶段
A-->>U: 找到附近商品,请确认
U->>A: 就这个,少糖去冰
A->>M: 读取上一轮推荐和当前购物车
A->>T: 匹配规格、加入购物车
A->>M: 更新 SKU、规格、购物车
A-->>U: 已选好,是否提交订单
U->>A: 提交
A->>M: 读取地址、购物车、优惠信息
A->>T: 创建订单
A->>M: 更新订单状态
A-->>U: 订单已提交
这个链路对记忆系统有几个要求:
| 要求 | 原因 |
|---|---|
| 低延迟 | 每轮对话都要读写记忆,单次慢几十毫秒会在链路里反复放大 |
| 有序记录 | 对话历史必须按时间顺序组织,模型才能理解上下文 |
| 局部更新 | 购物车、地址、优惠券等状态经常被不同模块独立修改 |
| 并发安全 | 用户连续发送消息或流式响应未结束时,可能出现同一会话并发写入 |
| 自动清理 | 会话结束后,短期记忆没有长期保存价值,需要自动释放内存 |
| 流量弹性 | 活动流量可能瞬间升高,记忆访问量会随着 Agent 调用次数被放大 |
延迟为什么会滚雪球
记忆层的 5ms 和 50ms,不只是用户体感上的差别,还会改变系统的并发压力。
Little 定律可以写成:
系统在途请求数 ≈ QPS × 平均延迟
假设记忆服务承载 10000 QPS(每秒查询数):
| 单次访问延迟 | 估算在途请求数 |
|---|---|
| 5ms | 10000 × 0.005 = 50 |
| 50ms | 10000 × 0.05 = 500 |
延迟增加 10 倍,在途请求数也会增加 10 倍。更多在途请求会占用更多连接、线程、队列和内存,系统排队时间继续变长,最终可能出现超时和级联故障。
Agent 场景更敏感,因为一轮对话通常不是一次读写,而是多次记忆访问:
读取对话历史
读取业务上下文
获取会话锁
更新搜索状态
更新购物车
追加模型记忆
刷新 TTL
释放会话锁
单次访问慢一点,会在一轮对话里累计多次;并发高时,累计延迟又会转化为更大的排队压力。
记忆服务在整体架构中的位置
点单 Agent 的记忆层通常放在 Agent 中枢和底层工具服务之间。Agent 中枢负责意图理解、流程编排和模型调用;工具服务负责搜索、地址、购物车、订单等具体业务动作;Memory Service 则负责把会话状态稳定地存取到 Tair。
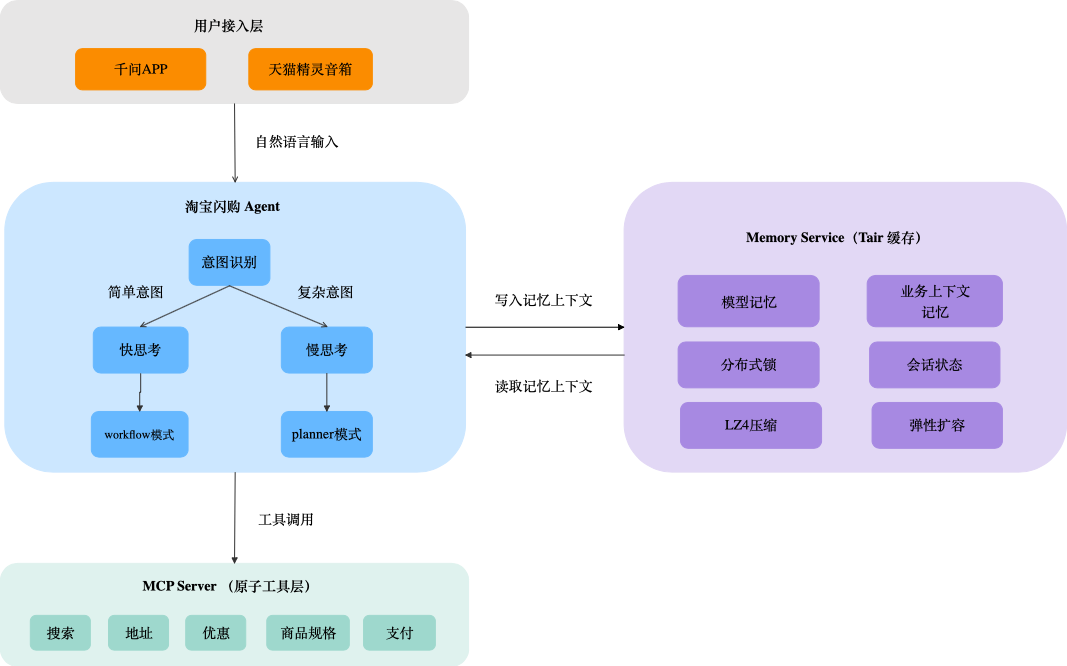
这套结构的关键点在于,业务工具不需要各自维护一份会话状态,而是通过统一的记忆服务读写 Tair。模型推理前读取模型记忆和业务上下文,工具执行后把新的状态写回记忆层。这样可以避免状态散落在多个服务里,减少“搜索模块知道商品,订单模块不知道用户选了哪个 SKU”的问题。
数据模型设计:List 存对话,Hash 存业务上下文
短期记忆可以拆成两块:模型记忆和业务上下文记忆。两者访问方式不同,适合的数据结构也不同。
模型记忆:用 List 保存有序对话历史
模型记忆主要给大语言模型消费。它保存用户输入、Agent 回复,以及必要的卡片、商品、确认信息等上下文。
对话天然是时间序列,适合用 List:
Key: memory:model:{sessionId}
Type: List
示例数据可以组织成 JSON:
[
{
"role": "user",
"content": "帮我点杯奶茶"
},
{
"role": "assistant",
"content": "为你找到附近 3 家奶茶店,推荐伯牙绝弦、桂花乌龙等商品"
},
{
"role": "user",
"content": "就这个,少糖去冰"
},
{
"role": "assistant",
"content": "已选择伯牙绝弦,大杯,少糖,去冰"
}
]
常用操作:
# 追加一轮新的对话记录
RPUSH memory:model:{sessionId} '{"role":"user","content":"就这个,少糖去冰"}'
RPUSH memory:model:{sessionId} '{"role":"assistant","content":"已选择伯牙绝弦,大杯,少糖,去冰"}'
# 模型推理前读取最近 N 条消息
LRANGE memory:model:{sessionId} -{N} -1
# 设置 30 分钟过期
EXPIRE memory:model:{sessionId} 1800
写入模型记忆前,最好不要把完整的富媒体卡片、冗余字段和接口原始响应全部塞进去。模型需要的是能理解决策的信息,例如“推荐了哪几个商品”“用户选择了哪个规格”“是否确认地址”。把复杂结构压缩成更紧凑的自然语言或精简 JSON,可以减少 Token 消耗,也能降低 Tair 的网络传输和内存占用。
一个更适合模型的记录可以长这样:
{
"role": "assistant",
"content": "已推荐门店 A 的伯牙绝弦,候选规格包括中杯/大杯,用户尚未确认糖度和温度。"
}
而不是直接保存完整商品卡片:
{
"role": "assistant",
"content": "...",
"cards": [
{
"shop": "...",
"items": [
{
"id": "...",
"name": "...",
"skuList": "...",
"image": "...",
"tracking": "...",
"extra": "..."
}
]
}
]
}
业务上下文记忆:用 Hash 保存结构化状态
业务上下文记忆服务于工具调用和流程判断。它不要求像聊天记录一样按时间追加,而是经常局部更新某个状态,例如只更新购物车、只更新地址、只更新优惠券。
这类数据适合用 Hash:
Key: memory:context:{sessionId}
Type: Hash
可以按业务域拆成多个 field:
| Field | 保存内容 | 典型更新时机 |
|---|---|---|
| session | 用户 ID、渠道、会话阶段、创建时间 | 会话初始化、阶段切换 |
| search | 当前 query、门店列表、商品候选、推荐结果 | 搜索完成、重新推荐 |
| order | 购物车、已选 SKU、商品数量、规格 | 用户确认商品或修改规格 |
| conversation | 当前意图、上一轮意图、是否发生意图切换 | 每轮意图识别后 |
| coupon | 可用优惠券、已选优惠、优惠金额 | 查询优惠或用户选择优惠 |
| bizState | 收货地址、配送方式、支付状态 | 地址确认、配送确认、支付完成 |
示例结构:
Key: memory:context:{sessionId}
Field:
session -> {"userId":"u123","channel":"qwen","stage":"selecting_item"}
search -> {"query":"奶茶","shopIds":["s1","s2"],"recommendedItemId":"i100"}
order -> {"items":[{"skuId":"sku100","count":1,"attrs":["少糖","去冰"]}]}
conversation -> {"currentIntent":"confirm_sku","lastIntent":"select_item"}
coupon -> {"available":["c1","c2"],"selected":"c1"}
bizState -> {"address":"公司","deliveryType":"immediate","payStatus":"unpaid"}
常用操作:
# 用户确认收货地址后,只更新 bizState
HSET memory:context:{sessionId} bizState '{"address":"公司","deliveryType":"immediate","payStatus":"unpaid"}'
# 订单模块只读取购物车和 SKU
HGET memory:context:{sessionId} order
# 意图识别需要全局信息时,读取完整上下文
HGETALL memory:context:{sessionId}
# 设置 30 分钟过期
EXPIRE memory:context:{sessionId} 1800
Hash 的价值在于 field 级读写。搜索模块更新推荐商品时,只写 search;订单模块更新购物车时,只写 order。如果把所有业务状态塞进一个大 JSON 字符串,任何模块更新都要经历“读完整 JSON → 修改一小块 → 写回完整 JSON”,并发时更容易互相覆盖。
其他辅助数据结构
短期记忆并不只需要 List 和 Hash。会话状态标记、分布式锁这类简单数据,可以用 String:
| 数据 | 推荐结构 | 操作特点 |
|---|---|---|
| 对话历史 | List | 按时间追加,按范围读取 |
| 业务上下文 | Hash | 按 field 局部读写 |
| 会话状态标记 | String | 简单状态值,读写成本低 |
| 分布式锁 | String | SET NX EX 实现会话级互斥 |
一轮对话的记忆读写流程
把模型记忆、业务上下文和分布式锁组合起来,一轮对话可以按这个流程执行:
flowchart TD
A[收到用户消息] --> B[获取会话级锁]
B -->|成功| C[读取模型记忆 List]
B -->|失败| R[重试或返回排队提示]
C --> D[读取业务上下文 Hash]
D --> E[意图识别与模型推理]
E --> F[调用搜索、购物车、订单等工具]
F --> G[更新业务上下文 Hash]
G --> H[追加模型记忆 List]
H --> I[刷新相关 Key 的 TTL]
I --> J[释放会话级锁]
J --> K[返回用户响应]
这里的锁粒度应该是会话级,而不是全局级。不同用户的会话互不影响,同一个用户的同一会话才需要串行化写入。
并发控制:用 Tair 分布式锁保护同一会话
同一会话可能出现并发写入,例如:
- 用户连续快速发送两条消息;
- Agent 正在流式回复时,用户又输入了新指令;
- 前端重试导致同一请求被重复提交;
- 多个工具调用完成顺序不稳定,同时回写上下文。
如果没有并发控制,就可能出现状态覆盖:
sequenceDiagram
participant R1 as 请求 A
participant R2 as 请求 B
participant M as Tair Hash
R1->>M: 读取 order = 空购物车
R2->>M: 读取 order = 空购物车
R1->>M: 写入 order = 伯牙绝弦
R2->>M: 写入 order = 桂花乌龙
最后只剩“桂花乌龙”,请求 A 写入的商品被覆盖了。
会话级锁可以用 SET NX EX 实现:
# 获取锁,requestId 必须是本次请求唯一值
SET lock:memory:{sessionId} {requestId} NX EX 3
含义:
| 参数 | 含义 |
|---|---|
lock:memory:{sessionId} | 锁 Key,同一会话共用一把锁 |
{requestId} | 锁持有者标识,用于安全释放 |
NX | Key 不存在时才写入,避免覆盖别人的锁 |
EX 3 | 3 秒后自动过期,避免进程异常退出后死锁 |
获取锁成功后,再执行记忆读写:
HSET memory:context:{sessionId} order '{"items":[{"skuId":"sku100","count":1}]}'
RPUSH memory:model:{sessionId} '{"role":"user","content":"就这个,少糖去冰"}'
RPUSH memory:model:{sessionId} '{"role":"assistant","content":"已加入购物车"}'
EXPIRE memory:context:{sessionId} 1800
EXPIRE memory:model:{sessionId} 1800
释放锁不能直接 DEL,否则可能删掉别的请求刚拿到的锁。正确做法是用 Lua 脚本判断锁值仍然是自己的 requestId:
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
end
执行方式:
EVAL "
if redis.call('GET', KEYS[1]) == ARGV[1] then
return redis.call('DEL', KEYS[1])
else
return 0
end
" 1 lock:memory:{sessionId} {requestId}
锁超时时间要结合业务耗时设置。过短会导致请求还没写完锁就过期,后续请求进入临界区;过长会让异常请求阻塞会话。对于耗时不稳定的链路,可以把锁内逻辑控制得尽量短:只保护“读当前状态、计算新状态、写回状态”这段关键区,模型推理和远程工具调用尽量不要长时间占着锁。
高峰流量下的扩展设计
Agent 记忆层的访问量通常会被放大。一次用户请求可能触发多次 Tair 操作,用户侧 QPS 增长 10 倍,Tair 操作量可能增长到更高量级。
Tair 在这类场景里主要靠几类能力抗压:多线程内核、读写分离、分片扩展、带宽弹性和 TTL 自动清理。
多线程内核提高单节点吞吐
开源 Redis 的核心执行模型以单线程事件循环为主,单个实例很容易受限于单核 CPU(中央处理器)能力。Tair 企业版内存型采用多线程模型,可以更充分利用多核资源,在相同规格下承载更多读写操作。
对 Agent 记忆层来说,单节点吞吐很重要。因为一次会话里的操作很碎,可能包含 LRANGE、HGETALL、HSET、RPUSH、EXPIRE、锁获取和锁释放。单节点处理能力越高,越不容易在热点时段形成排队。
读多写少:用读写分离承接推理前读取
Agent 记忆访问通常是读多写少。每轮推理前要读取历史对话和业务上下文,写入则集中在工具调用完成或一轮对话结束后。读写比可能达到 5:1 到 10:1。
读写分离可以把读请求分散到只读副本:
flowchart LR
A[Memory Service] --> R{请求类型}
R -->|写入 HSET/RPUSH/EXPIRE| P[(主节点)]
R -->|读取 LRANGE/HGET/HGETALL| S1[(只读副本 1)]
R -->|读取| S2[(只读副本 2)]
R -->|读取| S3[(只读副本 N)]
P -.复制.-> S1
P -.复制.-> S2
P -.复制.-> S3
不同流量阶段可以采用不同配置:
| 阶段 | 配置示例 | 目的 |
|---|---|---|
| 日常流量 | 8 分片,每分片 1 个只读副本 | 覆盖常规读写压力 |
| 读流量突然升高 | 每分片扩到 5 个只读副本 | 主要增加读吞吐 |
| 读写都升高 | 16 分片,每分片 3 个只读副本 | 同时增加读写能力 |
对会话记忆服务而言,扩缩容过程是否影响业务很关键。传统 Redis Cluster 在 Slot 迁移期间,客户端可能收到 -ASK、-TRYAGAIN 等响应,需要客户端正确处理重定向和重试。Agent 对话链路里,一次失败可能造成对话中断或状态缺失。
Tair 云原生版通过 Slot 级迁移和控制组件协调,尽量把扩缩容对业务的影响压低。迁移末期某些 Slot 的写请求延迟可能略有上升,但目标是不让请求失败,不让应用层为扩缩容改造大量逻辑。
带宽可能比 CPU 更早成为瓶颈
传统缓存场景经常是简单 KV 读写,单次响应很小。Agent 记忆读取不同,它可能一次拉取多轮对话、候选商品摘要、购物车、地址、优惠信息。单次数据包更大,带宽可能先于 CPU 和内存成为瓶颈。
Tair 云原生架构可以从两个层面处理带宽压力:
| 机制 | 作用 |
|---|---|
| 集群带宽水平扩展 | 通过增加 LB(Load Balancer,负载均衡)数量提高实例总带宽 |
| 弹性突发带宽 | 瞬时流量超过固定带宽时,按分片自动扩展带宽,流量回落后回收 |
弹性突发带宽按分片生效很有用。假设某个热点会话或热点 Key 导致一个分片带宽吃紧,只需要让该分片突发扩展,不必把整个集群都升到更高规格。
TTL 让短期记忆自动冷却
短期记忆的生命周期通常跟会话绑定。用户结束对话后,模型历史和业务上下文不需要长期占用内存。
所有会话 Key 都应该设置 TTL:
EXPIRE memory:model:{sessionId} 1800
EXPIRE memory:context:{sessionId} 1800
如果每次用户继续对话都刷新 TTL,会话活跃期间数据保留;用户离开后,数据在 30 分钟左右自动清理。
flowchart LR
A[用户开始会话] --> B[创建 memory:model 和 memory:context]
B --> C[每轮对话刷新 TTL]
C --> D{用户是否继续交互}
D -->|是| C
D -->|否| E[TTL 到期]
E --> F[自动删除会话记忆]
这种方式可以让活动流量过去后,内存占用自然下降,不需要人工扫描和清理历史会话。
Pipeline 可以减少网络往返,但不能替代事务
一轮对话里常常有多个 Tair 命令。如果命令之间没有强依赖,可以用 Pipeline 批量发送,减少网络往返时间。
例如读取阶段可以把多个读操作放在一个 Pipeline:
LRANGE memory:model:{sessionId} -20 -1
HGETALL memory:context:{sessionId}
GET memory:state:{sessionId}
写入阶段也可以批量发送:
HSET memory:context:{sessionId} order '{...}'
RPUSH memory:model:{sessionId} '{...}'
EXPIRE memory:context:{sessionId} 1800
EXPIRE memory:model:{sessionId} 1800
但 Pipeline 只减少 RTT(Round-Trip Time,往返时间),不保证一组命令原子执行。如果多个字段必须一起成功或一起失败,需要考虑 Lua 脚本、事务或更高层的幂等设计。
适合和不适合的场景
Tair 作为短期记忆层,适合会话状态频繁读写、延迟敏感、生命周期较短的 Agent 系统。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 多轮对话上下文 | 适合 | List 能按顺序保存最近几轮消息 |
| 订单、地址、购物车等结构化会话状态 | 适合 | Hash 支持按业务域局部更新 |
| 秒级响应的工具调用编排 | 适合 | 内存读写延迟低,适合放在在线链路 |
| 活动峰值明显的业务 | 适合 | 分片、只读副本、带宽突发可以按需扩展 |
| 需要永久保存的用户画像 | 不适合作为唯一存储 | Tair 更适合在线热数据,长期数据应落到持久化数据库或向量库 |
| 强事务、多表关联的复杂订单系统 | 不适合作为主系统 | 订单主状态仍应由事务型数据库承载 |
| 大体积原始工具响应归档 | 不适合直接塞进记忆 | 会增加内存和带宽压力,应做摘要或外部存储 |
落地时容易踩的坑
1. 把完整接口响应写进模型记忆
商品搜索、优惠查询、门店列表的原始响应可能非常大。如果完整写入 List,后果会很明显:
- 模型上下文 Token 增加;
- Tair 内存占用增加;
LRANGE读取时网络包变大;- 高峰期带宽更容易成为瓶颈。
更合理的做法是保存模型决策需要的信息:
{
"recommended": [
{"itemId": "i100", "name": "伯牙绝弦", "shopId": "s1"},
{"itemId": "i101", "name": "桂花乌龙", "shopId": "s1"}
],
"userNeedConfirm": ["规格", "糖度", "温度"]
}
2. 所有业务状态塞进一个 String
用一个大 JSON String 保存全部上下文,开发初期很方便,但并发写入时容易互相覆盖。只要状态可以按业务域拆分,就应该优先用 Hash field。
3. 锁里包含慢操作
会话级锁应该保护短时间内的状态读写,不应该长时间包住大模型推理或外部工具调用。远程调用耗时不可控,锁持有时间过长会导致同一会话后续消息排队,甚至锁过期后出现交错写入。
4. 只设置模型记忆 TTL,忘记业务上下文 TTL
memory:model:{sessionId} 和 memory:context:{sessionId} 应该一起过期。否则对话历史没了,业务上下文还在,后续可能读到残留购物车或旧地址。
5. 读写分离下忽略复制延迟
只读副本适合承担读流量,但主从复制存在极短延迟。对于“刚写完立刻必须读到”的关键路径,可以读主节点,或者在业务上接受短暂最终一致。比如下单前读取购物车这种强一致场景,更适合走主节点或由写入结果直接传递。
核心设计清单
| 能力 | 推荐做法 | 解决的问题 |
|---|---|---|
| 低延迟访问 | 使用 Tair 内存型实例 | 降低 Agent 在线链路中的记忆访问耗时 |
| 对话历史建模 | List + RPUSH + LRANGE | 保存有序多轮上下文 |
| 业务上下文建模 | Hash + field 级读写 | 避免大 JSON 回写和模块间覆盖 |
| 生命周期管理 | 所有会话 Key 设置 TTL | 会话结束后自动释放内存 |
| 并发安全 | 会话级 SET NX EX 锁 + Lua 释放 | 防止同一会话并发写入互相覆盖 |
| 高峰读流量 | 读写分离 + 只读副本 | 把推理前读取分散到副本 |
| 高峰读写流量 | 分片扩容 | 同时提高读写吞吐 |
| 大响应带宽压力 | 摘要化记忆 + 带宽弹性 | 减少传输体积,应对瞬时尖峰 |
| 网络往返优化 | Pipeline 批量发送命令 | 降低多命令场景下的 RTT |
短期记忆解决的是“这次会话正在发生什么”。当 Agent 需要进一步理解“这个用户长期喜欢什么、历史上经常点什么、有哪些稳定偏好”时,还需要建设长期记忆。长期记忆通常会结合关系型数据库、向量检索、特征存储等系统,而 Tair 仍然适合承担在线链路里的热状态缓存和会话记忆。