Harness Engineering 解决的不是“怎么问 AI”
Prompt Engineering 关注的是“怎么把问题说清楚”,Context Engineering 关注的是“给模型看什么信息”,而 Harness Engineering 关注的是一个更大的问题:
怎样给 AI Agent 搭一套可控的运行环境,让它不仅能完成任务,还能按规则完成任务。
Harness 这个词本来指马具、挽具。马本身有力量,但如果没有缰绳、马鞍、车架、道路和围栏,它很难稳定地把货拉到目的地。放到 AI Agent 上也一样,模型能力只是“马”的部分,真正决定工程可用性的,往往是围绕模型搭起来的那整套系统。
三者的边界可以用这张图表示:
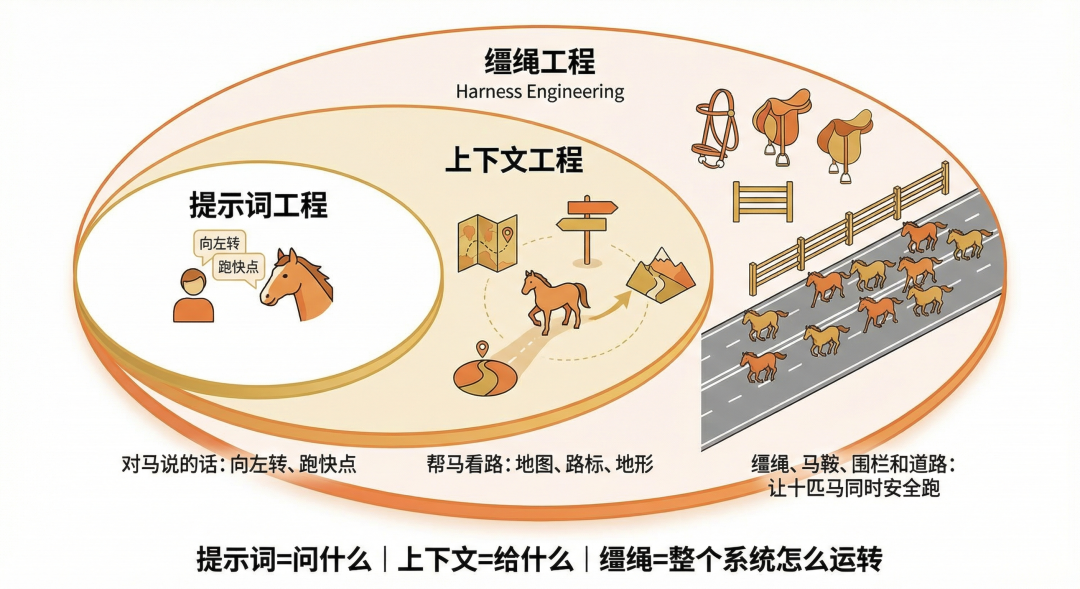
图里展示的是从 Prompt 到 Context,再到 Harness 的递进关系。Prompt 是一次对话里的指令,Context 是模型当前能看到的信息,而 Harness 把上下文、工具、权限、检查、反馈、错误恢复都纳入系统设计。换句话说,Context 是 Harness 的一部分,但 Harness 不止是“多塞点资料”。
| 层级 | 核心问题 | 常见手段 | 典型风险 |
|---|---|---|---|
| Prompt Engineering | 这次请求怎么说清楚 | 角色设定、任务描述、输出格式 | 对复杂任务不稳定,容易靠模型自觉 |
| Context Engineering | 模型应该看到哪些信息 | 代码索引、文档检索、状态摘要、知识库 | 上下文过多会挤占推理空间 |
| Harness Engineering | Agent 在什么规则下运行 | 工具编排、权限控制、Hooks、测试、Evaluator | 设计不好会把错误流程自动化 |
一个简单判断是:如果方案只改变“你对模型说什么”,那还是 Prompt;如果方案改变“模型看见什么”,就是 Context;如果方案改变“模型怎么行动、怎么被约束、错了怎么回收”,就进入 Harness。
为什么同一个模型换一套 Harness,结果会差很多
AI Agent 的能力不只取决于模型参数。实际工程里,一个 Agent 至少由这几部分组成:
flowchart LR
U[用户任务] --> R[任务路由]
R --> C[上下文选择]
C --> M[大模型]
M --> T[工具调用]
T --> G[硬性检查]
G -->|通过| O[产出结果]
G -->|失败| F[反馈与修正]
F --> M
K[(知识库)] --> C
P[权限与策略] --> T
E[Evaluator 评估器] --> G
模型只是中间的推理节点。任务路由决定它进入哪个工作区,上下文选择决定它能看到什么,工具系统决定它能做什么,硬性检查决定它做错时能不能继续往前走。任何一层设计得更好,同一个模型的表现都可能明显变化。
一个有代表性的数据来自 LangChain 的 coding agent:在 Terminal Bench 2.0 上,成绩从 52.8% 提升到 66.5%,排名从 Top 30 进入 Top 5。模型没有更换,主要调整的是系统提示词、工具配置和中间件钩子。
这说明一个很现实的问题:当模型已经足够强时,瓶颈常常转移到运行环境。模型会不会成功,不只看它“聪不聪明”,还要看它有没有清晰地图、合适工具、明确边界和可靠反馈。
Harness 的四个核心组件
一个能长期工作的 Harness,通常不靠某个神奇提示词,而是由几类机制共同组成。
1. 上下文工程:给地图,不给一本厚手册
上下文不是越多越好。模型的上下文窗口再大,也不应该把所有文档、所有代码、所有历史记录都塞进去。好的上下文更像地图:它告诉 Agent 当前项目有哪些区域、关键文件在哪里、约束是什么、遇到问题该去哪找信息。
一个项目级的 CLAUDE.md 或类似规则文件,可以写成路由器,而不是流水线说明书:
# Project Map
## Workspaces
- apps/web: 前端应用,使用 React 和 TypeScript
- services/api: 后端接口,使用 Node.js
- packages/ui: 共享组件库
- docs/adr: 架构决策记录
## Routing
- 修改 UI 组件时,先查看 packages/ui/README.md
- 修改接口时,先查看 services/api/openapi.yaml
- 涉及数据结构变化时,必须同步更新 docs/adr
## Hard Constraints
- 不允许绕过类型检查
- 不允许直接修改生成文件
- 不确定业务含义时,先提出问题,不要猜字段用途
这类文件不需要把每一步都写死。写得太细,Agent 会变成机械执行;写得太散,Agent 又会迷路。比较好的状态是:规则能指方向,细节让 Agent 根据任务自己展开。
2. 工具与权限:让 Agent 只拿该拿的工具
Agent 能调用工具以后,能力会放大,风险也会放大。工具系统至少要回答三个问题:
| 问题 | 示例 |
|---|---|
| 它能用什么工具 | 读文件、改文件、运行测试、调用接口、查知识库 |
| 它什么时候能用 | 只有进入某个工作区后才能使用部署脚本 |
| 它用错了怎么办 | 命令失败后把错误反馈给模型,禁止重复破坏性操作 |
在 Claude Code 这类工具里,Skills 可以把能力拆成独立模块。比如一个 Skill 专门处理文档同步,另一个 Skill 专门处理图片生成,平时不占用上下文,需要时再加载。这样比把所有规则都写进一个巨大提示词更稳,因为每个能力包都有自己的入口、说明和边界。
3. 硬性约束:不要只写“请注意规范”
提示词里的提醒属于软约束,模型可能遵守,也可能忘记。工程里更可靠的方式是把关键要求做成硬门禁:不通过检查,就不能进入下一步。
| 软提醒 | 硬约束 |
|---|---|
| 请注意代码风格 | 保存后自动运行 lint,失败则阻塞 |
| 请保证类型正确 | 生成后自动运行 typecheck |
| 请不要破坏测试 | 改动后自动运行相关测试 |
| 请遵守架构边界 | 用脚本检查跨模块依赖,违规直接失败 |
Hooks 就适合做这件事。它们可以在 Agent 执行关键动作前后插入脚本,把“建议”变成“物理拦截”。
示意配置可以长这样:
hooks:
before_edit:
- name: prevent-generated-file-edit
run: scripts/check-generated-files.sh
after_write:
- name: lint-changed-files
run: npm run lint:changed
- name: typecheck
run: npm run typecheck
before_finish:
- name: test-related
run: npm run test:related
policy:
block_on_failure: true
这类机制的价值在于,Agent 不需要每次都“记得”规范。规范已经进入运行环境,只要不符合,就过不去。
4. Evaluator:让另一个 AI 专门挑错
让生成者检查自己,效果通常不如让独立评估者检查。生成模型刚完成一段方案时,容易沿着自己的思路继续合理化错误;另一个上下文干净的评估者,更容易发现遗漏、矛盾和边界问题。
最简单的做法是把生成和评估分成两轮:
sequenceDiagram
participant User as 用户
participant Gen as 生成 Agent
participant Eval as 评估 Agent
participant Test as 测试/检查工具
User->>Gen: 提交任务
Gen->>Gen: 设计方案并修改文件
Gen->>Test: 运行 lint/typecheck/test
Test-->>Gen: 返回检查结果
Gen-->>User: 给出候选结果
User->>Eval: 提供任务、改动和候选结果
Eval->>Eval: 查找问题、矛盾和遗漏
Eval-->>User: 输出风险清单和修复建议
评估提示词可以很直接:
你是独立评估者,不负责继续实现功能,只负责找问题。
请检查:
1. 结果是否满足任务目标
2. 是否有未覆盖的边界情况
3. 是否引入架构违规
4. 是否存在过度实现
5. 是否有测试缺口
6. 文档、类型、接口是否一致
输出格式:
- 严重问题
- 一般问题
- 可接受但需要记录的风险
Anthropic 的三 Agent 方案也是这个思路的工程化版本。
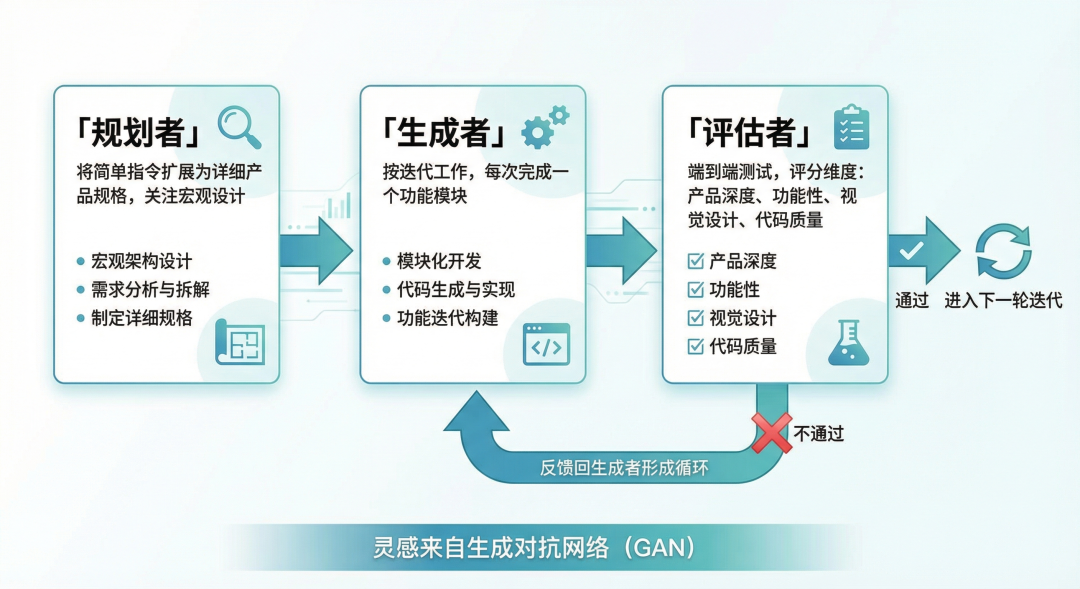
这张图把任务拆成了 Planner、Generator、Evaluator 三个角色。Planner 把用户的简单意图扩展成更完整的规格,Generator 按迭代实现功能,Evaluator 通过端到端测试和检查机制不断挑错。它的关键点不是“多开几个 Agent”,而是把规划、生成和评估拆成不同职责,避免一个 Agent 既当运动员又当裁判。
这种设计和生成对抗网络(GAN,Generative Adversarial Network)的思路有些相似:生成者负责产出,评估者负责施压。评估者越能稳定指出问题,生成者越容易沿着正确方向修正。
OpenAI 案例说明了速度,也暴露了质量问题
OpenAI Codex 团队曾公开过一个很激进的案例:少量工程师在数月内用 Codex 推动了一个百万行级别的 beta 产品,合并了约 1500 个 Pull Request(PR,代码合并请求),每名工程师每天处理多个 PR,估算速度远高于传统开发方式。
这些数字说明 AI Agent 可以显著提高产出速度,但速度不等于可维护性。百万行代码真正困难的地方,往往不在“写出来”,而在后续几个月不断改需求、修 Bug、调整架构时还能不能看懂、能不能安全修改。
AI 生成代码有一个典型风险:它倾向于解决眼前任务,而不是天然为未来维护者留下结构线索。人类工程师写代码时,通常会根据经验控制抽象层级、命名、模块边界和演进空间;Agent 如果没有 Harness 约束,很容易写出“当前能跑,但后面难改”的实现。
所以,Harness Engineering 不能只追求更快生成代码,还要把可维护性纳入系统:
| 目标 | Harness 里的对应机制 |
|---|---|
| 防止乱改架构 | 架构边界检查、依赖扫描、ADR 约束 |
| 防止测试缺失 | 改动关联测试、覆盖率门禁、端到端测试 |
| 防止文档过期 | 文档一致性检查、接口变更同步规则 |
| 防止上下文污染 | 任务级上下文压缩、定期重置、知识库检索 |
| 防止重复犯错 | 错误模式沉淀为规则或 Hook |
能写得快只是第一步,能持续改才是工程问题。
Harness 不是越大越好
一个反直觉结论是:更大的上下文、更复杂的规则、更厚的说明,不一定带来更好的 Agent 表现。
Anthropic 曾讨论过 Claude Sonnet 4.5 在长上下文下的表现问题:当上下文过多时,模型可能开始过度关注无关细节,或者在大量历史信息里摇摆,导致执行质量下降。可以把这理解成一种“上下文焦虑”:模型不是不知道信息,而是信息太多以后,难以判断什么最重要。
实用做法是控制上下文密度:
| 问题 | 更好的做法 |
|---|---|
| 把全部文档塞进窗口 | 用检索按需加载 |
| 聊天历史无限延长 | 阶段性总结,必要时新开任务 |
| 规则文件持续膨胀 | 定期删除过期规则,合并重复规则 |
| 每个任务都加载全部 Skills | 按任务路由加载最小能力集 |
| 用自然语言提醒所有规范 | 关键规范下沉到测试和 Hook |
Harness 的目标不是“包办一切”,而是让 Agent 在刚好足够的约束中工作。约束太少会失控,约束太多会僵化。
从零搭建一个可用 Harness
不需要一开始就设计复杂平台。一个小型项目可以从三个文件、两类脚本、一个评估流程开始。
项目地图:CLAUDE.md
把它当成 Agent 的入口地图:
# Agent Guide
## What this project does
这是一个任务管理应用,包含 Web 前端和 API 服务。
## Directory map
- apps/web: 前端页面
- services/api: 后端接口
- packages/shared: 共享类型与工具
- docs/adr: 架构决策记录
## Before editing
- 先确认改动属于哪个 workspace
- 涉及接口字段时,检查 openapi.yaml
- 涉及共享类型时,检查 packages/shared
## Never do
- 不要直接编辑 dist、build、generated 目录
- 不要跳过 failing test
- 不要在没有说明的情况下引入新框架
## Finish criteria
- lint 通过
- typecheck 通过
- 相关测试通过
- 如果接口变化,文档同步更新
关键是保持它短、准、可维护。每条规则最好对应真实出现过的问题,而不是预先写一堆“也许会有用”的要求。
错误沉淀:每次犯错只加一条规则
Harness 最自然的生长方式是从错误里长出来。Agent 犯了一次错,就把这类错误转成规则、测试或 Hook。
flowchart TD
A[Agent 犯错] --> B{错误是否可自动检测}
B -->|可以| C[写成测试或 Hook]
B -->|不可以| D[写进规则文件]
C --> E[下次自动阻断]
D --> F[下次进入上下文提醒]
E --> G[定期清理与合并]
F --> G
需要注意:能写成自动检查的,不要只写进提示词。提示词适合描述方向,门禁适合保证底线。
独立评估:把审查流程固定下来
即使没有复杂的多 Agent 平台,也可以手动执行评估流程:
- 让生成 Agent 完成任务。
- 保存 diff、测试结果和实现说明。
- 新开一个评估上下文。
- 只让评估者找问题,不让它继续写功能。
- 把评估结果分成“必须修”和“可记录风险”。
这个流程尤其适合代码审查、文档生成、需求拆解、测试用例补全等任务。它不要求评估者完美,只要能稳定发现生成者漏掉的一部分问题,就已经能提高整体质量。
哪些场景适合投入 Harness
Harness Engineering 有成本,不是所有任务都值得做。判断标准主要看任务是否重复、结果是否需要长期维护、错误是否会带来明显代价。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 长期维护的代码库 | 适合 | 规则、测试和知识库能持续复用 |
| 自动化写作或报告生成 | 适合 | 可以沉淀风格、结构、检查流程 |
| 内部工具开发 | 适合 | 需求重复,错误模式容易归纳 |
| 一次性问答 | 不太适合 | 搭 Harness 的成本可能高于收益 |
| 没有测试的复杂系统 | 谨慎 | Agent 产出难以验证,容易把错误自动化 |
| 安全关键系统 | 必须谨慎 | 需要人类强审查、形式化验证或更严格流程 |
投入 Harness 的前提不是“模型能不能写”,而是“结果能不能被验证”。没有验证机制,Agent 越自动化,风险越大。
人类不能太早退出循环
AI Agent 越强,越容易让人产生一种错觉:既然它能写代码、跑测试、修 Bug,人类只需要站在旁边看结果。但 Harness 本身仍然需要人来设计,而设计 Harness 需要经验。
这里的经验不一定只来自手写代码,也可能来自大量和 Agent 协作:知道它什么时候会偷懒,什么时候会幻觉,什么时候需要硬约束,什么时候只需要给方向。无论经验来自传统编程还是人机协作,本质上都需要大量反馈循环。
过早把人类从“参与执行”移到“旁路监督”,会带来一个长期问题:新人没有足够机会理解系统细节,也没有足够机会观察错误模式,自然难以设计出可靠 Harness。到那时,自动化系统看起来还能跑,但没人真正知道它为什么这样跑、哪里可能出问题、规则该怎么调整。
比较稳妥的分工是:
| 阶段 | 人类职责 | Agent 职责 |
|---|---|---|
| 早期探索 | 明确目标、判断方向、识别错误模式 | 生成方案、尝试实现、暴露问题 |
| 流程稳定 | 把重复错误转成规则和测试 | 在规则内高频执行 |
| 规模扩大 | 设计 Harness、审查架构、处理例外 | 批量修改、运行检查、生成候选方案 |
| 长期维护 | 清理过期规则、调整边界、培养新人 | 执行标准流程、辅助评估 |
Harness Engineering 的核心不是给旧概念换一个新名字,而是把 AI Agent 的使用方式从“会聊天的工具”推进到“受控的工程系统”。当模型足够强时,真正拉开差距的就是这套系统:给它什么上下文,开放什么工具,设置什么门禁,如何评估结果,以及怎样把每次失败变成下一次不会再犯的规则。