AI(Artificial Intelligence,人工智能)导购和普通聊天机器人最大的区别在于:它不能只“说得像”,还要“查得到、选得准、答得稳”。
在租赁场景里,用户的问题往往不是标准商品搜索词,而是一个带场景、预算、用途和风险顾虑的自然语言需求:
我想租个相机去西藏旅游,要轻便一点,还能拍星空,有什么推荐?
一个可靠的租赁导购助手需要完成几件事:
- 理解“西藏旅游”“轻便”“拍星空”背后的设备要求;
- 查询商品库,找到真实可租的商品;
- 必要时检索平台规则、租期保障、赔付政策;
- 根据商品、租期、预算和服务保障生成推荐理由;
- 不能编造商品 ID、价格、库存、服务条款。
这类任务天然适合 Tool-Use(工具调用):大语言模型负责理解和决策,商品库、知识库、搜索服务、订单系统等外部工具负责提供事实。但要把工具调用训练到稳定可用,单靠监督微调并不够,需要引入 ToolRL(面向工具调用的强化学习)来优化模型的决策策略。
租赁导购为什么比普通 ToolCall 更难
普通工具调用通常是单步任务。比如查天气:
用户:今天北京天气怎么样?
模型:weather_search(city="北京")
工具:返回天气数据
模型:组织回答
这个链路很短,工具选择明确,参数也简单。即使失败,后续影响也有限。
租赁导购不同。一次成功推荐通常需要多次调用工具,而且每一步会影响后续路径:
flowchart TD
A[用户提出场景化需求] --> B[理解用途和约束]
B --> C{是否需要补充知识}
C -- 需要 --> D[knowledge_search 检索攻略/规则/评测]
C -- 不需要 --> E[search_db 搜索商品库]
D --> E
E --> F{是否找到合适商品}
F -- 没找到 --> G[放宽条件或换关键词再次搜索]
G --> E
F -- 找到 --> H[商品对比/服务条款核验]
H --> I[生成推荐和风险提示]
仍然以“租相机去西藏旅游,要轻便又能拍星空”为例,一个合理的工具链可能是:
1. knowledge_search("西藏旅游 相机 轻便 拍星空")
-> 理解高海拔旅行、夜景、续航、镜头重量等约束
2. search_db(
product_type="相机",
key_features=["轻便", "高感光度", "夜景"],
rental_duration="15天"
)
-> 初步召回商品
3. search_db(
product_type="相机",
brand="",
key_features=["高感光度", "可换镜头"]
)
-> 如果结果不足,放宽品牌或型号限制
4. compare_products(product_ids=[...])
-> 对候选商品做参数和租赁服务对比
5. item_card(product_ids=[...])
-> 返回可展示的商品卡片
商品搜索工具的参数也远比天气查询复杂。一个搜索工具可能包含 20 多个维度:
{
"product_type": "相机",
"brand": "索尼",
"models": ["A7C", "A7III"],
"key_features": ["轻便", "高感光度", "夜景"],
"price_range": {
"min": 80,
"max": 150
},
"rental_duration": "15天",
"service_guarantees": ["免赔保障", "租期质保"]
}
这会带来三个典型错误:
| 错误类型 | 表现 | 后果 |
|---|---|---|
| 工具选择错误 | 应该查商品库,却去查通用知识库 | 推荐链路中断 |
| 参数错误 | 把用途误填成型号,把预算误填成租期 | 召回结果偏离需求 |
| 调用幻觉 | 编造不存在的商品 ID 或卡片 | 用户看到不真实商品 |
即使是能力很强的基座模型,在复杂工具调用上也不能直接假设可靠。TauBench 的 Retail 领域评测能反映这种难度。
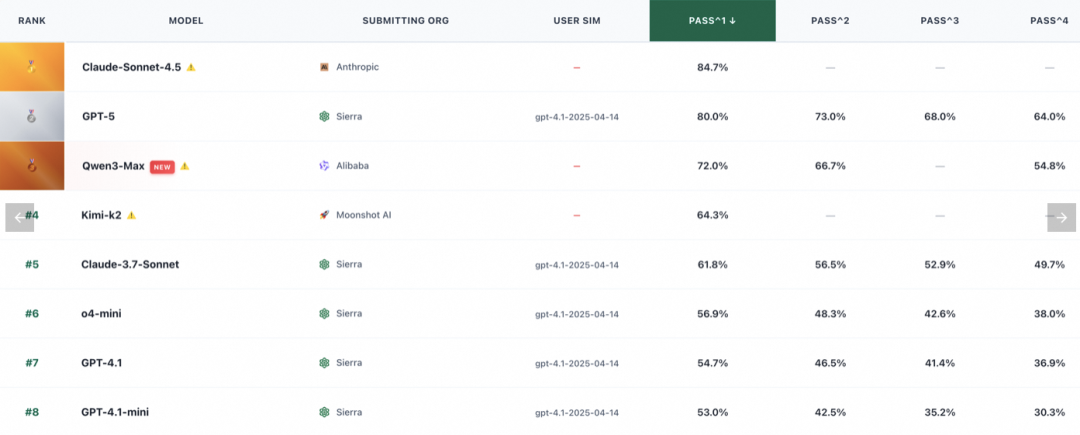
图中的关键点是:在接近零售导购的 Tool-Use 任务里,顶级模型的一次成功率也没有达到 100%。例如 Claude-Sonnet-4.5 的 Pass^1 为 84.7%,多次尝试后的成功率还会下降。这说明模型“会调用工具”和“能稳定完成复杂业务链路”之间,还有一段训练和工程距离。
从多 Agent 串行链路改成 One-Model + Tool-Use
早期常见做法是多 Agent(多智能体)串行架构:
flowchart LR
U[用户 Query] --> R[Rewrite Agent]
R --> P[Planning Agent]
P --> K[Retrieval Agent]
K --> D[导购 Agent]
D --> A[回答用户]
这种架构看起来职责清晰,但在导购场景里有两个问题。
一是延迟高。每个 Agent 都可能是一次独立模型调用,多个模型串起来后,P99(第 99 百分位)首字延迟容易被放大。实践中,串行链路的首字耗时曾达到 5.1 秒左右。
二是能力重叠。知识问答 Agent、导购 Agent、搜索 Agent 往往都需要“检索”“全网搜”“商品理解”能力。每增加一个 Agent,就要重复训练、评估和部署一部分能力,成本会随 Agent 数量上升。
更适合复杂导购的结构是 One-Model + Tool-Use:一个统一大模型负责全局决策,所有外部能力沉淀成工具,由模型按需调用。
flowchart TD
U[用户输入] --> M[统一大模型]
M --> T{是否需要工具}
T -- 否 --> A[直接回答]
T -- 是 --> C[生成 tool_call]
C --> E[工具执行器]
E --> O[工具返回 observation]
O --> M
M --> A
这个流程本质上是 ReAct(Reasoning and Acting,推理与行动)范式:
- 模型根据上下文判断需要什么信息;
- 生成工具名和参数;
- 工具返回观察结果;
- 模型基于新信息决定继续调用工具,还是生成最终回答。
架构收敛后,冗余串行调用被砍掉,首字响应耗时可以从 5.1 秒降到 1.2 秒左右。更重要的是,训练目标也更清晰:不再分别训练多个 Agent,而是集中训练一个模型的工具决策能力。
工具设计:原子化,但不能碎片化
工具设计直接决定模型能否学会调用。工具太大,模型难以控制细节;工具太碎,决策链路会变长,延迟和失败概率都会上升。
比较稳妥的做法是:把业务能力抽象成原子操作,但对功能相似、互斥或高度相关的能力做合并。
常见工具可以这样拆:
| 工具 | 作用 | 典型场景 |
|---|---|---|
knowledge_search | 检索规则、攻略、评测、种草内容 | 用户问“租相机旅游要注意什么” |
search_db | 在商品库中召回真实商品 | 用户有明确品类、预算、租期 |
compare_products | 比较多个商品参数和租赁条件 | 用户纠结多个候选商品 |
order_query | 查询订单状态 | 租中履约问题 |
logistics_query | 查询物流信息 | 发货、到达、归还 |
item_card | 生成商品卡片 | 最终推荐展示 |
followup_card | 生成追问卡片 | 需求缺少关键约束 |
知识检索工具尤其容易被拆碎。平台规则、全网评测、生活方式内容,当然可以分别设计成 internal_search、web_search、xiaohongshu_search。但用户的问题经常很模糊,模型可能同时调用多个搜索工具,造成并发浪费,还会增加结果整合难度。
更好的做法是合并成一个工具,用参数区分知识域:
{
"name": "knowledge_search",
"description": "搜索知识库或外部信息源,根据问题类型选择合适的知识域。",
"parameters": {
"query": {
"type": "string",
"description": "搜索关键词"
},
"domain": {
"type": "string",
"enum": ["internal_kb", "web", "xiaohongshu"],
"description": "internal_kb 用于平台规则;web 用于全网信息;xiaohongshu 用于生活方式和产品种草内容。"
}
}
}
如果一次调用需要多个知识域,也可以把 query 和 domain 设计成数组组合:
{
"queries": [
{
"query": "西藏旅游 相机 续航 高反 注意事项",
"domain": "web"
},
{
"query": "相机租赁 免赔保障 租期质保",
"domain": "internal_kb"
}
]
}
工具设计的核心原则可以压缩成一句话:让模型少做无意义选择,把选择空间留给真正影响结果的地方。
SFT 为什么难以训练好工具调用
SFT(Supervised Fine-Tuning,监督微调)适合让模型学习格式和风格,但复杂 Tool-Use 场景里,它有两个明显短板。
工具调用 token 太稀疏
一段导购对话中,大部分 token 是自然语言,真正决定工具调用的 token 只占很小比例,比如工具名、JSON 参数、商品 ID、工具边界符。SFT 对所有 token 做同等训练,模型很容易把主要学习能力花在“回答怎么写”上,而不是“工具什么时候调、参数怎么填”。
模仿格式不等于学会策略
SFT 的训练目标是拟合标注答案。模型可以学会:
{
"name": "search_db",
"arguments": {
"product_type": "相机"
}
}
但它不一定学会这些策略:
- 第一次没搜到商品时,应该放宽哪个条件;
- 用户只问平台规则时,不应该触发商品召回;
- 生成商品卡片前,必须先拿到真实商品 ID;
- 工具返回冲突信息时,应该以哪个来源为准;
- 哪些问题需要追问,而不是强行推荐。
这就是强化学习进入的原因。RL(Reinforcement Learning,强化学习)不要求模型只模仿一个固定答案,而是根据结果奖励来调整策略。对于工具调用来说,奖励可以来自格式校验、工具执行结果、标准答案匹配、AI 裁判评分等信号。
多阶段 ToolRL:先管住格式,再优化回答质量
训练目标可以拆成两个阶段:先让模型“不要乱调”,再让模型“调得更好、答得更好”。
flowchart TD
A[SFT 初始化模型] --> B[阶段一:规则奖励 RL]
B --> C[工具格式稳定]
C --> D[阶段二:LLM-as-Judge 奖励 RL]
D --> E[回答准确性、完整性、表达质量提升]
E --> F[离线评测与线上验证]
阶段一:Rule-Based Reward 管住工具语法
Rule-Based Reward 指基于规则的奖励。它不关心回答文采,只检查工具调用是否符合业务约束。
可以校验的规则包括:
| 校验项 | 示例 |
|---|---|
| JSON 是否合法 | 参数不能缺括号、缺引号、类型错误 |
| 工具名是否存在 | 不能调用未注册工具 |
| 参数是否在 schema 内 | domain 只能取枚举值 |
| 参数依赖是否满足 | 生成商品卡片前必须先调用商品搜索 |
| 是否存在商品幻觉 | 不能输出工具未返回的商品 ID |
| 是否过度调用 | 用户只闲聊时不应调用商品工具 |
| 是否漏调用 | 明确要推荐商品时不能只凭语言回答 |
一个简化的规则奖励可以写成:
def rule_reward(sample):
score = 1.0
if not is_valid_json(sample.tool_call):
score -= 0.5
if not tool_exists(sample.tool_name):
score -= 0.5
if not match_schema(sample.tool_name, sample.arguments):
score -= 0.4
if sample.output_contains_item_card and not sample.has_called("search_db"):
score -= 0.8
if contains_fake_product_id(sample.output, sample.tool_observations):
score -= 1.0
return max(score, -1.0)
这个阶段的价值是快速消灭低级错误。模型一旦稳定遵守工具语法和依赖关系,后续训练才有意义。
阶段二:LLM-as-Judge 优化语义质量
LLM-as-Judge 指用另一个 LLM(Large Language Model,大语言模型)充当裁判,对模型回答打分。它适合评估规则难以覆盖的部分,比如回答是否完整、推荐理由是否贴合用户需求、是否正确引用工具结果。
裁判模型不一定要特别大。实践中可以使用 4B 参数量级的轻量模型,在零温度封闭 prompt 下打分,减少裁判自身的随机性和幻觉。只要裁判在语义等价判断上足够稳定,就能为 RL 提供可用的相对排序信号。
一个裁判 prompt 可以约束成固定评分维度:
你是租赁导购回答质量评估器。根据用户问题、工具返回结果、参考答案和待评估回答打分。
评分维度:
1. 准确性:是否符合工具返回事实,是否编造商品、价格、政策。
2. 完整性:是否覆盖用户需求中的用途、预算、租期、风险点。
3. 决策帮助:是否给出清晰推荐理由和选择建议。
4. 表达质量:是否自然、清楚、不过度营销。
输出 JSON:
{
"accuracy": 0.0-1.0,
"completeness": 0.0-1.0,
"helpfulness": 0.0-1.0,
"fluency": 0.0-1.0,
"final_score": 0.0-1.0
}
裁判不需要给出绝对真理。RL 更关心同一批候选回答之间谁更好,只要排序比较稳定,奖励就有训练价值。轻量裁判的吞吐也很重要,例如单卡 32 sample/s 这类速度,才能支撑多样本采样训练。
稀疏奖励:复杂工具链里最难处理的问题
ToolRL 的一个核心难点是奖励稀疏。多步链路里,第一步搜索词稍微偏一点,后续商品召回、商品卡片、最终回答都会受影响,整条轨迹可能直接拿到最低奖励。
典型现象包括:
- 第一次搜索失败后,模型不会主动换关键词;
- 高温采样产生的多个样本都没有触发有效搜索;
- 一批样本的 reward 全部是
-1,模型无法区分哪个动作更接近正确方向; - 工具调用关键 token 探索不足,策略卡在局部最优。
为了让模型在工具调用区域有更大的探索空间,可以改造 GSPO(Group Sequence Policy Optimization,组级序列策略优化)的裁剪策略。
标准 PPO/GSPO 类目标通常会限制策略更新幅度,避免模型一步更新过大:
[
L(\theta)=
\mathbb{E}
\left[
\min
\left(
r(\theta)A,
\text{clip}(r(\theta),1-\epsilon,1+\epsilon)A
\right)
\right]
]
其中:
- (r(\theta)) 是新旧策略概率比;
- (A) 是 advantage,表示当前动作相对平均水平好多少;
- (\epsilon) 是裁剪范围,用来限制更新步长。
普通自然语言 token 和工具调用 token 的重要性不同。工具调用区域决定“调哪个工具、填什么参数”,探索空间更大;自然语言区域主要负责表达,通常不希望剧烈变化。因此可以把 token 分成两类,使用不同的裁剪范围:
[
\epsilon_t =
\begin{cases}
\epsilon_{tool}, & t \in T_{tool} \
\epsilon_{text}, & t \in T_{text}
\end{cases}
\quad
\text{且}
\quad
\epsilon_{tool} > \epsilon_{text}
]
混合裁剪后的目标可以理解为:
[
L(\theta)=
\mathbb{E}
\left[
\sum_t
\min
\left(
r_t(\theta)A_t,
\text{clip}(r_t(\theta),1-\epsilon_t,1+\epsilon_t)A_t
\right)
\right]
]
也就是说:
- 工具调用 token 使用更大的 clip,让模型敢于调整工具名、参数和搜索策略;
- 自然语言 token 使用较小的 clip,避免回答风格和基础语言能力震荡。
实验中,放大工具调用区域的 clip 后,reward 全为最低值的样本数量明显下降。
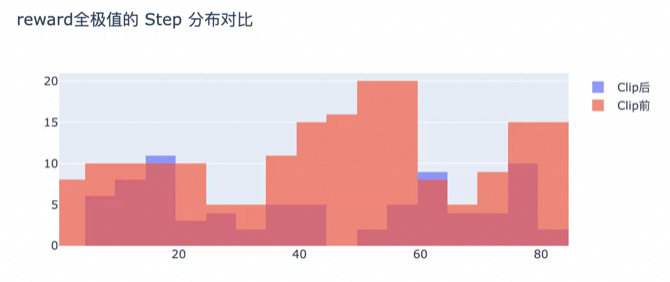
图里横轴是训练 step,纵轴是 reward 为 -1 的样本数量。数量下降说明模型更容易探索到非失败轨迹,训练不再频繁陷入“整批样本没有学习信号”的状态。
不过,clip 变大只是允许模型迈更大的步子,不代表方向一定正确。如果 advantage 估计不准,大步更新会把策略推向错误方向,导致震荡甚至塌陷。因此训练中需要持续监控 KL(Kullback-Leibler divergence,KL 散度),并不断提高 reward model 的稳定性。
还有一个实用做法:把同 batch 里的样本按“含工具调用”和“纯语言”拆成两个 replay pool,采样时保持 1:1 比例,但 loss 计算仍然用同一次 forward。这样能降低不同类型样本之间的梯度干扰。
评测结果:工具参数、格式幻觉和推荐成功率都要看
复杂导购模型不能只看通用问答分数。更合理的评测集需要覆盖:
- 是否应该调用工具;
- 工具选择是否正确;
- 参数是否正确;
- 是否编造商品或服务信息;
- 工具返回为空时是否会重试或追问;
- 最终回答是否能帮助用户做决策。
一份 805 条样本的离线评测中,多阶段 RL 后有这些变化:
| 指标 | 训练前 | 训练后 | 变化 |
|---|---|---|---|
| 整体正确率 | 88.32% | 91.55% | +3.23% |
| 参数错误率 | - | - | 下降 2.11% |
| 格式幻觉问题 | - | - | 下降 0.87% |
业务评测还需要看完整链路表现:
| 指标 | 变化 |
|---|---|
| 非 3C 品类完整推荐成功率 | +14.93% |
| 端到端响应耗时 | 2850ms → 100ms |
这里的 3C 指 Computer、Communication、Consumer Electronics,也就是计算机、通信和消费电子类商品。非 3C 品类往往更依赖场景理解,例如露营设备、年会投影、旅拍器材,推荐成功率提升说明模型不只是记住了热门电子产品,而是学到了一部分跨品类导购策略。
MoE 训练:从 Zero3 到 6 维并行
当导购模型进一步升级到 MoE(Mixture of Experts,混合专家模型)架构时,训练和推理成本会成为新瓶颈。以 Qwen3-Next-80B-A3B 这类模型为例,它结合了高稀疏 MoE 架构和混合注意力机制,例如 Gated DeltaNet 与 Gated Attention,对训练稳定性、专家路由和推理一致性都有更高要求。
使用 Deepspeed Zero3 训练时,参数、梯度和优化器状态会被切分到不同 GPU(Graphics Processing Unit,图形处理器)。这种方式节省显存,但会带来大量跨节点通信。单次迭代耗时可能达到 93 秒,不利于快速迭代。
MoE 还有专家负载不均的问题:部分活跃专家处理了大量 token,另一些专家几乎闲置。比如前 10% 活跃专家可能处理超过 50% 输入 token,后 30% 专家只处理 5.7% token,计算资源没有被充分利用。
解决方向是引入 Megatron 的 6 维并行:
| 并行方式 | 英文 | 作用 |
|---|---|---|
| TP | Tensor Parallelism,张量并行 | 拆分单层矩阵计算 |
| PP | Pipeline Parallelism,流水线并行 | 按层切分模型 |
| DP | Data Parallelism,数据并行 | 多副本处理不同数据 |
| SP | Sequence Parallelism,序列并行 | 拆分序列维度计算 |
| CP | Context Parallelism,上下文并行 | 处理长上下文切分 |
| EP | Expert Parallelism,专家并行 | 分布 MoE 专家 |
在 8 机 64 卡 A100 集群中,可以配置:
TP = 4
PP = 8
EP = 2
DP = 1
一个热门专家的计算会先被 TP 拆成 4 份,再通过 EP 分布到专家组,随后嵌入 PP 的流水线阶段。原本可能集中压垮单卡的热点计算,被拆成多个小任务分摊到集群里。
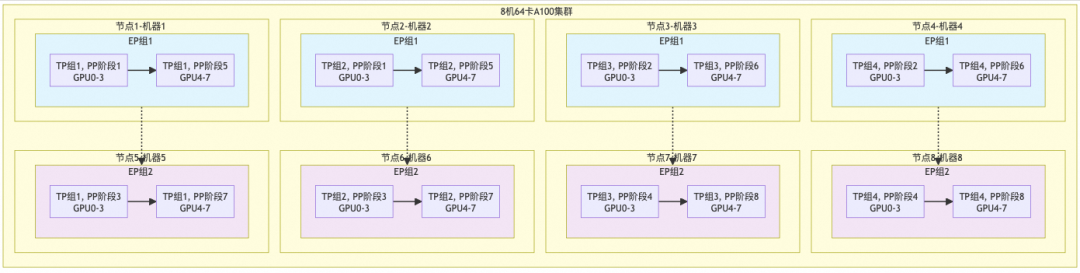
图中的核心结果是训练单步耗时从 93 秒降到 9.4 秒左右,接近 10 倍加速。对需要频繁采样、打分、更新的 RL 训练来说,这类工程优化会直接影响实验迭代速度。
MoE 推理:选择性量化比全量硬套更稳
推理部署的目标通常是:在保持精度的前提下降低显存占用。MoE 模型直接套用通用量化方案并不总是可行,常见问题有两个:
- AWQ(Activation-aware Weight Quantization,激活感知权重量化)等框架可能暂不支持特定新架构;
- MoE 的专家路由 Gating 与标准量化流程冲突,直接量化容易导致精度下降。
更稳的策略是选择性量化:
| 模块 | 是否量化 | 原因 |
|---|---|---|
标准 self-attention 的 o_proj | 是 | 参数量大,量化收益明显 |
MoE expert 的 up/down/gate | 是 | 专家层占用显存高 |
| 路由 Gating | 否 | 参数量不大,但影响专家选择 |
| 线性注意力相关层 | 否 | 容易造成模型掉点 |
这种做法在保持 99.5% 模型精度的同时,把推理显存占用降低 40.6%。在不增加推理资源的情况下,线上模型可以从 Qwen3-32B 迁移到 Qwen3-Next-80B-A3B。
落地时要重点盯住的坑
工具 schema 要稳定
工具名、参数名、枚举值、返回结构都要版本化。训练数据和线上工具 schema 不一致时,模型会生成“训练时见过、线上不存在”的参数。
工具返回必须可验证
商品推荐不能只返回自然语言摘要,最好返回结构化字段:
{
"product_id": "camera_123",
"name": "Sony A7C",
"rental_price_per_day": 120,
"stock_status": "available",
"service_guarantees": ["免赔保障", "租期质保"]
}
这样后续才能检查模型有没有编造商品、价格和保障条款。
工具调用要有依赖约束
例如:
flowchart LR
A[search_db] --> B[item_card]
A --> C[compare_products]
D[order_query] --> E[logistics_query]
item_card 必须依赖真实商品搜索结果,不能让模型凭空生成卡片。依赖关系既要写进 prompt,也要写进 rule reward。
LLM-as-Judge 要防止漂移
裁判模型本身也会出错。降低风险的方式包括:
- 使用零温度;
- 固定输出 JSON;
- 将评分维度拆细;
- 加入少量人工校准集;
- 监控裁判分与人工分的一致性;
- RL 中更重视相对排序,不把单个分数当绝对真值。
放大工具 token clip 要配合 KL 监控
工具区域更大的 clip 能增加探索,但也会增加训练不稳定风险。KL 曲线、reward 分布、工具调用频率、参数错误率要一起看。只看平均 reward,很容易错过策略塌陷的早期信号。
一套可复用的训练路线
把复杂导购助手训练稳定,可以按这条路线推进:
flowchart TD
A[梳理业务工具和 schema] --> B[构造 SFT 冷启动数据]
B --> C[训练基础 Tool-Use 能力]
C --> D[规则奖励 RL:格式和依赖约束]
D --> E[LLM-as-Judge RL:语义和回答质量]
E --> F[差异化 GSPO:工具 token 加强探索]
F --> G[离线评测:工具选择/参数/幻觉/回答]
G --> H[线上灰度:延迟/成功率/用户行为]
H --> I[MoE 训练和推理降本]
这套方案的关键不是某一个单点技巧,而是把架构、工具设计、奖励函数、策略优化和工程效率连起来:
- One-Model + Tool-Use 降低多 Agent 串行延迟;
- 原子化工具让模型的行动空间清晰可控;
- Rule-Based Reward 先保证工具调用不越界;
- LLM-as-Judge 再优化回答质量;
- 差异化 GSPO 让工具 token 获得更大探索步长;
- MoE 并行训练和选择性量化解决成本问题。
AI 导购要真正可用,核心标准不是“回答像不像人”,而是它能否在复杂业务链路里持续做对选择:该查时查、该搜时搜、搜不到会调整,拿到事实后再回答。ToolRL 的价值就在这里,它把模型从格式模仿推向结果驱动,让工具调用逐渐变成可训练、可评估、可上线的能力。