Tool Use 指大语言模型(LLM,Large Language Model)在回答问题时,不只依赖参数内部记忆,而是主动选择工具、生成调用参数、读取工具返回结果,再继续推理或给出答案。
这类能力让模型从“会聊天”进一步变成“能办事”。例如,一个租赁导购助手不能只回答“这款手机不错”,它还要能理解用户预算、租期、使用场景,查询商品库,结合租赁规则判断是否需要身份证审核,必要时触发服务卡片承接售后问题。
难点在于:模型要学会这件事,必须看过大量“用户问题 → 工具选择 → 工具参数 → 工具返回 → 最终回答”的完整轨迹。真实业务数据往往不够多、不够干净,也不一定覆盖复杂多轮场景,所以高质量合成数据就变成了训练 Tool Use 模型的关键环节。
1. 为什么普通指令数据不够训练 Tool Use Agent
常见的大模型训练路径可以拆成两类能力:
| 能力 | 典型数据 | 模型学到什么 | 局限 |
|---|---|---|---|
| 普通指令跟随 | 问答、摘要、改写、分类 | 按用户指令生成自然语言 | 不知道何时调用工具,也不知道参数怎么填 |
| 检索增强生成(RAG,Retrieval-Augmented Generation) | 查询 + 检索文档 + 回答 | 基于外部知识回答 | 多数是单次检索,工具编排能力弱 |
| 多步推理 | 数学题、逻辑题、规划题 | 拆解复杂问题 | 不一定能连接真实业务工具 |
| Tool Use 轨迹 | 用户问题 + 多次工具调用 + 工具结果 + 回答 | 选择工具、构造参数、融合结果、继续决策 | 数据稀缺,标注成本高 |
对于导购助手来说,真实请求通常不是单点问题,而是多目标混合问题:
“周杰伦上海站内场 1 排,想拍 4K 视频发抖音,但怕手机过热,租个能长时间录 4K 还不烫的相机,最好带云台。”
这个请求里至少包含四层信息:
- “内场 1 排”对应拍摄距离和画面需求;
- “4K 视频发抖音”对应视频规格、竖屏、稳定性;
- “怕手机过热”对应设备散热和长时间录制能力;
- “最好带云台”对应商品配件或服务能力。
一个合格的 Tool Use Agent 不能直接拍脑袋推荐商品,它应该先查知识,再查商品库,再判断是否需要服务承接。
flowchart LR
U[用户复杂需求] --> K1[知识检索:场景和术语理解]
K1 --> K2[知识检索:设备选型依据]
K2 --> P[商品库检索:筛选可租商品]
P --> S{是否需要服务承接}
S -->|需要| C[触发服务/配件确认]
S -->|不需要| A[生成导购回答]
C --> A
2. 租赁导购助手需要哪些工具
租赁场景和 Deep Research 类任务不同。Deep Research 更偏向查资料、核事实、写分析;租赁导购助手同时要完成“知识咨询”和“商品决策”。
可以把工具分成三组:
| 工具类型 | 作用 | 典型问题 |
|---|---|---|
知识检索工具 knowledge_search | 查询租赁规则、商品种草内容、全网资讯、教程指南 | “租期怎么算?”“Pico Neo3 有操作指南吗?” |
商品库检索工具 search_db | 按品牌、型号、价格、租期、成色、服务保障等筛选商品 | “租个日租 50 元以内的 iPhone 17 Pro” |
服务承接工具 rental_service | 处理履约、审核、订单、售后、纠纷等问题 | “商家为什么找我要身份证?” |
整体架构可以抽象成一个 One-Model 模式:单一基座模型负责理解上下文、规划任务、选择工具、生成参数和组织回答,外部工具只提供能力接口。
flowchart TB
User[用户多轮对话] --> Model[单一 LLM Agent]
Model -->|查询规则/教程/种草内容| Knowledge[knowledge_search]
Model -->|筛选租赁商品| ProductDB[search_db]
Model -->|订单/审核/售后承接| Service[rental_service]
Knowledge --> Obs[工具返回结果]
ProductDB --> Obs
Service --> Obs
Obs --> Model
Model --> Answer[自然语言回答 + 商品卡片/服务卡片]
工具集合的设计决定了模型能完成哪些业务动作。工具定义要包含名称、用途、参数结构、返回格式和触发边界,否则模型即使学会了“要调用工具”,也会在参数上频繁出错。
3. 推理阶段:ReAct 式多步工具调用
Tool Use Agent 推理时常采用 ReAct(Reasoning and Acting)范式,也就是“边判断、边行动、边观察”。每一轮模型都要决定:继续调用工具,还是已经可以回答用户。
推理流程图展示了这个循环关系:
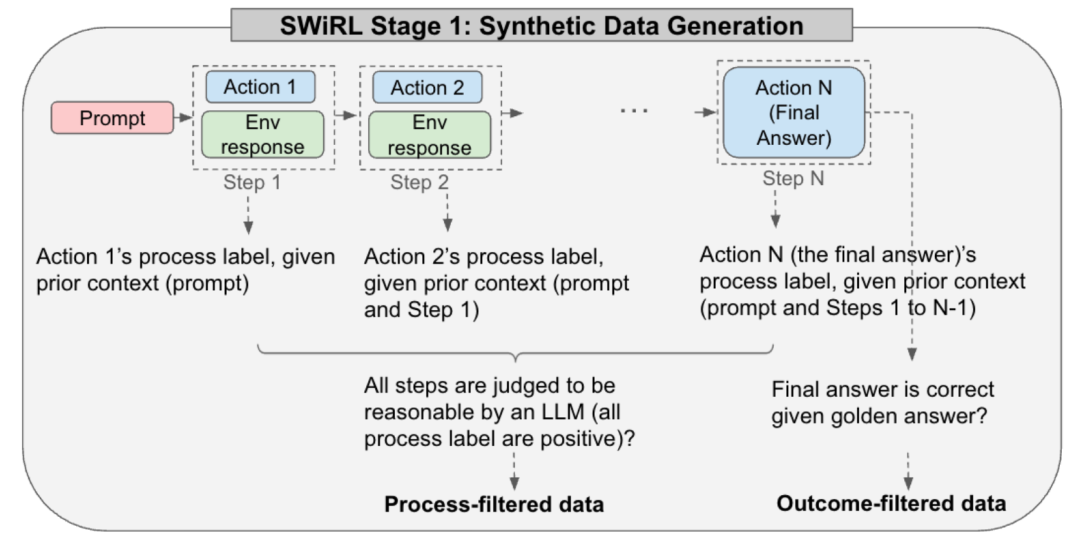
这个流程的关键不是“调用工具”本身,而是每一步都要完成四件事:
- 任务拆解:把用户请求拆成可执行的小任务,例如“查规则”“查商品”“比较参数”。
- 工具选择:判断每个小任务适合哪个工具。
- 参数生成:把自然语言需求转成结构化参数,例如品牌、型号、价格区间、租期。
- 结果融合:读取工具返回内容,判断是否需要继续调用工具,或者生成最终回答。
一个简化的轨迹可以写成这样:
[
{
"role": "user",
"content": "想租个适合拍演唱会 4K 视频的相机,最好别太重"
},
{
"role": "assistant_function_call",
"name": "knowledge_search",
"arguments": {
"query": "演唱会 4K 视频拍摄 相机 轻便 防抖 选型",
"source": ["种草知识", "全网资讯"]
}
},
{
"role": "observation",
"content": "演唱会拍摄更关注防抖、长焦、弱光、连续录制和散热..."
},
{
"role": "assistant_function_call",
"name": "search_db",
"arguments": {
"category": "相机",
"features": ["4K", "防抖", "轻便"],
"max_weight": "500g"
}
},
{
"role": "observation",
"content": "返回若干可租相机商品..."
},
{
"role": "assistant",
"content": "更适合优先看轻便云台相机或运动相机,并给出商品卡片..."
}
]
4. 训练阶段:把完整轨迹拆成多步样本
完整工具调用轨迹很长,如果直接把整条轨迹作为一个样本训练,模型只能学到“输入整段历史后输出最终答案”。但 Tool Use 的核心能力是在中间状态做正确决策,所以训练数据需要拆成多个步骤。
训练流程图展示了 Multi-Step SFT + RL 的思路:

这里有两个训练目标:
| 训练目标 | 输入 | 输出 | 学到的能力 |
|---|---|---|---|
| 下一步预测 | 当前对话历史 + 已有工具结果 | 下一次工具调用或最终回答 | 中途决策能力 |
| 最终回答生成 | 完整工具链 + 所有工具结果 | 面向用户的自然语言回复 | 结果融合与表达能力 |
SFT(监督微调,Supervised Fine-Tuning)阶段使用高质量轨迹让模型模仿正确行为;RL(强化学习,Reinforcement Learning)阶段再根据工具选择、参数正确性、回答质量等信号优化模型。
为了提升训练效率,工具结果通常提前离线生成并写入训练样本。训练时模型不需要真的等待接口返回,只需要学习在给定 observation 的情况下继续做正确决策。
5. 合成数据要满足什么格式
一条 Tool Use 训练数据至少要包含两部分:
{
"query": {
"history": [
{"role": "user", "content": "想租个 VR 设备看演唱会"},
{"role": "assistant", "content": "可以看 Pico 或 Quest 系列..."}
],
"current_user_query": "有这个的操作指南吗?"
},
"answer": {
"trajectory": [
{
"type": "function_call",
"name": "knowledge_search",
"arguments": {
"query": "Pico VR 一体机 操作指南 使用教程",
"source": ["种草知识"]
}
},
{
"type": "observation",
"content": "检索到 Pico VR 设置、安全区域、手柄操作等教程内容..."
}
],
"final_response": "Pico VR 一体机使用时需要先完成开机设置、安全区划定、手柄配对..."
}
}
query 不能只放当前问题,还要保留历史对话,因为多轮导购里有大量省略和指代:
| 用户追问 | 真实完整含义 | 是否依赖历史 |
|---|---|---|
| “17 和 Pro 区别?” | iPhone 17 和 iPhone 17 Pro 的区别 | 是 |
| “审核要身份证吗?” | 租赁审核是否需要身份证 | 不一定 |
| “为什么商家找我要了?” | 为什么商家找我要身份证 | 是 |
| “这个长焦怎么样?” | 上文提到商品的长焦效果怎么样 | 是 |
如果训练数据不包含历史上下文,模型很难学会补全省略信息,也容易把追问当成独立问题处理。
6. 多轮 Tool Use 数据合成的主要难点
租赁导购的合成数据不能只追求数量,质量问题会直接反噬模型。常见难点有四类:
| 难点 | 具体表现 | 影响 |
|---|---|---|
| 语料稀缺 | 真实多轮工具调用轨迹少,尤其缺少复杂业务场景 | 冷启动困难 |
| 合成低效 | 强模型也会生成无效工具链、错误参数、跑题对话 | 有效样本比例低 |
| 动态适配 | 模型不同阶段需要不同难度的数据 | 数据分布固定会限制训练收益 |
| 场景拟真 | 真实用户表达口语化、省略多、目标会变化 | 模型上线后无法处理真实对话 |
纯模板法容易把对话写得机械,比如每轮都像客服问答;完全自由生成又容易偏离业务主线,比如聊着聊着变成手机评测或泛娱乐闲聊。更适合的方式是:用可控的话题路径约束方向,再用角色扮演生成自然表达。
7. “导演-演员”式多智能体合成框架
多轮对话合成可以借鉴“导演-演员”机制:导演负责控制话题路径和业务目标,演员负责扮演用户和助手,生成自然交互。
框架示意图展示了角色之间的分工:
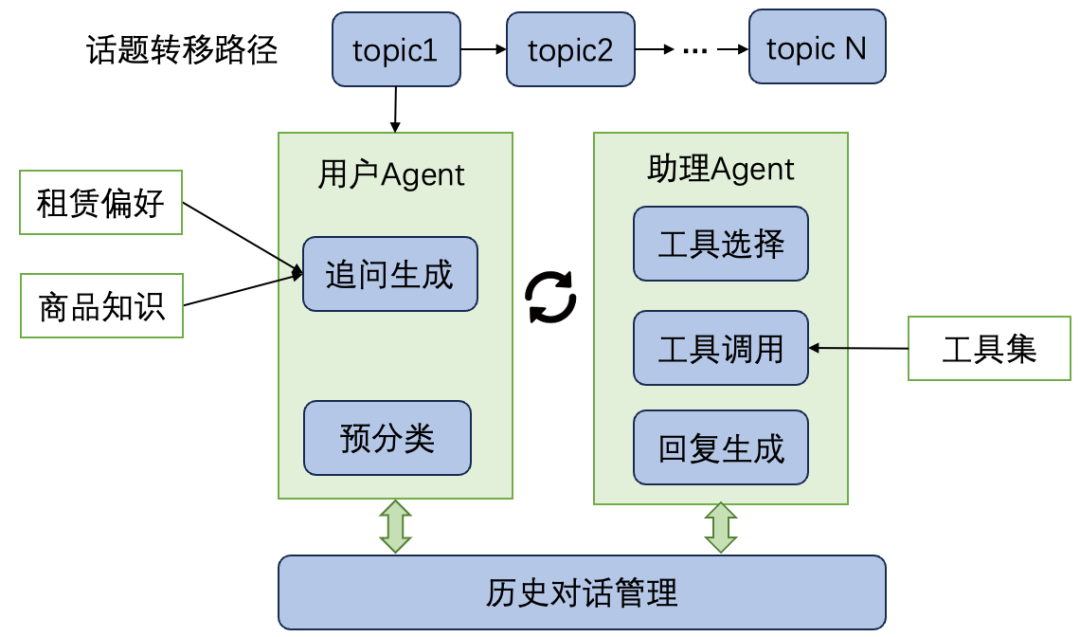
抽象成流程就是:
flowchart TB
Seed[商品/场景种子] --> TopicPool[业务话题池]
Seed --> ProductKnowledge[商品结构化知识]
TopicPool --> Director[导演:采样话题路径]
ProductKnowledge --> Director
Director --> Preference[用户租赁偏好]
Director --> Path[话题转移路径]
Preference --> UserAgent[用户 Agent]
Path --> UserAgent
History[历史对话] --> UserAgent
UserAgent --> UserQuestion[自然用户提问 + 意图结构]
UserQuestion --> AssistantAgent[助手 Agent]
AssistantAgent --> ToolCalls[工具调用链]
ToolCalls --> Observations[工具返回/Mock 数据]
Observations --> AssistantAgent
AssistantAgent --> Reply[助手回复]
Reply --> History
7.1 构建业务话题池
话题池要覆盖租赁生命周期,而不是只围绕“买不买”展开。可以拆成租前、租中、租后三个阶段。
| 阶段 | 话题节点 | 示例 |
|---|---|---|
| 租前 | 使用场景描述 | “去演唱会想拍清楚舞台” |
| 租前 | 商品选择要求 | “预算一天 50 元以内,最好全新” |
| 租前 | 商品信息咨询 | “这个防抖怎么样?” |
| 租前 | 商品对比 | “iPhone 17 和 17 Pro 区别?” |
| 租前 | 租赁规则咨询 | “租期怎么算?” |
| 租中 | 物流进度 | “什么时候能发货?” |
| 租中 | 操作教程 | “Pico Neo3 怎么设置安全区?” |
| 租中 | 异常处理 | “设备开不了机怎么办?” |
| 租后 | 续租买断 | “能不能续租一个月?” |
| 租后 | 售后纠纷 | “商家扣了押金怎么处理?” |
话题池的作用是限制生成方向,让对话覆盖业务链路,而不是完全随机闲聊。
7.2 引入商品结构化知识
只给模型一个商品名,很容易生成空泛问题。商品结构化知识可以让用户问题更贴近真实选购过程。
{
"product_name": "大疆 Pocket 3",
"attribute": {
"简介": "便携式云台相机,支持 4K 视频拍摄和多种参数调节",
"特点": ["云台稳定", "4K 竖屏拍摄", "自动旋转运镜", "色彩参数可调"],
"竞品": [
{"品牌": "影石", "型号": ["GO 3S", "Ace Pro 2"]},
{"品牌": "大疆", "型号": ["Mini 2"]}
],
"适用场景": ["旅行记录", "vlog 创作", "探店拍摄", "口播视频"],
"适用人群": ["内容创作者", "旅行用户", "视频新手"]
}
}
有了这些字段,合成出来的问题会更自然:
| 无商品知识时 | 有商品知识时 |
|---|---|
| “这个相机怎么样?” | “Pocket 3 拍竖屏 vlog 稳不稳,适合新手吗?” |
| “有什么推荐?” | “想租个能自动跟拍、适合探店口播的相机,有没有 Pocket 3 这类的?” |
| “哪个好?” | “Pocket 3 和 Ace Pro 2 哪个更适合演唱会手持拍?” |
7.3 采样话题转移路径
导演模块会根据场景和商品信息生成用户偏好,并采样一条话题路径。路径可以加入业务约束,例如“必须出现两次商品选择要求”,用于增强商品检索类样本比例。
{
"scene": "iPhone 新品尝鲜",
"category": "手机",
"product_name": "iPhone 17 Pro",
"user_preference": {
"price": "日租金 50 元以内",
"lease_period": "7 到 10 天",
"condition": "全新",
"features": ["长焦", "防抖", "高刷屏"]
},
"topic_path": [
"使用场景描述",
"商品选择要求",
"商品信息咨询",
"商品选择要求",
"租赁规则咨询",
"审核信息搜集"
]
}
这种路径有两个好处:
- 可控:可以按训练目标控制某类能力的样本比例。
- 灵活:用户 Agent 仍然可以生成口语化问题,不会变成模板填空。
7.4 用户 Agent 生成自然提问和结构化意图
用户 Agent 的输入包括用户偏好、历史对话、当前话题节点。输出不只是自然语言问题,还要包含结构化标注,便于后续校验和训练。
{
"role": "user",
"content": "17 和 Pro 区别大吗?主要想拍演唱会",
"resolved_query": "iPhone 17 和 iPhone 17 Pro 在演唱会拍摄场景下区别大吗?",
"dependency": "依赖上一轮提到的 iPhone 17 系列",
"intent_category": "商品属性对比",
"mentioned_products": ["iPhone 17", "iPhone 17 Pro"],
"suggested_tools": ["knowledge_search", "search_db"]
}
resolved_query 非常有用,它把省略问题还原成完整问题,可以用于评估模型是否理解上下文。
7.5 助手 Agent 生成工具调用和回答
助手 Agent 根据用户问题、历史对话和推荐工具生成完整回复。工具策略可以按业务规则约束:
- 需要查规则、教程、资讯时,调用
knowledge_search。 - 需要推荐具体商品时,调用
search_db。 - 需要处理审核、订单、售后时,调用
rental_service。 - 没有信息量的问候语不调用工具,直接引导用户描述需求。
商品库检索在合成阶段可以使用 Mock 数据,而不是每次访问真实数据库。这样做有两个实际收益:
| 做法 | 收益 |
|---|---|
| Mock 商品结果 | 避免真实接口调用成本,加快合成速度 |
| 可控注入负样本 | 构造“不匹配商品”“价格超预算”“缺失字段”等情况,让模型学会拒绝或修正 |
例如,用户要求“日租 50 元以内、全新、租 7 天”,Mock 商品里可以故意放入一条日租 80 元的商品,用于训练模型识别并剔除不符合条件的结果。
8. 复杂问题合成:让模型学会跨工具编排
普通商品推荐问题通常只需要“知识检索 + 商品检索”。复杂问题则需要隐式推理,用户不会把每个约束都写成标准参数。
复杂问题生成可以用“工具集 + few-shot 示例 + 用户偏好”驱动:
任务:构造租赁场景下的复杂用户问题,并给出对应工具调用链。
要求:
1. 用户需求要隐性且复杂,不要写成标准筛选条件。
2. 解题过程需要多个工具协同。
3. 工具链要说明每一步为什么调用。
可选工具:
- knowledge_search:查询规则、教程、种草内容、全网资讯
- search_db:查询商品库
- rental_service:服务承接
示例:
问题:南京 2177,买了 125 区的票,想出图,有什么推荐?
工具链:
knowledge_search(解码演唱会行话)
-> knowledge_search(分析座位位置)
-> knowledge_search(场馆位置对应拍摄设备推荐)
-> search_db(按推理结果检索相机/长焦设备)
合成样本可以长这样:
| 复杂问题 | 工具调用链 |
|---|---|
| “周杰伦上海站内场 1 排,想拍 4K 视频发抖音,但怕手机过热,租个能长时间录 4K 还不烫的相机,最好带云台。” | knowledge_search(内场拍摄需求) → knowledge_search(4K 长录制散热能力) → search_db(4K/散热/云台/相机) → rental_service(配件确认) |
| “新手学拍 vlog,想租个带美颜、能竖屏、重量小于 500g 的相机,还要有教程,租一周。” | knowledge_search(vlog 新手选型) → search_db(美颜/竖屏/轻量/7天) → knowledge_search(教程内容) |
| “去环球影城玩两天,想拍夜景和过山车第一视角,设备别太贵,最好不用押金。” | knowledge_search(夜景/运动拍摄设备) → search_db(运动相机/夜景/预算/免押) → knowledge_search(平台免押规则) |
复杂问题合成的价值在于训练模型“先理解,再检索”,而不是只做关键词匹配。
9. 数据过滤:用任务类型约束工具链
合成数据一定会有噪声。过滤阶段要检查工具选择、参数、回答格式和业务一致性。一个实用做法是预定义“任务类型 → 工具调用规则”。
| 任务类型 | 触发条件 | 工具链规则 |
|---|---|---|
| 商品推荐 | 用户表达品牌、型号、品类、场景、参数、价格要求 | 强制 knowledge_search(选型/种草) → 强制 search_db |
| 商品属性对比 | 用户比较两个或多个商品 | knowledge_search(参数/体验),必要时 search_db |
| 租赁内部问题 | 租期、免押、资格、费用、订单、平台规则 | 强制 knowledge_search(内部知识),必要时全网检索 |
| 服务履约 | 审核、发货、售后、纠纷、商家沟通 | 条件触发 rental_service |
| 通用实时问答 | 天气、新闻、实时信息 | knowledge_search(全网搜) |
| 无意义问题 | “你好”“在吗”“嗯” | 禁止调用工具,礼貌引导 |
过滤可以拆成四层:
flowchart LR
Raw[合成原始样本] --> Rule[规则校验]
Rule --> Tool[工具链校验]
Tool --> Param[参数校验]
Param --> Format[回答格式校验]
Format --> Human[人工抽检/订正]
Human --> Clean[高质量训练数据]
校验项越具体,越容易发现坏样本:
| 校验项 | 错误示例 |
|---|---|
| 工具选择 | 用户问租期规则,却调用商品库 |
| 参数抽取 | 用户要求日租 50 元以内,参数写成 500 元 |
| 历史理解 | “这个”没有解析到上一轮商品 |
| 工具结果使用 | 工具返回没有该商品,回答却强行推荐 |
| 格式规范 | 需要商品卡片却只输出纯文本 |
| 业务合规 | 审核问题没有引导到正确服务流程 |
10. 线上数据回流:让数据合成持续对准真实问题
只靠离线合成无法覆盖所有线上表达。更稳妥的做法是把线上 badcase 回流到数据系统,形成持续改进闭环。
整体节奏可以用图表示:
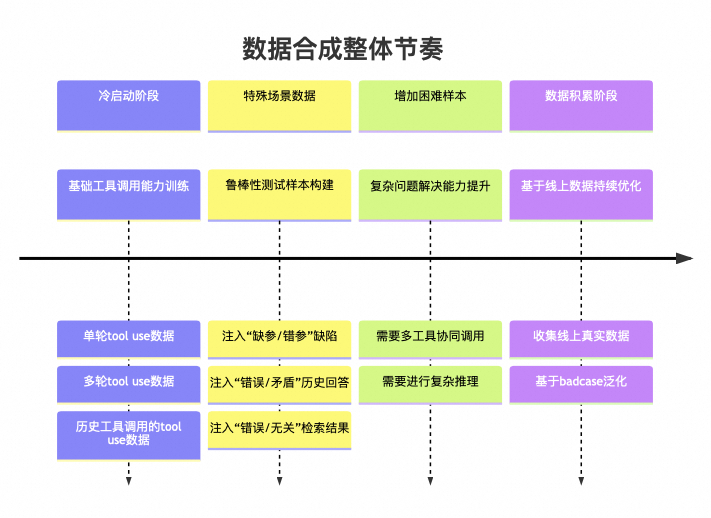
这个闭环包含五个动作:
flowchart LR
Deploy[模型上线] --> Log[采集线上对话]
Log --> Label[标注预测结果]
Label --> Error[统计错误类型]
Error --> Synthesis[针对 badcase 合成数据]
Synthesis --> Train[重新训练/微调]
Train --> Eval[离线评测]
Eval --> Deploy
常见 badcase 可以转成定向合成任务:
| 线上错误 | 定向合成策略 |
|---|---|
| 模型忘记历史商品 | 增加多轮指代、省略、追问样本 |
| 商品参数填错 | 增加价格、租期、成色、服务保障抽取样本 |
| 不该调用工具却调用 | 增加问候、闲聊、无意义问题负样本 |
| 服务问题误走商品推荐 | 增加审核、售后、纠纷类服务承接样本 |
| 回答重复 | 增加长上下文下的最终回答压缩样本 |
数据飞轮的核心不是“合成更多”,而是让合成分布跟随模型缺陷变化。
11. 训练数据规模对效果的影响
实验配置可以概括为:
| 项目 | 配置 |
|---|---|
| 基座模型 | Qwen3-Next-80B-A3B-Instruct |
| 训练方式 | SFT + RL 多阶段训练 |
| 高质量训练数据 | 约 1500 条,经过筛选和订正 |
| 评测口径 | 工具选择正确、工具参数正确、回答格式正确 |
训练数据量实验结果展示了一个清晰趋势:
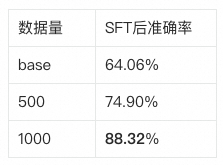
随着高质量训练数据增加,SFT 后准确率从约 64% 提升到约 88%。这里的重点不是“数据越多越好”,而是“高质量轨迹越多,模型越能稳定学会中间决策”。如果样本里工具链错误、参数错误或回答脱离工具结果,更多数据反而会把错误模式教给模型。
12. 合成方法消融:路径控制和多 Agent 都有用
对比几种数据来源和生成方式:
| 方法 | 生成方式 | 主要问题 |
|---|---|---|
| 无话题路径采样 | 以商品或场景为种子,让用户 Agent 随机对话 | 容易跑题,关键业务节点覆盖不足 |
| 无多 Agent 生成 | 一次性生成多轮问题和答案 | 对话动态性差,追问和指代不自然 |
| 线上数据采样 | 直接使用线上对话 | 噪声多,工具轨迹不完整,覆盖不可控 |
| 路径采样 + 多 Agent | 导演控制路径,用户和助手动态交互 | 覆盖可控,表达更贴近真实用户 |
消融实验结果如下:
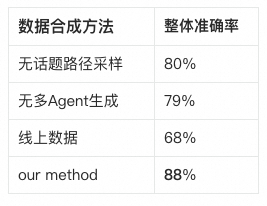
带有话题路径采样和多 Agent 互动的数据,更能帮助模型学习工具调用。原因很直接:路径采样保证了业务覆盖,多 Agent 生成保证了对话自然性,两者缺一项都会影响训练信号。
13. 多轮理解会迁移到工具调用
一个有意思的现象是:训练前期只加入高质量多轮问答数据,即使不包含大量工具调用,也能带动工具调用能力上升。
实验结果展示了这种互相促进关系:

这说明多轮理解和 Tool Use 不是完全独立的能力。模型要正确调用工具,先要理解:
- 用户当前问题是否依赖历史;
- 省略词和指代词对应哪个商品;
- 用户需求是否发生转移;
- 历史中哪些约束仍然有效;
- 哪些信息已经回答过,不能重复生成。
多轮问答数据提升了上下文建模能力,工具调用数据再把这种能力落到外部工具编排上。
14. 落地时容易踩的坑
14.1 工具定义过宽,模型会乱调用
如果 knowledge_search 同时承担规则、教程、商品信息、全网资讯,又没有 source 参数约束,模型会把所有问题都扔给它。工具定义应尽量明确:
{
"name": "knowledge_search",
"description": "查询租赁规则、商品教程、种草内容和全网资讯",
"arguments": {
"query": "检索词",
"source": {
"type": "array",
"items": ["内部规则", "种草知识", "全网资讯"]
}
}
}
14.2 只合成正样本,模型不会拒绝错误结果
商品库返回结果可能不符合用户条件。训练数据要包含这种情况:
{
"user_requirement": {
"max_daily_rate": 50,
"condition": "全新"
},
"search_result": [
{"name": "相机 A", "daily_rate": 45, "condition": "全新"},
{"name": "相机 B", "daily_rate": 80, "condition": "全新"},
{"name": "相机 C", "daily_rate": 35, "condition": "9成新"}
],
"expected_behavior": "只推荐相机 A,并说明 B 超预算、C 不符合成色要求"
}
14.3 多轮历史太干净,线上会不适应
真实用户不会每轮都说完整句。合成时要主动加入口语、省略、错别字、临时改需求:
| 干净表达 | 更贴近真实用户 |
|---|---|
| “请推荐一款适合演唱会拍摄的相机” | “看演唱会想拍清楚点,租啥?” |
| “iPhone 17 Pro 的长焦拍摄效果如何?” | “它长焦咋样?” |
| “请查询租赁审核是否需要身份证” | “审核要身份证吗?” |
| “我想把租期改成 7 天” | “那租一周呢” |
14.4 只评最终回答,会漏掉工具错误
最终回答看起来正确,不代表工具调用正确。评测要拆开:
| 评测维度 | 判断方式 |
|---|---|
| 工具选择 | 是否调用了该调用的工具,是否避免了不该调用的工具 |
| 参数正确性 | 品牌、型号、价格、租期、场景是否抽取正确 |
| 工具顺序 | 是否先查知识再查商品,是否在必要时触发服务 |
| 结果融合 | 回答是否引用并遵守工具返回结果 |
| 格式规范 | 商品卡片、服务卡片、自然语言结构是否符合要求 |
15. 后续优化方向
两个方向最值得投入:
15.1 用 LLM-as-Judge 提升过滤效率
LLM-as-Judge 指用更强的大模型充当评审器,对合成样本进行质量判断。它可以检查:
- 工具链是否符合任务;
- 参数是否覆盖用户约束;
- 回答是否忠实于 observation;
- 多轮指代是否解析正确;
- 是否存在业务风险或格式错误。
人工仍然适合做抽检和高风险样本订正,但大规模初筛可以交给评审模型完成。
15.2 用知识图谱生成更复杂的 Query
租赁导购天然适合建知识图谱:
graph LR
UserGroup[人群] --> Preference[偏好]
Preference --> Feature[商品特征]
Scene[使用场景] --> Feature
Feature --> Category[品类]
Category --> Product[商品]
Product --> Rule[租赁规则]
Product --> Service[服务保障]
有了图谱,可以从“人群—场景—特征—商品—规则”路径上采样复杂问题。例如:
“第一次去音乐节,白天拍人、晚上拍舞台,设备别太重,还想知道下雨弄湿了怎么算。”
这类问题天然需要跨越场景理解、设备选型、商品检索和租赁规则查询,比单纯模板更适合训练高阶 Tool Use 能力。
参考资料
[1] Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use, https://arxiv.org/abs/2504.04736
[2] WebSailor: Navigating Super-human Reasoning for Web Agent, https://arxiv.org/abs/2507.02592
[3] ACEBench: Who Wins the Match Point in Tool Usage?, https://arxiv.org/abs/2501.12851
[4] Tongyi DeepResearch Technical Report, https://arxiv.org/abs/2510.24701
[5] τ2-Bench: Evaluating Conversational Agents in a Dual-Control Environment, https://arxiv.org/abs/2506.07982