大语言模型(Large Language Model,LLM)训练并不是把知识一条条写进数据库,也不是让模型真正“理解”每一句话。更准确地说,它是在海量文本上不断调整一组巨大的参数,让模型在给定上下文时,更倾向于生成合理的下一个 token。
所谓“玄学”,不是说没有数学原理,而是工程上很难完全看清内部发生了什么。一个千亿参数模型在高维空间里更新权重,人类通常只能盯着 Loss、验证集指标、梯度范数、吞吐量等少数监控信号判断训练是否正常。
LLM 的训练可以拆成三个主要阶段:
flowchart LR
A[海量无标注文本] --> B[预训练 Pre-training]
B --> C[基础模型 Base Model]
C --> D[监督微调 SFT]
D --> E[指令模型 Instruction Model]
E --> F[RLHF / 偏好优化]
F --> G[对话模型 Chat Model]
这三个阶段解决的问题不同,训练目标也不同。
| 阶段 | 数据来源 | 训练目标 | 主要产物 |
|---|---|---|---|
| 预训练 | 网页、书籍、代码、论文、多语言文本等 | 预测下一个 token | 具备语言、常识、代码、推理雏形的基础模型 |
| 监督微调(SFT) | 指令问答、任务样例、领域数据 | 学会按指令回答 | 更像助手、更会按格式完成任务的模型 |
| RLHF(人类反馈强化学习) | 人类偏好排序、反馈数据 | 生成更符合人类偏好的回答 | 更安全、更礼貌、更像聊天产品的模型 |
数据量一般是递减的:预训练需要万亿级 token,监督微调可能是百万级样本,RLHF 的人工偏好数据规模更小,但标注成本更高、信号更精细。
1. 预训练、微调、RLHF 分别在教模型什么
1.1 预训练:让模型学会“语言世界的统计规律”
预训练的任务看起来非常朴素:给模型一段文本,让它预测下一个 token。
例如:
输入:法国的首都是
目标:巴黎
模型不会直接输出一个确定答案,而是输出整个词表上的概率分布:
巴黎: 0.72
伦敦: 0.05
法国: 0.03
城市: 0.02
...
如果正确 token 的概率越高,Loss 越低;如果正确 token 的概率很低,Loss 就高。模型通过不断降低 Loss,逐渐学到语言结构、事实关联、语法模式、代码语义和部分推理能力。
预训练学到的不是“回答问题的礼貌格式”,而是更底层的能力:什么词经常一起出现,什么概念之间有关联,代码块应该如何闭合,数学表达式通常怎么展开。
1.2 监督微调:让模型学会“按指令做事”
预训练出来的基础模型擅长续写,但不一定会像助手一样回答问题。监督微调(Supervised Fine-Tuning,SFT)会使用成对的指令和答案训练模型。
例如:
{
"instruction": "用一句话解释什么是梯度下降",
"answer": "梯度下降是一种通过沿着 Loss 下降最快的方向更新参数,从而逐步降低错误的优化方法。"
}
SFT 仍然常用交叉熵 Loss,但数据变成了任务样例。它教模型学会问答、摘要、翻译、代码生成、结构化输出等能力,也让模型更习惯“用户提问—助手回答”的形式。
1.3 RLHF:让模型学会“什么回答更符合人类偏好”
RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)处理的是另一个问题:两个回答都可能语法正确,但人类更喜欢哪一个?
典型流程如下:
sequenceDiagram
participant P as Prompt
participant M as 当前模型
participant H as 人类标注
participant R as 奖励模型
participant O as 优化算法
P->>M: 输入问题
M-->>P: 生成多个候选回答
H->>R: 标注回答偏好排序
R-->>O: 学到奖励信号
O->>M: 更新模型,使高奖励回答概率上升
这里的目标已经不只是“下一个 token 是否正确”,而是“整个回答是否让人满意”。奖励模型会把人类偏好压缩成一个分数,PPO(Proximal Policy Optimization,近端策略优化)或其他偏好优化方法再根据这个分数更新模型。
这也带来一个重要后果:RLHF 优化的是偏好,不等于直接优化事实正确性。一个回答可能语气自然、结构清楚、看起来可信,但事实仍然是错的。幻觉问题很大程度上来自这里:模型是在生成高概率、高奖励的文本,而不是从数据库里取出经过验证的事实。
2. 梯度下降:模型到底怎么“学会”
深度学习训练的核心循环可以压缩成四步:
flowchart TD
A[取一批训练数据 Batch] --> B[前向传播:模型给出预测]
B --> C[计算 Loss:预测和答案差多少]
C --> D[反向传播:计算每个参数该怎么改]
D --> E[优化器更新参数]
E --> A
用公式表示就是:
θ_new = θ_old - η × ∇L
符号含义:
| 符号 | 含义 |
|---|---|
| θ | 模型参数,可以理解为神经网络里的大量权重数字 |
| L | Loss,衡量当前预测错了多少 |
| ∇L | 梯度,表示参数朝哪个方向改能让 Loss 下降 |
| η | 学习率,控制每次更新的步长 |
一个极简训练循环大致长这样:
for batch in dataloader:
x, y = batch
logits = model(x) # 前向传播
loss = cross_entropy(logits, y) # 计算 Loss
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度,准备下一步
真实的 LLM 训练会复杂得多:分布式并行、混合精度、梯度累积、检查点保存、数据调度、通信优化都要一起处理。但核心逻辑仍然是:预测、算错、回传、改参数。
3. 学习率:一步迈多大决定训练稳不稳
学习率是最关键的超参数之一。它控制参数每次更新的幅度。
| 学习率状态 | 表现 | 常见后果 |
|---|---|---|
| 太大 | Loss 大幅震荡,甚至突然飙升 | 参数跨过最优区域,训练发散 |
| 太小 | Loss 下降很慢 | 训练成本高,可能长时间没有明显进展 |
| 合适 | Loss 整体下降,局部有小幅波动 | 模型稳定收敛 |
实际训练中不会从头到尾使用一个固定学习率,而是会设计学习率调度策略:
| 策略 | 作用 |
|---|---|
| Warmup(预热) | 训练初期从较小学习率开始,逐步升高,避免模型刚开始就被大梯度冲坏 |
| Decay(衰减) | 训练后期逐渐降低学习率,让参数更新更细致 |
| Cosine Annealing(余弦退火) | 学习率按余弦曲线变化,常用于平滑地从高学习率过渡到低学习率 |
训练像在高维地形里找低谷。学习率太大,容易在谷底附近来回跳;学习率太小,又可能走得过慢。
4. 反向传播:误差怎样传回每一层
神经网络前向传播时,输入从底层进入,一层层变换,最后输出预测结果。反向传播(Backpropagation)则反过来,从输出层开始,把误差信号传回前面的每一层。
它依赖链式法则。简化表达如下:
∂L/∂θ₁ = ∂L/∂h₃ × ∂h₃/∂h₂ × ∂h₂/∂θ₁
含义是:如果某个早期参数 θ₁ 影响了中间状态 h₂,h₂ 又影响 h₃,h₃ 再影响最终 Loss,那么 θ₁ 对 Loss 的影响可以通过一层层偏导数相乘算出来。
这也是 LLM 训练需要大量 GPU(Graphics Processing Unit,图形处理器)的原因。模型里可能有数百亿甚至千亿级参数,每个参数都要参与前向计算和梯度计算,单机很难承受这样的计算量和显存需求。
5. 知识不是存在某个参数里,而是分布在权重组合中
LLM 不像关系型数据库那样保存事实:
key = "法国首都"
value = "巴黎"
更接近的理解是:大量训练样本反复推动模型调整权重,使得“法国的首都是”这个上下文经过网络计算后,更容易激活“巴黎”对应的输出方向。
流程可以这样看:
flowchart LR
A[输入文本] --> B[Tokenizer 切成 token]
B --> C[Embedding 映射为向量]
C --> D[Transformer 多层计算]
D --> E[Hidden State 语义表示]
E --> F[投影到词表]
F --> G[输出 token 概率分布]
token 是离散的,隐藏状态是高维向量。以一些大模型配置为例,词表可能有十几万个 token,隐藏维度可能有几千到上万维。词表负责入口和出口,高维隐藏空间负责中间的语义计算。
| 部分 | 特点 | 作用 |
|---|---|---|
| Token | 离散编号,数量有限 | 把文本变成模型能处理的符号 |
| Embedding | 向量表示 | 把离散 token 映射到连续空间 |
| Hidden State | 高维连续表示 | 承载上下文语义和中间计算 |
| Logits | 每个 token 的分数 | 决定下一个 token 的概率 |
所以,模型会“背书”的本质不是把句子原封不动存起来,而是训练数据改变了权重分布,使某些上下文更倾向于走向某些输出。
这也解释了幻觉:模型不是查事实表,而是在当前上下文下生成最可能的文本。如果训练数据里错误信息足够多,或者上下文诱导了错误模式,模型也可能生成看起来很自然的错误答案。
6. Loss 曲线:训练过程最常看的仪表盘
训练 LLM 时,人类不可能逐个检查千亿参数的变化。工程上最常看的信号之一,就是 Loss 随训练步数变化的曲线。
典型 Loss 曲线通常会经历几个阶段:
- 初始阶段:Loss 很高,模型接近随机猜测。
- 快速下降:模型学到高频模式、基本语法和常见结构。
- 缓慢下降:模型开始吸收更细的知识和更复杂的模式。
- 收敛平台:继续训练的收益变小,Loss 下降趋缓。
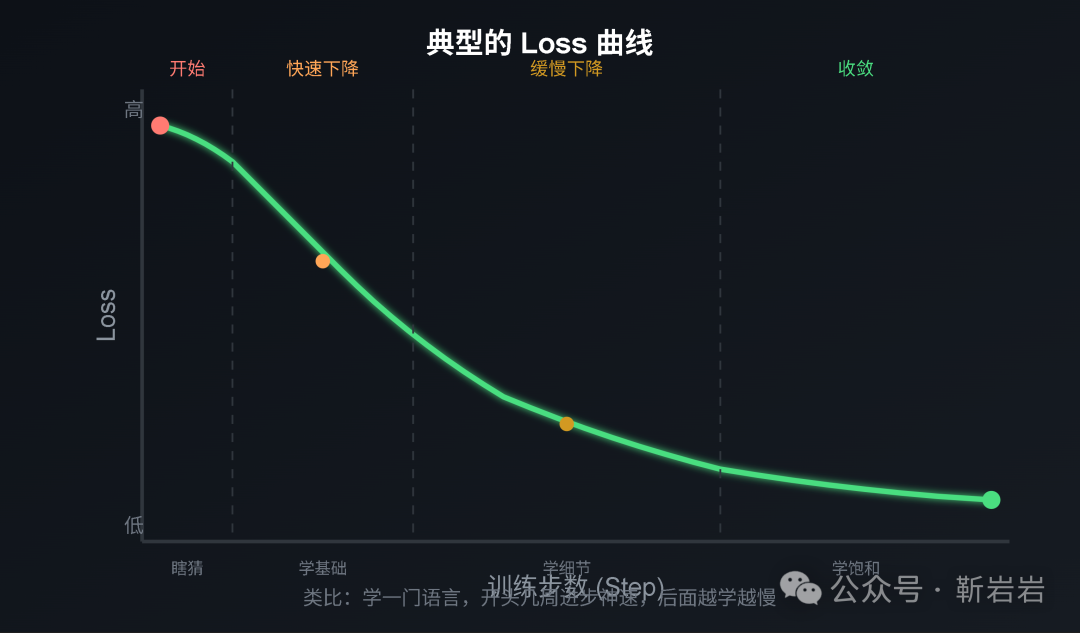
这条曲线的重点不是每一个点,而是整体趋势。训练数据按 batch 分批进入模型,每个 batch 的难度不同,Loss 出现抖动很正常。更可靠的看法是观察滑动平均、验证集 Loss 和周期性评测结果。
几个基础概念需要分清:
| 概念 | 含义 |
|---|---|
| Batch | 一次送入模型的一批样本 |
| Batch Size | 每个 batch 包含多少样本或 token |
| Step | 完成一次参数更新 |
| Epoch | 整个训练集被完整遍历一遍 |
如果有 100 万条样本,Batch Size 是 1000,那么 1 个 Epoch 包含 1000 个 Step。LLM 预训练更常按 token 数和 step 统计,因为数据规模太大,完整 epoch 的概念不一定像小数据集训练那样直观。
7. Loss 曲线的常见异常
Loss 曲线不是越平滑越好,也不是短时间上升就一定有问题。关键是把训练 Loss、验证 Loss、学习率、梯度范数放在一起看。
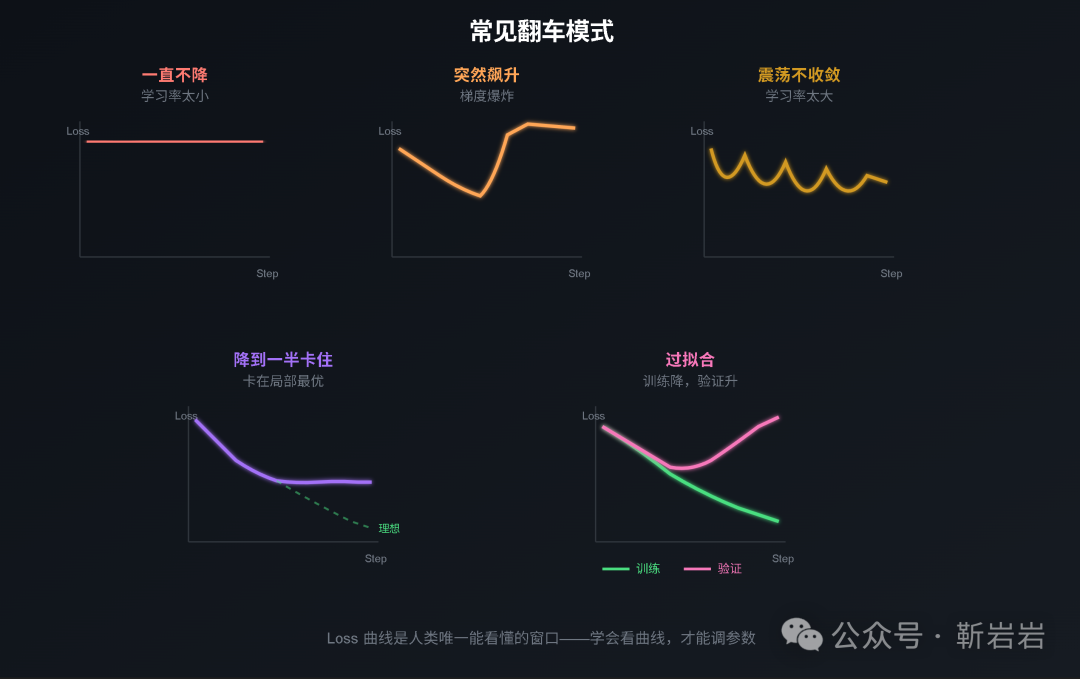
常见模式可以归纳成下面几类:
| 曲线表现 | 可能原因 | 处理方向 |
|---|---|---|
| 训练 Loss 长时间不降 | 学习率太小、数据管道错误、标签错位、模型结构有 bug | 检查数据和标签,做小批量过拟合测试,调整学习率 |
| Loss 突然飙升后无法恢复 | 学习率过大、梯度爆炸、数值溢出 | 降低学习率,启用梯度裁剪,检查混合精度配置 |
| Loss 大幅震荡 | 学习率偏大、batch 太小、数据分布波动大 | 增大有效 batch,调低学习率,平滑数据采样 |
| 训练 Loss 降,验证 Loss 升 | 过拟合、数据重复、训练集泄漏 | 增强数据清洗,增加正则化,提前停止 |
| 训练和验证 Loss 都很高 | 欠拟合、模型太小、训练不足、数据质量差 | 延长训练,增大模型或改进数据 |
过拟合和欠拟合尤其常见:
| 状态 | 训练集表现 | 验证集表现 | 含义 |
|---|---|---|---|
| 过拟合 | Loss 很低 | Loss 变高或不降 | 模型记住训练样本,但泛化差 |
| 欠拟合 | Loss 也降不下去 | Loss 同样很高 | 模型能力不足或训练没有学起来 |
| 正常学习 | Loss 稳定下降 | Loss 也同步下降 | 模型学到可泛化规律 |
只看训练 Loss 很危险,因为模型可能只是在“背题”。验证集和独立评测才更能反映真实能力。
8. 三个阶段的 Loss 到底差在哪
三个训练阶段都可能用梯度下降,但“什么算对”完全不同。
8.1 预训练 Loss:预测下一个 token
预训练常用交叉熵(Cross-Entropy)作为 Loss。交叉熵衡量真实分布和模型预测分布之间的差距。
假设输入是:
今天天气真
正确下一个 token 是:
好
模型给“好”的概率是 0.3,那么 Loss 是:
Loss = -ln(0.3) ≈ 1.20
如果模型给“好”的概率提升到 0.9:
Loss = -ln(0.9) ≈ 0.105
对比很直观:
| 正确 token 概率 | Cross-Entropy Loss | 含义 |
|---|---|---|
| 0.9 | 0.105 | 模型很有把握地预测对了 |
| 0.3 | 1.204 | 模型有些犹豫 |
| 0.01 | 4.605 | 模型几乎没猜到正确答案 |
交叉熵有一个重要特性:正确答案概率越低,惩罚越大。这会推动模型把概率质量更多分配给真实 token。
8.2 SFT Loss:还是预测 token,但数据变成任务答案
监督微调也常用交叉熵,只不过训练数据从普通文本变成了指令和答案。
例如:
用户:法国的首都是哪里?
助手:巴黎。
训练时,通常会让模型在“助手回答”部分计算 Loss,推动它学会在类似问题下生成合适答案。SFT 不只是教事实,也教格式、语气、步骤和任务边界。
但 SFT 数据太窄会有副作用。如果只拿某个小领域数据反复训练,模型可能损失一部分通用能力,这就是灾难性遗忘(Catastrophic Forgetting)的一种表现。
LoRA(Low-Rank Adaptation,低秩适配)等参数高效微调方法之所以流行,一个重要原因是它们冻结大部分原始权重,只训练少量新增参数,从而降低破坏基础能力的风险。
8.3 RLHF Loss:从“预测正确”变成“偏好更高”
RLHF 的优化信号来自奖励模型,而奖励模型来自人类偏好标注。它不再直接问“下一个 token 是不是训练集里的答案”,而是问“这个完整回答在人类排序里是否更好”。
| 阶段 | 优化目标 | “对”的定义 | 风险 |
|---|---|---|---|
| 预训练 | 下一个 token 概率 | 更像训练语料中的语言模式 | 可能学到错误或偏见 |
| SFT | 指令答案匹配 | 更符合任务样例 | 数据太窄会损伤通用能力 |
| RLHF | 奖励分数更高 | 更符合人类偏好 | 可能迎合偏好而不保证真实 |
这就是为什么一个模型可以同时“很会说话”和“会胡说”。RLHF 会让回答更礼貌、更完整、更像助手,但事实校验仍然需要检索、工具调用、外部数据库或更强的训练数据支持。
9. 训练难点:公式简单,工程变量太多
梯度下降公式只有一行,但真正训练一个大模型时,要同时处理超参数、数据配方、分布式系统、数值稳定性和评测体系。
9.1 超参数会互相影响
超参数不是模型自动学出来的,而是训练前或训练中由工程师设定的“学习规则”。
| 超参数 | 控制什么 | 常见影响 |
|---|---|---|
| 学习率 | 每次参数更新幅度 | 太大易发散,太小训练慢 |
| Batch Size | 每次用于估计梯度的数据量 | 大 batch 更稳定,但显存和通信压力更高 |
| Warmup Steps | 学习率预热时长 | 预热不足可能早期不稳定 |
| Weight Decay | 权重衰减强度 | 抑制过拟合,过大可能限制表达能力 |
| Dropout | 随机关停部分神经元 | 小模型常用,大模型预训练中不一定常用 |
| Gradient Clipping | 梯度裁剪阈值 | 防止梯度爆炸 |
| Sequence Length | 输入上下文长度 | 越长越耗显存和算力 |
| Optimizer | 参数更新算法 | AdamW 等优化器常用于 Transformer 训练 |
难点在于这些变量不是独立的。Batch Size 变了,学习率可能也要变;数据配方变了,Loss 曲线形态也会变;上下文长度增加,显存占用和训练吞吐都会变化。
9.2 数据质量经常比模型大小更关键
训练数据不是越多越好。重复、低质、乱码、广告、自动生成垃圾文本、错误代码、污染评测集的数据都会影响模型。
一个典型数据管道可能是这样:
flowchart LR
A[原始数据采集] --> B[格式解析]
B --> C[去重]
C --> D[质量过滤]
D --> E[安全与隐私过滤]
E --> F[按领域配比混合]
F --> G[Tokenizer 编码]
G --> H[进入训练]
数据配方也很重要。通用文本提供常识和语言能力,数学数据提供推理训练,代码数据提供严密结构,多语言数据扩展语言覆盖范围。某一类数据比例过高,模型可能在对应领域变强,但也可能牺牲其他能力。
这也是微调容易“调傻”的原因:如果微调数据单一、重复、风格强烈,模型会被新的梯度牵引到狭窄分布里,原来的通用能力被覆盖。
9.3 分布式训练会放大每一个小问题
大模型训练通常需要很多 GPU 同时工作。模型可能被切分到不同设备上,数据也会被分发到不同节点上。任何一个环节出问题,都会影响整体训练。
常见工程问题包括:
| 问题 | 表现 |
|---|---|
| 通信瓶颈 | GPU 等待同步,算力利用率低 |
| 显存不足 | batch 或序列长度上不去 |
| 数值溢出 | Loss 变成 NaN,训练中断 |
| 节点故障 | 长时间训练被迫恢复检查点 |
| 数据加载慢 | GPU 空转,吞吐下降 |
训练不是单纯的算法问题,也是一套大规模系统工程。
9.4 涌现能力难以精确预测
模型变大、数据变多、训练更充分后,一些能力会突然显得明显增强,例如多步推理、代码生成、数学解题、上下文学习等。这类现象常被称为涌现(Emergence)。
需要谨慎理解“突然出现”。有些能力看起来是跳变,可能是评测指标太粗导致的;模型真实能力也许是渐进增长,只是超过某个阈值后才在测试中表现出来。
可以确定的是:模型规模、数据质量、训练 token 数和评测方式共同决定能力边界,没有一个简单公式能保证“多少参数一定会出现某能力”。
10. 训练看板应该盯哪些指标
只看训练 Loss 不够。一个更可靠的训练看板至少应该包含这些指标:
| 指标 | 作用 |
|---|---|
| Training Loss | 判断模型是否在训练集上学习 |
| Validation Loss | 判断泛化能力和过拟合风险 |
| Perplexity(困惑度) | 语言模型常用指标,可由 Loss 转换得到 |
| Learning Rate | 确认调度策略是否按预期执行 |
| Gradient Norm | 监控梯度爆炸或梯度异常 |
| Throughput | 每秒处理 token 数,衡量训练效率 |
| GPU Utilization | 判断算力是否被充分使用 |
| Evaluation Benchmarks | 观察数学、代码、问答、推理等能力变化 |
| Data Mix Ratio | 确认不同数据源比例是否符合配方 |
训练稳定不代表模型一定好,Loss 下降也不代表真实能力全面提升。最终还需要在独立评测、人工检查和实际任务中验证模型表现。
11. 符号和概念速查
| 符号 / 概念 | 含义 |
|---|---|
| θ | 模型参数 |
| η | 学习率 |
| L | Loss,损失函数 |
| ∇ | 梯度,表示 Loss 增长最快的方向 |
| ∂ | 偏导数,表示某个变量变化对结果的影响 |
| Batch | 一次训练使用的一批数据 |
| Step | 一次参数更新 |
| Epoch | 训练集完整遍历一遍 |
| Cross-Entropy | 衡量真实分布和预测分布差距的 Loss |
| Backpropagation | 反向传播,用链式法则计算梯度 |
| RLHF | 基于人类反馈的强化学习 |
| PPO | 一种常用于 RLHF 的策略优化算法 |
核心公式仍然是:
θ_new = θ_old - η × ∇L
翻成工程语言就是:
新参数 = 旧参数 - 学习率 × 梯度
大语言模型训练的底层逻辑并不神秘:用数据产生预测,用 Loss 衡量错误,用梯度更新参数。真正困难的是参数太多、空间太高、数据太复杂、训练信号太有限。工程师能观察到的只是少数曲线和指标,而模型内部的表示如何形成、能力何时出现、某次训练为什么更好,仍然需要大量实验才能判断。