Vibe Coding 最容易被误解成一句话:只要会描述需求,就能让 AI 自动写出完整软件。
这个说法很诱人,但也很危险。它把 AI 编程描述成一种“许愿机”:输入几句话,等待几分钟,拿到一个可上线的软件系统。真实的软件开发不是这样。一个稍微复杂的功能,就涉及需求边界、数据模型、接口契约、异常处理、并发控制、测试覆盖、部署策略、线上观测和后续维护。任何一个环节含糊,代码都可能在后面爆炸。
AI 确实改变了开发方式,但它没有取消软件工程。它把工程师的工作重心从“逐行写代码”推向了“定义目标、拆解任务、约束实现、验收结果、沉淀流程”。
更准确地说,Vibe Coding 不是让完全不懂开发的人变成工程师,而是让工程师逐渐从执行者变成一个更强的“甲方”:
- 需求要能说清楚;
- 技术方案要能判断;
- 任务要能拆小;
- 代码要能验收;
- 风险要能兜住;
- 可重复的流程要能固化成工具。
AI 可以承担大量脑力和体力劳动,但责任边界不能交给 AI。理解这一点,需要从 LLM(Large Language Model,大语言模型)的本质开始。
LLM 的本质:它在预测下一个 Token
LLM 经常表现得像一个无所不知的专家。它能写代码、解释论文、生成 SQL、分析日志,还能用非常确定的语气回答各种问题。问题在于,语气确定不等于结果正确。
从技术上看,LLM 的核心任务并不是“理解世界”,而是基于已有输入预测下一个 Token。Token 可以粗略理解为词、字、符号或词片段。一次生成过程大致是这样的:
flowchart LR
A[用户输入 Prompt] --> B[切分为 Token 序列]
B --> C[模型根据上下文计算下一个 Token 的概率分布]
C --> D[采样或选择一个 Token]
D --> E[追加到上下文]
E --> C
C -->|满足停止条件| F[输出完整结果]
例如输入:
def quicksort(
模型不会像人类工程师一样先在脑中设计完整算法,再把代码写出来。它会根据训练中学到的模式,计算后续 Token 的概率。它可能预测参数名、冒号、换行、递归逻辑、分区逻辑,因为这些模式在训练数据中经常和 quicksort 一起出现。
这也是为什么同一句问题,加上不同的前置信息,输出会完全不同:
你是一名资深后端工程师,请评审下面这段 Go 代码的并发安全问题。
和:
你是一名产品经理,请从用户体验角度评价下面这个功能设计。
这两段 Prompt 把模型推向了不同的概率空间。前者会让模型更关注锁、竞态、上下文取消、错误处理;后者会让模型更关注流程、转化、提示和操作成本。
所以,Prompt Engineering(提示词工程)和 Context Engineering(上下文工程)的本质不是“咒语技巧”,而是在有限上下文里提供尽可能多的有效信息,让模型的概率预测更接近目标结果。
有效上下文通常包括:
| 信息类型 | 例子 | 作用 |
|---|---|---|
| 任务目标 | “实现用户积分扣减接口” | 确定交付物 |
| 技术栈 | “Go + PostgreSQL + Redis” | 限定实现方式 |
| 项目结构 | “接口在 internal/api,业务逻辑在 internal/service” | 避免乱放代码 |
| 约束条件 | “积分扣减必须防止并发超扣” | 降低错误实现概率 |
| 输出格式 | “只输出迁移 SQL 和 service 层代码” | 减少无关内容 |
| 验收标准 | “并发 100 个请求时总扣减不能超过余额” | 让结果可检查 |
但这里有一个无法绕开的事实:只要是概率模型,就不可能保证每次都对。
p^n 困境:复杂任务会把成功率指数级拉低
假设 AI 完成一个小步骤的成功率是 p,一个任务需要连续完成 n 个步骤,并且任何一步错了都会影响整体结果,那么端到端成功率就是:
p^n
这个公式很简单,但它解释了很多 AI Agent(人工智能代理)在复杂任务上失败的原因。
| 单步成功率 p | 10 步任务 | 20 步任务 | 50 步任务 |
|---|---|---|---|
| 90% | 34.9% | 12.2% | 0.5% |
| 95% | 59.9% | 35.8% | 7.7% |
| 98% | 81.7% | 66.8% | 36.4% |
| 99% | 90.4% | 81.8% | 60.5% |
单步 95% 已经很高,但 50 步连续任务只剩 7.7% 的端到端成功率。软件开发里的真实任务往往远不止 50 步:理解需求、设计表结构、写接口、处理权限、处理异常、写测试、改配置、跑构建、修 lint、更新文档、兼容历史数据……每一步都可能出错。
很多人会把希望放在模型变强上。模型变强当然有用,但它解决不了数学结构本身。只要 p < 1,当 n 足够大,p^n 就会快速下降。
工程上更有效的办法不是只盯着提高 p,而是减少 AI 需要独立承担的 n。
这会带来一个关键转变:不要把复杂任务端到端扔给 AI,而要让人、确定性程序和 AI 分工。
flowchart TB
U[人: 明确需求、方案和验收标准] --> A[AI: 生成方案草稿或代码初稿]
A --> T[确定性工具: 编译、测试、Lint、类型检查]
T -->|失败| A
T -->|通过| R[人: 关键评审和风险判断]
R -->|需要修改| A
R -->|通过| S[沉淀为文档、脚本、测试和规范]
这里的核心原则是:能用确定性工具解决的,不要交给 LLM 猜。
编译器、测试框架、静态扫描工具、格式化工具、CI/CD(Continuous Integration/Continuous Delivery,持续集成/持续交付)都不“聪明”,但它们有一个 LLM 没有的优点:确定性。输入相同,规则相同,结果就相同。
上下文舒适区:信息太少不行,太多也会坏
LLM 的输出质量和上下文质量高度相关,但上下文不是越多越好。有效信息长度和输出质量之间,更像一条先上升、再平稳、再下降的曲线。
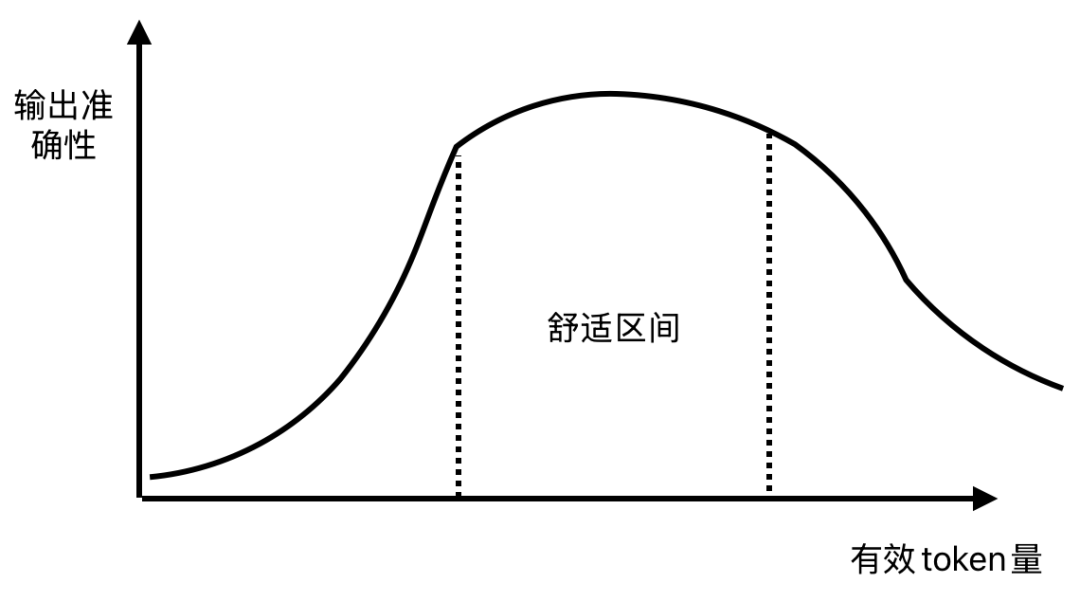
这条曲线可以分成三个区域:
| 区域 | 上下文状态 | 典型表现 | 工程策略 |
|---|---|---|---|
| 上升区 | 信息不足 | AI 在猜,输出发散 | 补充需求、约束、项目背景 |
| 舒适区 | 信息足够且聚焦 | 输出稳定,成本可控 | 保持任务边界清晰 |
| 衰退区 | 信息过载 | 遗忘需求、混入噪声、速度变慢 | 压缩上下文、拆分任务、使用子 Agent |
同一个模型处理不同任务时,舒适区的位置也不同。
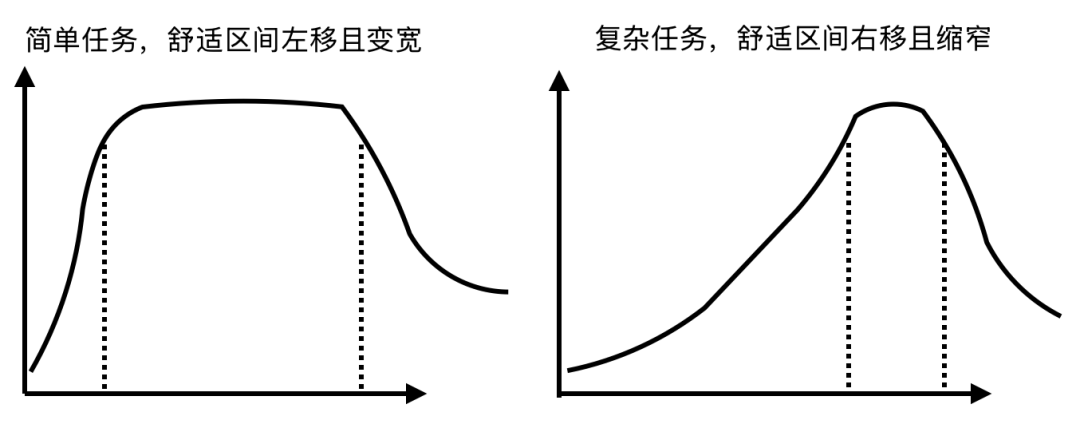
简单任务需要的上下文少,舒适区更容易到达;复杂任务需要更多背景、约束和验收标准,舒适区会右移,同时区间更窄。也就是说,复杂任务不仅需要更多信息,还更怕信息组织混乱。
信息不足:用问答式补全把需求拉进舒适区
很多失败的 AI 编程都从一个模糊请求开始:
帮我写一个在线五子棋小游戏。
这个请求缺少太多关键信息:
- Web、桌面还是移动端?
- 单机对战还是真人联网?
- 是否需要账号体系?
- 是否需要匹配大厅?
- 是否需要聊天?
- 前端技术栈是什么?
- 后端技术栈是什么?
- 数据是否需要持久化?
- 预期并发是多少?
让 AI 在这么大的空间里自由发挥,得到的往往是 Demo,而不是可靠功能。
更好的方式是让 AI 先提问,把需求补齐:
我要做一个在线五子棋小游戏。不要直接写代码,先通过问题帮我细化需求。
每轮最多问 5 个问题,优先询问会影响架构设计的内容。
问题尽量使用单选或多选形式。
AI 可以输出:
1. 运行平台:
A. Web 浏览器
B. 桌面客户端
C. iOS/Android
D. 小程序
2. 对战模式:
A. 本地双人
B. 真人联网
C. 人机对战
D. 真人联网 + 人机兜底
3. 是否需要账号体系:
A. 不需要,游客即可
B. 需要手机号登录
C. 需要微信/QQ 登录
D. 需要自建账号系统
问答式补全的价值在于降低用户表达成本,同时快速增加有效上下文。很多 Spec-driven Development(规格驱动开发)工具和 AI 编程工具都在做类似事情:先把模糊想法变成结构化规格,再进入设计和编码。
信息过载:上下文压缩不是简单删字
当对话越来越长,模型会进入衰退区。上下文压缩可以缓解问题,但压缩不是把 8000 Token 机械缩成 1000 Token,而是提取对后续任务真正有用的信息。
例如原始对话:
用户:我需要实现购物车功能。
AI:需要确认技术栈、存储方式、商品结构……
用户:我们用 React,需要支持增删改查。
AI:可以使用 Context API 管理状态……
用户:要支持本地存储,不需要后端同步。
较好的压缩结果应该像这样:
需求:使用 React 实现购物车功能,支持商品增删改查。
状态管理:React Context API。
数据结构:{ id, name, price, quantity, image }。
持久化:使用 localStorage,本阶段不需要后端同步。
核心功能:添加商品、删除商品、修改数量、计算总价。
真正困难的是边界信息、指代关系和决策背景。
| 压缩难点 | 风险 |
|---|---|
| 当前规模和未来规模同时出现 | 只保留一个会导致过度设计或设计不足 |
| “它”“这个按钮”“那个接口”等指代 | 压缩后失去引用对象 |
| 早期约定在后续被反复使用 | 只保留“需要认证”会丢失 JWT、刷新 Token、过期时间等细节 |
| 同一概念有多个名字 | “购物车”“cart”“ShoppingBasket”可能被误认为不同概念 |
| 决策原因被删掉 | 只保留结果,后续无法解释为什么不用另一个方案 |
这也是很多长时间运行的 AI Agent 会逐渐变差的原因:压缩后的上下文看起来短了,但关键约束可能丢了。
任务外包:Multi-Agent 的本质是隔离上下文
Multi-Agent(多代理)不是魔法。它真正有价值的地方,是把一个大任务拆成多个边界清晰的小任务,让每个子 Agent 只拿到完成任务所需的最小上下文。
flowchart LR
M[主 Agent: 负责规划和整合] --> D[设计 Agent: 生成方案]
M --> T[测试 Agent: 生成测试用例]
M --> C[编码 Agent: 实现单个任务]
M --> R[审查 Agent: 检查规范和风险]
D --> M
T --> M
C --> M
R --> M
这和软件团队分工类似。前端工程师不需要知道数据库索引的每个细节,后端工程师也不需要知道按钮 hover 动画的每个参数。接口定义清楚,各自完成职责,再通过联调整合。
对 AI 来说,子任务边界越清晰,上下文越聚焦,成功率越高。
人和 AI 都会错,但错误类型不同
人类工程师也不可靠。会误解需求,会写 bug,会漏测边界,会因为疲劳犯低级错误。成熟的软件工程并不是假设人不会错,而是通过评审、测试、灰度、回滚和监控来控制错误。
但 AI 的不可靠和人的不可靠有本质差异。
人类能力通常具有层级性。一个能设计复杂分布式系统的高级工程师,通常不会突然不知道如何打开 IDE(Integrated Development Environment,集成开发环境),也不会忘记函数怎么定义。学生能做对高难压轴题,通常说明基础知识已经比较扎实,简单题最多可能粗心算错,而不是完全不会。
LLM 不遵循这种层级关系。它可能解出复杂数学题,也可能在简单小数比较上出错;它可能生成完整 React 应用,也可能数错某个英文单词里有几个字母。因为它不是从基础能力逐层构建高级能力,而是在海量数据中学习模式分布。
这就引出两个概念:
| 类型 | 含义 | 例子 | 系统设计难度 |
|---|---|---|---|
| Known Unknown | 知道哪里可能有未知风险 | 新人容易漏边界条件,所以安排 Code Review | 可针对性防护 |
| Unknown Unknown | 不知道风险会从哪里冒出来 | AI 在复杂推理后突然写错文件操作参数 | 很难提前布防 |
人类团队的错误更接近 Known Unknown。我们知道需求会误解,所以做需求评审;知道代码会有 bug,所以写测试;知道发布会有风险,所以灰度和回滚。
LLM 的错误更接近 Unknown Unknown。它可能在任何环节翻车,而且错误常常带着自信语气。一个系统如果要依赖 AI,就不能只问“AI 强不强”,还要问“AI 的错误能不能被检测、隔离和恢复”。
LLM 不是 AGI:知识多不等于真正智能
AGI(Artificial General Intelligence,通用人工智能)通常意味着一个系统能在广泛环境中自主学习、迁移能力、自我纠错并持续提升。当前 LLM 虽然知识量巨大,但离这个定义还有关键差距。
两个能力尤其重要。
自我纠错能力
真正智能体应该能形成闭环:
flowchart LR
A[设定目标] --> B[采取行动]
B --> C[观察结果]
C --> D[判断是否达成目标]
D -->|未达成| E[调整策略]
E --> B
D -->|达成| F[结束]
婴儿想拿玩具,够不到会换姿势、爬椅子、继续尝试。它知道目标有没有达成,因为“玩具是否在手里”是内在可感知的标准。
LLM 生成代码后,并不知道代码是否正确。除非外部系统运行测试、编译器报错、用户指出问题,否则它只是完成了一次输出。即使它重新生成,也不代表它真正“知道”上一版为什么错。
自我提升能力
人学骑自行车,每次摔倒都会改变身体控制和神经连接。同一个人在不断升级。
LLM 推理时参数固定。今天写了一次排序算法,不会让明天的同一个模型天然更擅长排序算法。模型能力提升通常来自重新训练、微调、强化学习或外部记忆系统,而不是推理过程中的自发成长。
这也是为什么“让 AI 反思一下”有时有效、有时无效。所谓反思,更多是把新的文字上下文加入对话,让下一次概率预测更可能落在正确区域,而不是模型本身真的成长了。
责任心不能外包给 AI
软件工程中,可靠交付不只依赖能力,还依赖责任。
一个工程师写生产代码时会小心,是因为错误有后果:线上事故、绩效影响、团队信任下降、业务损失。责任心不是抽象美德,而是“我必须承担后果”带来的行为约束。
AI 没有这种约束。它没有工资、绩效、名誉、职业发展,也不会因为一次错误在下次任务中真正感到压力。它能输出“我会谨慎处理”,但这只是语言模式,不是内在责任。
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)和 AI Alignment(AI 对齐)可以让模型更倾向于输出安全、礼貌、谨慎的回答,但它们训练的是行为模式,不是后果意识。模型可以学会在某些场景说“我不确定”,也可以学会拒绝危险请求,但这不等于它真的在乎结果。
因此,人机协作必须遵守一个边界:
AI 可以承担产出,但人必须承担责任。
这不是否定 AI 的价值,而是明确系统设计的责任闭环。工程师不需要手写每一行代码,但需要保证最终交付物可理解、可运行、可维护、可回滚。
用系统对抗 AI 的不可靠
航空、建筑、软件团队都已经证明了一件事:个体不可靠并不可怕,可怕的是系统没有容错机制。
成熟软件团队会把错误拦在不同阶段:
| 阶段 | 可能错误 | 系统机制 |
|---|---|---|
| 需求阶段 | 理解偏差、遗漏边界 | 需求评审、原型确认、验收标准 |
| 设计阶段 | 架构不合理、数据模型错误 | 技术方案评审、ADR、容量评估 |
| 编码阶段 | Bug、风格混乱、性能隐患 | Lint、类型检查、Code Review |
| 测试阶段 | 漏测、回归问题 | 单元测试、集成测试、端到端测试 |
| 发布阶段 | 环境差异、配置错误 | CI/CD、预发布、灰度、回滚 |
| 运行阶段 | 线上异常、容量波动 | 监控、告警、限流、熔断 |
AI 协同开发也应该这样设计。不要幻想一个万能 Prompt 让 AI 永远正确,而要建设一套流程,让 AI 即使犯错,也能尽早暴露、局部隔离、快速修正。
构建可靠 AI 协同系统的三条原则
原则一:确定性优先
可程序化的事情,尽量交给程序,而不是交给 LLM 临场发挥。
错误示例:
写完代码后,请根据项目情况自行构建、测试和修复问题。
这个指令把构建流程变成了概率任务。AI 可能忘记参数,可能用错环境,可能跳过某个检查。
更好的做法是把流程固化成脚本:
#!/usr/bin/env bash
set -euo pipefail
echo "1. 格式化代码"
gofmt -w .
echo "2. 静态检查"
golangci-lint run ./...
echo "3. 运行单元测试"
go test ./... -race -cover
echo "4. 构建二进制"
go build -o bin/app ./cmd/app
然后告诉 AI:
修改代码后必须执行 ./scripts/check.sh。
如果失败,只根据报错修复相关代码,不要改动无关模块。
这样,AI 仍然可以帮忙修复问题,但检查规则由确定性工具负责。
同样的思路也适用于:
| 可固化环节 | 工具或产物 |
|---|---|
| 代码格式 | gofmt、prettier、black |
| 静态检查 | golangci-lint、ESLint、Ruff |
| 类型检查 | TypeScript、MyPy、Pyright |
| 测试 | pytest、go test、JUnit |
| 构建 | Makefile、npm scripts、Dockerfile |
| 部署 | GitHub Actions、GitLab CI、Jenkins |
| API 文档 | OpenAPI、Swagger |
| 数据库变更 | migration 脚本 |
每固化一个确定性环节,AI 要猜的步骤就少一个。n 变小,整体可靠性就会上升。
原则二:减少可能性空间
开放问题会让 AI 在巨大空间里随机选择。约束越清楚,输出越稳定。
模糊请求:
帮我优化这个接口性能。
这个请求没有说明瓶颈在哪里、约束是什么、能不能改接口、能不能加缓存、能不能改表结构。AI 可能随便给出 Redis、异步化、索引、批处理等方案,但未必适合实际系统。
约束后的请求:
这个接口每秒约 1000 次调用,性能瓶颈来自 PostgreSQL 查询。
已决定使用 Redis 缓存,不允许修改 API 入参和返回结构。
请完成三件事:
1. 设计缓存 key,要求能区分租户和用户;
2. 实现读取缓存、回源数据库、写入缓存的逻辑;
3. 设置过期时间,业务数据平均 30 分钟更新一次。
只修改 internal/service/user_score.go,并补充对应单元测试。
这段 Prompt 做了几件事:
- 限定瓶颈:数据库查询;
- 限定方案:Redis;
- 限定兼容性:API 不变;
- 限定改动范围:只改一个文件;
- 限定验收:补测试。
可能性空间越小,AI 越不容易跑偏。
原则三:阶段性交付,可验收后再继续
不要让 AI 一次生成一个完整系统。复杂任务应该拆成可沉淀、可验收的阶段性成果。
以“用户积分系统”为例,一个可靠流程可以这样设计:
flowchart TB
A[阶段 1: 需求细化] --> B{人工验收}
B -->|通过| C[阶段 2: 技术方案]
B -->|补充需求| A
C --> D{人工验收}
D -->|通过| E[阶段 3: 任务拆分和验收标准]
D -->|调整方案| C
E --> F{人工验收}
F -->|通过| G[阶段 4: 单任务编码]
F -->|重拆任务| E
G --> H[确定性检查: 测试/Lint/构建]
H -->|失败| G
H -->|通过| I{人工评审}
I -->|通过| J[合并并沉淀文档]
I -->|修改| G
阶段 1:需求细化
请帮我细化用户积分系统需求,不要写代码。
需要覆盖:
- 积分获得规则:哪些行为获得积分,各自多少分;
- 积分消耗规则:能兑换什么,扣减顺序是什么;
- 积分过期规则:是否过期,如何处理历史积分;
- 并发规则:如何防止重复发放和超额扣减;
- 审计规则:是否需要积分流水,流水字段有哪些。
输出为需求文档,使用 Markdown 表格描述规则。
这一阶段产出的需求文档本身就是高质量上下文。即使后续换模型、换工程师,也能复用。
阶段 2:技术方案设计
基于已确认的需求文档,设计技术方案,不要写实现代码。
需要输出:
- 数据库表结构,包括字段、索引、唯一约束;
- 核心领域模型;
- 核心 API 定义;
- 积分发放流程;
- 积分扣减流程;
- 并发控制方案,并说明选择乐观锁或悲观锁的理由;
- 失败重试和幂等策略。
方案阶段要人工重点验收。因为这里的错误会传导到所有代码实现。
阶段 3:任务拆分和验收标准
请把积分系统拆分成可独立实现的任务。
每个任务必须包含:
- 任务名称;
- 功能描述;
- 依赖项;
- 涉及文件;
- 验收标准;
- 必须通过的测试用例。
任务粒度要求:单个任务可以在一次对话中完成,且能独立测试。
好的任务拆分可以缩小 AI 的爆炸半径。某个任务失败,只需要重做局部,不会推倒整个系统。
阶段 4:逐个任务编码
当前只实现 Task 1:积分流水表 migration 和数据模型。
约束:
- 严格遵守 agents.md 中的项目规范;
- 只修改 migration 目录和 internal/model/points.go;
- 不实现 service 逻辑;
- 必须补充模型字段注释;
- 完成后执行 ./scripts/check.sh。
验收标准:
- migration 可以正常 up/down;
- 字段、索引、约束符合技术方案;
- go test ./... 通过。
这种方式的价值不是“让 AI 慢一点”,而是让每一步都能沉淀资产。需求文档、设计方案、任务列表、测试用例、脚本和规范,都会让下一轮协作更可靠。
项目里的 agents.md 应该写什么
AI 编程工具通常支持项目级说明文件,例如 agents.md、CLAUDE.md、.cursorrules 等。这个文件不是口号墙,而是给 AI 的项目操作手册。
一个实用的 agents.md 可以包含:
# 项目背景
这是一个多租户积分系统,后端使用 Go,数据库使用 PostgreSQL,缓存使用 Redis。
# 目录约定
- cmd/app:程序入口
- internal/api:HTTP handler
- internal/service:业务逻辑
- internal/repository:数据库访问
- internal/model:领域模型
- migrations:数据库迁移脚本
# 编码规范
- handler 不写业务逻辑,只做参数解析和响应组装
- service 必须接收 context.Context
- repository 只负责数据访问,不包含业务判断
- 所有外部错误必须包装上下文信息
- 所有新增逻辑必须包含单元测试
# 检查命令
修改代码后必须执行:
./scripts/check.sh
# 禁止事项
- 不要修改公共 API,除非任务明确要求
- 不要引入新的第三方库,除非先说明理由并获得确认
- 不要跳过测试
这类文件的价值在于把隐性团队经验变成显性上下文。它可以减少 AI 每次都重新猜项目习惯的概率。
工程师角色会变成什么
AI 时代的软件开发更像两级编译:
flowchart LR
A[业务需求] --> B[工程师: 结构化规格和验收标准]
B --> C[AI: 生成代码和文档草稿]
C --> D[确定性工具: 编译/测试/扫描]
D --> E[工程师: 评审和决策]
E --> F[生产系统]
过去,工程师主要把需求翻译成代码。现在,工程师越来越多地把需求翻译成结构化规格、约束、测试和流程,再让 AI 生成代码。真正的编译器仍然负责把代码变成机器可执行的产物,而 AI 更像夹在需求和代码之间的新型编译层。
这会改变工程师的核心能力模型:
| 过去更重要 | 现在越来越重要 |
|---|---|
| 熟悉语法和 API | 能把需求写清楚 |
| 手写实现速度 | 任务拆解和边界定义 |
| 单点调试能力 | 构建可验收流程 |
| 个人编码熟练度 | 沉淀项目上下文和自动化工具 |
| 记住框架细节 | 判断 AI 输出是否符合系统约束 |
程序员不会因为 AI 直接消失,但会出现明显分化。能把需求、架构、测试、自动化和 AI 协同流程组织起来的人,会借助 AI 放大产出;只会等待 AI 一次性吐出完整项目、又无法验收结果的人,会被复杂任务反复拖进调试泥潭。
可靠的 AI 协同不是“完全放手”,而是逐步建设一个系统:
- 确定性的事情交给程序;
- 模糊但可生成的事情交给 AI;
- 关键判断和责任留给人;
- 每次协作都沉淀文档、脚本、测试和规范。
当这些资产不断积累,AI 才会从一个不稳定的代码生成器,变成软件工程体系中的高效协作者。