开源项目的价值不只在于 Star 数量,更在于它解决了什么具体问题,以及这个问题背后的技术设计是否清晰。下面这 7 个项目覆盖了几个很典型的方向:个人媒体聚合、个人数据归档、AI 工作流、体素游戏、浏览器自动化和医疗信息系统。
| 项目 | 解决的问题 | 核心机制 | 适合人群 |
|---|---|---|---|
| Stremio Web | 把不同来源的视频内容放到统一界面浏览 | 插件化内容源 + Web 媒体中心 | 想自建媒体入口的用户、前端开发者 |
| Timelinize | 把照片、聊天记录、位置、社交数据整理成个人时间线 | 多源导入 + SQLite 本地存储 + 时间轴视图 | 重视个人数据归档和本地控制的用户 |
| Flowise | 用拖拽方式搭建 AI 智能体和 LLM 工作流 | 可视化节点编排 + LLM 组件集成 | AI 应用开发者、低代码自动化使用者 |
| Cubyz | 开源体素沙盒游戏 | 无限三维地图 + 体素渲染 + 自由合成系统 | 游戏玩家、体素引擎爱好者 |
| Computer Use Preview | 用自然语言指挥浏览器完成任务 | Gemini + Playwright 浏览器自动化 | AI Agent、浏览器自动化研究者 |
| Stagehand | 用代码和自然语言混合控制浏览器 | TypeScript 自动化框架 + AI 操作描述 | 前端测试、自动化脚本开发者 |
| OpenEMR | 管理诊所的电子健康记录和日常业务 | EHR 模块 + 排班 + 账单 + 药房管理 | 医疗信息化团队、诊所系统维护者 |
Stremio Web:插件化的网页版媒体中心
Stremio Web 是一个开源的网页版媒体中心。它本身不是视频网站,也不直接提供影视资源,而是提供一个统一的浏览和播放界面,真正的内容来自用户安装的插件。
这种设计把“播放器”和“内容源”拆开了:
flowchart LR
A[用户打开 Stremio Web] --> B[统一媒体界面]
B --> C{已安装插件}
C --> D[电影目录]
C --> E[电视剧信息]
C --> F[直播或其他内容源]
D --> G[播放器]
E --> G
F --> G
插件可以提供目录、详情、播放源等信息。Stremio Web 负责把这些信息组织成统一体验,用户不用在多个网站或客户端之间切换。
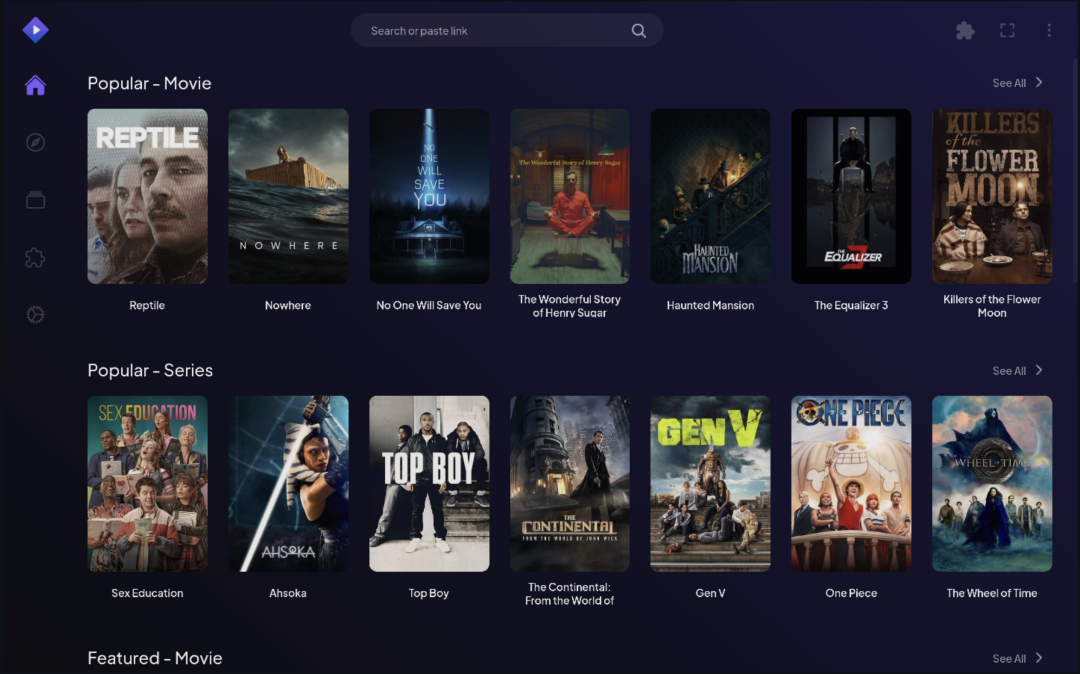
界面截图展示的是 Stremio Web 的核心使用方式:内容被集中放在同一个 Web 界面里浏览。真正需要注意的是,界面只是入口,内容质量、可用性和合法性都取决于安装的插件。
从开发角度看,它是一个基于 Node.js 构建的 Web 项目,适合前端开发者研究媒体中心的组织方式、插件系统的接入方式,以及 Web 播放器的交互设计。
典型的本地构建流程类似这样,具体脚本名称以仓库里的 package.json 为准:
git clone https://github.com/Stremio/stremio-web.git
cd stremio-web
npm install
npm run build
它采用 GPLv2 许可证。如果要修改并分发自己的版本,需要遵守 GPLv2 对应的开源义务。
开源地址:
https://github.com/Stremio/stremio-web
适合与不适合的场景
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 想把多个视频来源集中到一个入口 | 适合 | 插件机制正是为多来源聚合设计的 |
| 想研究 Web 媒体中心交互 | 适合 | 前端界面、播放体验、插件接入都有参考价值 |
| 期待项目直接提供影视资源 | 不适合 | 项目本体不提供内容 |
| 对内容版权和插件来源没有控制 | 谨慎 | 插件质量和合法性需要自行判断 |
Timelinize:把个人数字生活整理成一条时间线
Timelinize 解决的是个人数据分散的问题。照片在手机里,聊天记录在社交软件里,位置历史在地图服务里,联系人和社交媒体内容又在不同平台中。时间久了,数据虽然都属于自己,却很难被统一检索和回顾。
Timelinize 的思路是:把这些来源的数据导入到本地,按时间重新组织,然后通过时间线、地图、人物、组织等视图浏览。
flowchart LR
A[Google Takeout] --> D[Timelinize 导入器]
B[iCloud 数据] --> D
C[Facebook 等社交数据] --> D
E[照片 视频 聊天记录 位置 联系人] --> D
D --> F[解析与标准化]
F --> G[(本地 SQLite 数据库)]
G --> H[时间线视图]
G --> I[地图视图]
G --> J[人物和组织筛选]
G --> K[聊天记录合并展示]
G --> L[统计图表]
它的关键点有三个。
一是数据存储在本地。导入后的内容会进入 SQLite 数据库,用户仍然可以直接浏览文件,也可以通过 Timelinize 的界面检索和探索。
二是它支持多个来源。比如 Google Takeout、iCloud、Facebook 等导出的数据包,不需要用户先手动拆开所有文件,Timelinize 可以识别并处理原始压缩包。
三是它不是简单的“文件管理器”。照片、视频、聊天、位置、联系人等内容会围绕时间重新组织,不同平台的聊天记录也可以被合并查看。
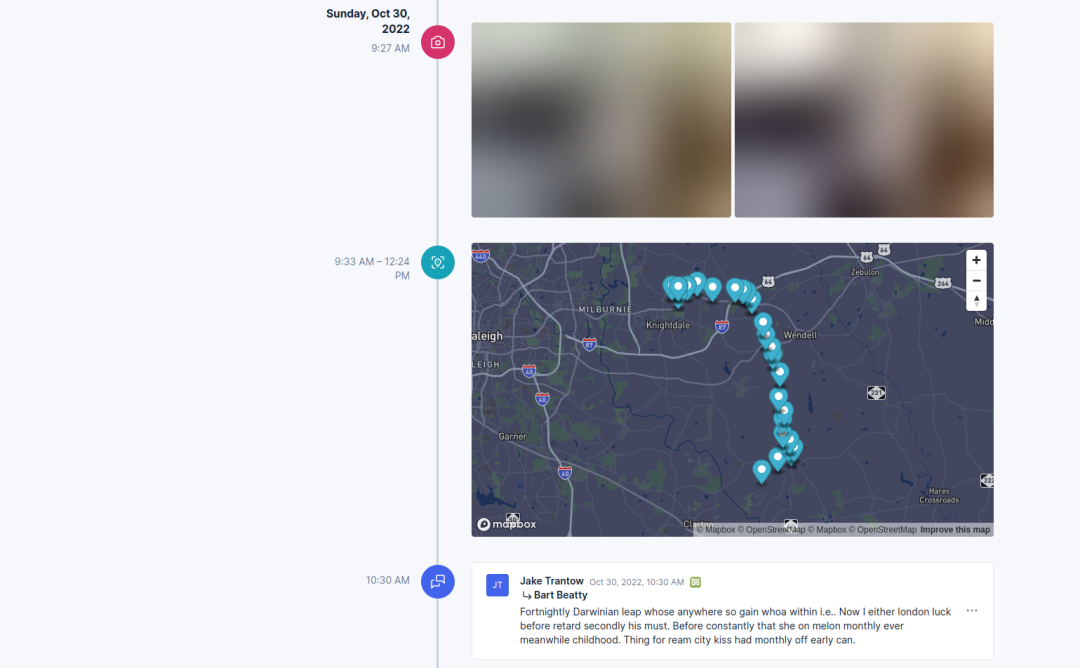
界面截图体现的是 Timelinize 的核心价值:数据不再按“来自哪个平台”分散展示,而是按时间、人物、位置等维度重新关联。对个人数据归档来说,这比单纯把文件备份到硬盘更容易检索。
开源地址:
https://github.com/timelinize/timelinize
使用时要注意什么
| 注意点 | 说明 |
|---|---|
| 数据量可能很大 | 多年照片、视频、聊天记录导入后会占用大量磁盘空间 |
| 导入前建议备份 | 原始导出包最好保留一份,避免清洗或迁移时不可逆 |
| 隐私级别高 | 时间线、位置、联系人都属于敏感数据,本地机器要做好加密和访问控制 |
| SQLite 适合个人使用 | 对单人本地归档很方便,但不等同于多人协作型数据平台 |
Flowise:用可视化节点搭建 AI 智能体
Flowise 是一个可视化 AI 工作流工具,目标是降低搭建 LLM(大语言模型)应用和智能体的门槛。它把模型、提示词、记忆、工具、向量数据库、检索器等组件做成节点,用户通过拖拽和连线组合出完整流程。
flowchart LR
A[用户输入] --> B[Prompt 模板]
B --> C[LLM 模型节点]
C --> D{是否需要工具}
D -->|需要| E[工具调用]
D -->|不需要| F[直接生成]
E --> C
C --> G[输出结果]
H[向量数据库] --> I[检索器]
I --> B
这种方式适合快速验证 AI 应用想法。例如:
- 搭建一个基于私有文档的问答机器人;
- 把用户输入交给模型判断,再调用外部工具;
- 给智能体加入记忆,让它能保留对话上下文;
- 把流程封装成接口,供其他系统调用。
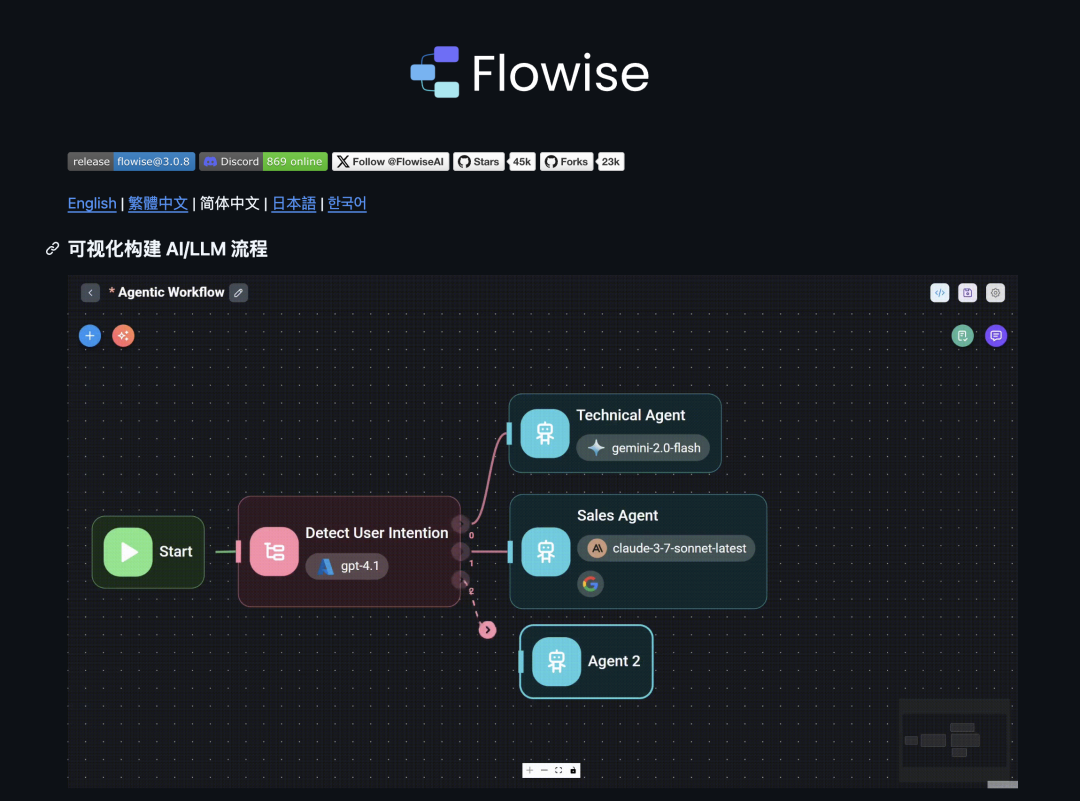
截图展示的是 Flowise 的典型工作方式:不同 AI 能力以节点形式出现在画布上,节点之间的连线表示数据流向。相比直接写代码,这种方式更适合调试流程结构,尤其是在验证原型时,可以很快看出输入、检索、模型调用和输出之间的关系。
Node.js 环境下可以这样启动:
npm install -g flowise
flowise start
启动后通常会在本地开放一个 Web 管理界面,用来创建和运行工作流。更严肃的部署场景需要额外处理鉴权、密钥管理、日志、版本控制和资源隔离。
开源地址:
https://github.com/FlowiseAI/Flowise
Flowise 更适合做什么
| 场景 | 适配程度 | 说明 |
|---|---|---|
| AI 应用原型验证 | 高 | 拖拽节点比从零写代码快 |
| 内部知识库问答 | 高 | 可组合文档加载、向量检索和模型节点 |
| 固定流程自动化 | 中高 | 流程清晰时可视化编排很直观 |
| 高度定制的复杂业务系统 | 中 | 后期可能仍要写代码扩展 |
| 对安全和审计要求很高的生产系统 | 需要谨慎 | 要补齐权限、密钥、日志、监控等工程能力 |
Cubyz:开源体素沙盒游戏
Cubyz 是一个开源体素沙盒游戏,设计灵感来自 Minecraft,但它并不只是复刻方块世界。它强调几个方向:
- 超远视距渲染;
- 真正无限的三维地图;
- 没有固定高度和深度限制;
- 更自由的物品合成系统。
体素游戏的核心难点通常在地图生成、区块加载、渲染优化和存档结构上。一个无限世界不可能一次性全部加载进内存,常见做法是把世界切成很多区块,根据玩家位置动态加载和卸载。
flowchart LR
A[玩家位置] --> B[计算附近区块]
B --> C[加载可见区块]
B --> D[卸载远处区块]
C --> E[生成或读取地形数据]
E --> F[体素网格构建]
F --> G[渲染画面]
Cubyz 的自由合成系统也比较有意思。传统游戏往往要求玩家按照固定配方合成物品,而 Cubyz 更强调“玩家组合材料,系统识别意图”。这会让合成系统从静态配方表,变成更动态的物品识别逻辑。
开源地址:
https://github.com/PixelGuys/Cubyz
对开发者的参考价值
| 方向 | 可研究的问题 |
|---|---|
| 体素引擎 | 区块划分、网格生成、可见性优化 |
| 无限地图 | 地形生成、坐标系统、存档结构 |
| 游戏交互 | 自由合成系统如何识别玩家意图 |
| 开源游戏工程 | 游戏逻辑、资源管理、跨平台构建方式 |
Computer Use Preview:用 Gemini 控制浏览器
Computer Use Preview 是 Google 开源的浏览器控制项目。它让用户用自然语言描述目标,然后由模型理解任务,再通过浏览器自动化工具完成操作。
举个例子,用户输入“搜索某条新闻并打开相关结果”,系统需要把这句话拆成几个动作:打开搜索引擎、输入关键词、提交搜索、判断结果、点击目标页面。背后不只是文本生成,还涉及浏览器状态观察和动作执行。
sequenceDiagram
participant U as 用户
participant A as Computer Use Preview
participant M as Gemini 模型
participant B as Playwright 浏览器
U->>A: 输入自然语言任务
A->>M: 发送任务和当前浏览器状态
M-->>A: 返回下一步操作计划
A->>B: 执行点击、输入、跳转等动作
B-->>A: 返回页面状态
A->>M: 继续让模型判断下一步
M-->>A: 返回完成或继续操作
A-->>U: 输出执行结果
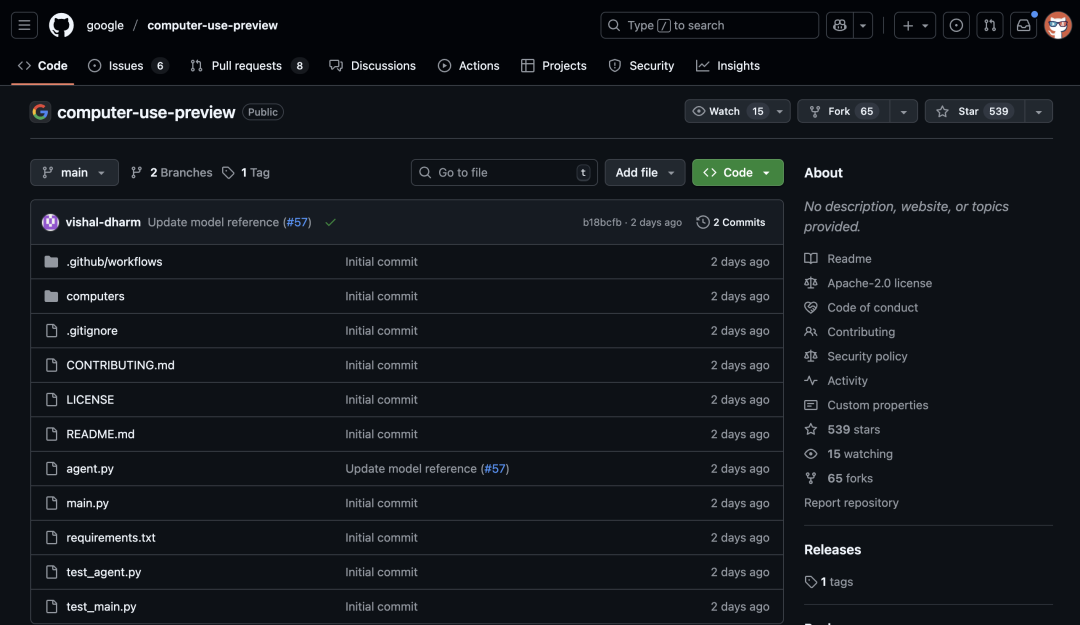
截图展示的是自然语言控制浏览器的使用入口。它的关键不在于“能打开网页”,而在于模型可以根据页面反馈循环决策:每一步执行后重新观察页面,再决定下一步动作。
准备环境通常包括 Python、Playwright 和 Gemini API(应用程序编程接口)密钥:
git clone https://github.com/google/computer-use-preview.git
cd computer-use-preview
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
playwright install
export GEMINI_API_KEY="你的 Gemini API 密钥"
实际运行命令需要以项目仓库说明为准。它支持本地浏览器运行,也可以连接云端浏览器服务,这让它既能用于个人电脑实验,也能接入更隔离的远程执行环境。
开源地址:
https://github.com/google/computer-use-preview
这种工具的边界
| 能力 | 说明 |
|---|---|
| 适合半结构化网页任务 | 搜索、表单填写、信息提取、流程点击都比较典型 |
| 不适合无约束高风险操作 | 支付、删除数据、账号安全相关动作需要人工确认 |
| 页面变化会影响稳定性 | 动态页面、弹窗、验证码都会增加失败率 |
| 成本来自模型调用 | 每次观察和决策都可能消耗模型请求额度 |
Stagehand:把自然语言嵌入浏览器自动化代码
Stagehand 也是浏览器自动化方向的开源项目,但它和 Computer Use Preview 的定位略有不同。
Computer Use Preview 更像“给一个任务,让智能体自己操作浏览器”。Stagehand 更像“开发者写自动化代码,遇到复杂页面时可以用自然语言描述要做什么”。
它适合 TypeScript / JavaScript 技术栈,尤其是那些已经在使用 Playwright 或类似浏览器自动化工具的团队。传统自动化脚本依赖选择器,例如:
await page.locator("#search-input").fill("open source ai browser automation")
await page.locator("#submit").click()
当页面结构频繁变化时,选择器会变脆。Stagehand 这类工具尝试让开发者用更接近人类意图的方式描述操作,例如“点击搜索框并搜索这个关键词”。这种方式不能完全替代确定性代码,但可以在页面结构复杂、元素难以稳定定位时减少脚本维护成本。
开源地址:
https://github.com/browserbase/stagehand
Computer Use Preview 与 Stagehand 的区别
| 对比项 | Computer Use Preview | Stagehand |
|---|---|---|
| 主要语言生态 | Python 项目为主 | TypeScript / JavaScript 生态 |
| 控制方式 | 自然语言任务驱动 | 代码流程中嵌入自然语言操作 |
| 更像什么 | 浏览器智能体 Demo / 框架 | AI 增强的浏览器自动化工具 |
| 适合场景 | 研究模型如何操作电脑和浏览器 | 改造自动化测试、爬取、表单流程 |
| 稳定性策略 | 依赖模型观察和决策循环 | 可以混合确定性代码与 AI 操作 |
OpenEMR:开源电子健康记录和诊所管理系统
OpenEMR 是一个开源的 EHR(电子健康记录)和医疗诊所管理系统。它覆盖的不只是病历,还包括诊所日常运营中的多个环节,例如预约排班、账单、药房、患者资料等。
flowchart TB
A[OpenEMR] --> B[患者档案]
A --> C[电子病历]
A --> D[预约排班]
A --> E[电子账单]
A --> F[药房管理]
A --> G[报表与运营数据]
界面截图展示的是 OpenEMR 的医疗业务管理入口。和普通后台管理系统相比,医疗系统对数据完整性、访问权限、审计记录和隐私保护要求更高,因为它处理的是患者身份、诊疗记录、用药和账单等敏感信息。
OpenEMR 支持 Windows、Linux 和 macOS 等平台。评估或测试时,可以优先查看仓库中的 Docker 或安装说明。常见的开源系统本地试运行流程类似这样:
git clone https://github.com/openemr/openemr.git
cd openemr
docker compose up -d
具体服务端口、数据库配置和初始化步骤需要以仓库文档为准。医疗软件不能只看“能不能跑起来”,还要关注合规、备份、权限隔离和数据迁移。
开源地址:
https://github.com/openemr/openemr
部署 OpenEMR 前要重点检查
| 检查项 | 为什么重要 |
|---|---|
| 权限模型 | 医生、护士、前台、管理员看到的数据范围不同 |
| 审计日志 | 医疗数据需要知道谁在什么时间访问或修改了什么 |
| 数据备份 | 病历和账单丢失会造成严重业务风险 |
| 隐私合规 | 不同地区对医疗数据存储和访问有不同规定 |
| 本地化 | 语言、账单规则、药品信息、诊疗流程可能需要调整 |
| 升级策略 | 医疗系统生命周期长,版本升级不能破坏历史数据 |
按需求选择项目
如果目标是“自己用”,Stremio Web 和 Timelinize 更偏个人工具;如果目标是“开发 AI 应用”,Flowise、Computer Use Preview 和 Stagehand 更适合研究;如果关注开源游戏或医疗信息化,Cubyz 和 OpenEMR 分别提供了比较完整的业务样本。
| 需求 | 可以优先看 |
|---|---|
| 想做统一视频入口 | Stremio Web |
| 想整理多年个人数据 | Timelinize |
| 想快速搭建 AI 工作流 | Flowise |
| 想研究体素游戏引擎 | Cubyz |
| 想让 AI 操作浏览器 | Computer Use Preview |
| 想把 AI 加到浏览器自动化脚本里 | Stagehand |
| 想研究诊所管理系统 | OpenEMR |
这些项目覆盖的技术栈差异很大,但都有一个共同点:它们不是单个函数或小脚本,而是围绕真实场景组织出来的完整系统。学习这类项目时,不必只盯着安装命令,更应该看清楚它们如何拆分模块、如何管理数据、如何处理外部依赖,以及哪些边界条件会影响实际使用。