大型语言模型(Large Language Model,LLM)应用要想变得更好,传统路线通常有两条:一条是微调模型参数,另一条是改提示词、加示例、接知识库、补工具说明。前者改的是模型本身,后者改的是模型看到的输入。
Agentic Context Engineering(智能体式上下文工程,ACE)走的是第二条路线,但它不是简单地把提示词写得更长,而是把系统提示、历史经验、工具使用规范、领域知识、常见错误模式组织成一份持续演化的“作战手册”。模型每完成一批任务,系统就从成功和失败里提炼经验,再把这些经验增量写回上下文。模型参数不变,但下一次推理能看到更好的上下文。
相关论文题为 Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models,核心想法可以概括成一句话:
不一定要通过更新模型参数来学习,很多应用层能力可以通过更新上下文来学习。
这并不等于微调没有价值。ACE 更像是把一部分“任务经验积累”和“领域策略沉淀”从参数层移到上下文层,让它更容易解释、修改、回滚和共享。
上下文适应解决什么问题
LLM 应用里的“上下文”不只是用户输入的一句话。一个真实系统通常会把很多信息一起送给模型:
- 系统提示词:告诉模型角色、目标、输出格式和约束;
- 示例:给模型少量演示,让它模仿任务模式;
- 记忆:记录历史事实、用户偏好、过去的成功策略;
- 工具说明:告诉模型有哪些 API、参数怎么传、返回值怎么理解;
- 领域规则:例如金融报表字段含义、法律条款解释、业务流程限制;
- 事实证据:减少幻觉,给回答提供外部依据。
把这些内容放进输入,让训练完成后的模型适应新任务,这就是上下文适应。
它和微调的区别很直接:
| 方式 | 改什么 | 适合什么 | 主要代价 |
|---|---|---|---|
| 微调 | 模型参数 | 稳定任务分布、固定风格、需要模型内化的能力 | 需要数据和训练资源,更新慢,回滚成本高 |
| 普通提示词优化 | 输入提示词 | 明确任务格式、减少歧义、快速调试 | 容易依赖人工经验,难持续积累复杂知识 |
| ACE | 结构化上下文 | 智能体任务、工具调用、领域经验积累、测试时自我改进 | 需要反馈、日志、去重和上下文治理 |
上下文适应的优势在应用层很明显:上下文是可读的,工程师能检查它到底学到了什么;上下文能在运行时更新,不必重新训练模型;同一份上下文还能给多个模型、多个模块共享。
长上下文模型的发展也让这条路线更现实。过去上下文窗口很短,很多经验不得不压缩成几句话;现在模型能处理更长输入,再配合 KV 缓存(Key-Value Cache,推理时复用历史注意力计算结果)、上下文压缩和卸载,长上下文的部署成本不再必然线性增长。
普通提示词优化的两个问题:简约偏置和上下文塌缩
很多提示词优化方法会追求“短、通用、抽象”。这种目标在简单任务上有用,但在智能体和知识密集型任务里会损失大量细节。
简约偏置:把有用细节压没了
简约偏置指优化器偏爱简短提示词,倾向于把经验压缩成抽象规则。问题在于,很多任务真正有价值的东西并不抽象:
- 某个工具调用前必须检查哪些字段;
- 某个 API 返回空数组时代表什么;
- 金融报表里的某类字段不能直接相加;
- 某个任务经常失败在日期边界或单位换算上;
- 某种错误提示意味着应该换一条工具链。
这些内容写成一句“注意数据一致性”并没有用。模型需要的是可执行的策略,而不是听起来正确的口号。
上下文塌缩:反复重写后越来越短、越来越模糊
如果每次都让 LLM 重写整个提示词,旧经验很容易被概括、合并、丢弃。几轮之后,原本细粒度的工具说明和错误案例可能变成一段泛泛的摘要,系统表现反而下降。
下图展示的是上下文塌缩现象:整体重写会让上下文逐渐丢失细节,模型可用的信息越来越少。
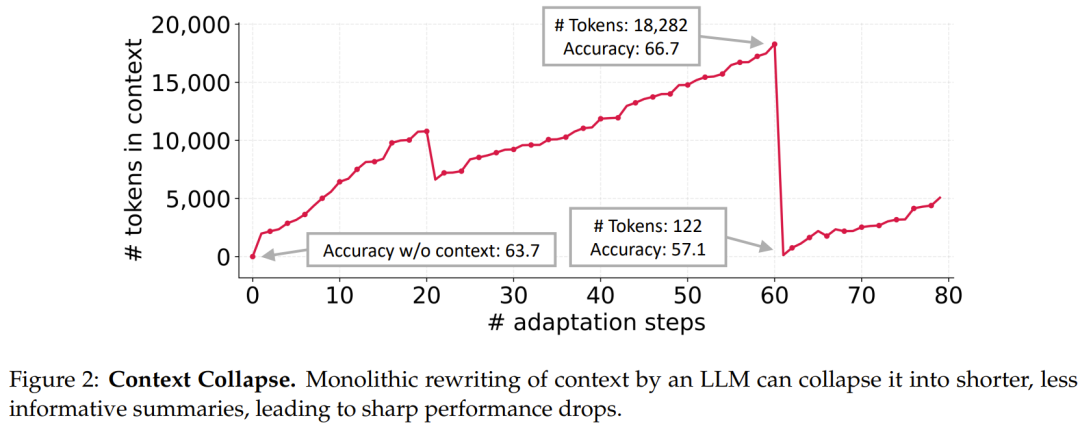
图里的重点不是“上下文越长越好”,而是“有用细节不能被无差别压缩”。在交互式智能体、代码任务、金融分析、法律分析这类场景里,模型需要保留大量任务相关经验。ACE 的设计就是围绕这一点展开:上下文不应该是一段短摘要,而应该是一份可增长、可修订、可去重的作战手册。
ACE 的核心架构:生成、反思、整编
ACE 把上下文演化拆成三个角色:
- 生成器(Generator):执行任务,生成推理轨迹、工具调用和最终答案;
- 反思器(Reflector):分析成功和失败,从轨迹里提炼具体经验;
- 整编器(Curator):把经验整理成结构化条目,并合并进现有上下文。
这三个角色对应一条学习闭环:实验、反思、整合。
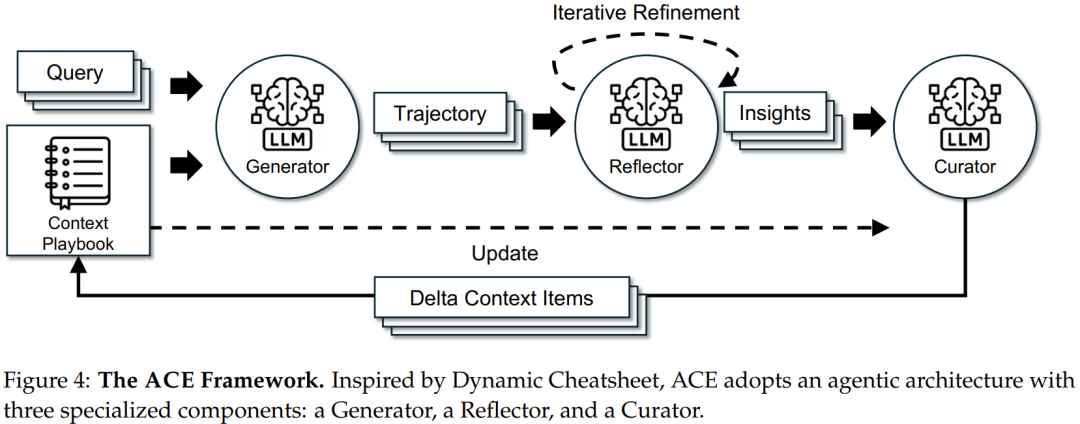
图中可以看到,ACE 不是让一个模型同时负责所有事情。生成器专注于解决任务,反思器专注于从过程里找规律,整编器专注于维护上下文质量。职责拆开后,系统更容易扩展,也更容易定位问题:如果经验提炼得差,检查反思器;如果上下文变乱,检查整编器;如果任务轨迹本身质量差,检查生成器和反馈信号。
用流程图表示,ACE 的主循环大致如下:
flowchart TD
A[现有作战手册] --> B[生成器执行新任务]
B --> C[推理轨迹与工具调用日志]
B --> D[环境反馈或评测结果]
C --> E[反思器提炼经验]
D --> E
E --> F[整编器生成 Delta 条目]
F --> G[去重、合并、更新计数器]
G --> H[新版作战手册]
H --> B
这条链路有两个关键点。
第一,ACE 依赖反馈。反馈可以来自环境执行结果、单元测试、人工标注、排行榜评测,也可以来自任务自带的正确性检查。没有反馈,反思器很难判断哪些策略真的有用。
第二,ACE 不直接重写整份上下文。它生成的是局部增量,也就是 delta entries,再通过轻量规则合并到上下文里。这样能避免上下文塌缩,也能降低每次更新的计算成本。
上下文不是一整段提示词,而是一组结构化条目
ACE 的一个重要设计是:把上下文拆成条目集合,而不是维护一个巨大的字符串。
一个条目可以包含两类信息:
from dataclasses import dataclass
@dataclass
class ContextBullet:
id: str
useful_count: int
harmful_count: int
content: str
其中:
id是唯一标识;useful_count记录这个条目帮助过多少次;harmful_count记录这个条目误导过多少次;content存放可复用策略、领域概念、工具规则或常见错误模式。
例如,一个金融报表任务里的条目可能长这样:
id: fin-formula-017
useful_count: 8
harmful_count: 1
content:
在计算利润率时,先确认分子和分母是否来自同一会计期间。
如果 XBRL 字段包含 duration 和 instant 两类时间属性,不要直接混用。
一个工具调用智能体里的条目可能长这样:
id: appworld-calendar-004
useful_count: 12
harmful_count: 0
content:
调用 calendar.search_events 前,必须先把用户给出的自然语言日期解析成起止时间。
如果用户说“下周一”,需要结合当前环境日期,而不是使用模型默认日期。
条目化以后,系统可以做三件事:
| 能力 | 做法 | 好处 |
|---|---|---|
| 局部更新 | 只修改相关条目,不重写全部上下文 | 降低丢失旧知识的风险 |
| 细粒度检索 | 根据任务找最相关的条目 | 避免把无关经验塞给模型 |
| 质量治理 | 用有用/有害计数器管理条目 | 可以剪枝、降权、回滚 |
Delta 更新:只改该改的部分
普通提示词优化常见做法是让 LLM 输出一版新的完整提示词。ACE 不这样做。它让反思器和整编器产生少量 delta 条目,再把这些条目合并到作战手册里。
伪代码可以写成这样:
def ace_update(playbook, tasks):
trajectories = []
for task in tasks:
result = generator.solve(task, context=playbook)
feedback = evaluate(result, task)
trajectories.append((task, result, feedback))
insights = reflector.extract_insights(trajectories)
delta_entries = curator.normalize(insights)
playbook = merge_delta(playbook, delta_entries)
playbook = grow_and_refine(playbook)
return playbook
合并时不需要每次都调用 LLM:
def merge_delta(playbook, delta_entries):
for entry in delta_entries:
matched = find_similar_bullet(playbook, entry)
if matched is None:
playbook.append(entry)
else:
matched.content = merge_content(matched.content, entry.content)
matched.useful_count += entry.useful_count
matched.harmful_count += entry.harmful_count
return playbook
这种设计带来几个工程收益:
- 延迟更低:不用让模型重写整份上下文;
- 更稳定:旧知识不会因为一次摘要被覆盖;
- 可并行:多个 delta 可以分别生成、分别合并;
- 可审计:每个新增条目都能追踪来源和作用。
Grow-and-Refine:既允许增长,也要定期修剪
如果只增长不修剪,作战手册会变成垃圾堆;如果只压缩不增长,又会回到简约偏置和上下文塌缩。
ACE 采用 grow-and-refine 机制:
- Grow:新经验先追加进上下文,保证有用细节不被过早丢弃;
- Refine:根据语义相似度、计数器和上下文窗口限制,合并重复条目、删除低价值条目、修订旧条目。
可以把它理解成一个持续运行的知识库维护过程:
flowchart LR
A[新增经验] --> B[追加为新条目]
B --> C{是否重复或相似}
C -- 是 --> D[合并到已有条目]
C -- 否 --> E[保留为新条目]
D --> F[更新 useful/harmful 计数]
E --> F
F --> G{上下文是否过长}
G -- 是 --> H[剪枝低价值或冲突条目]
G -- 否 --> I[进入下一轮任务]
H --> I
去重通常可以用语义嵌入相似度完成。比如两个条目都在说“调用某工具前必须检查日期范围”,就没有必要重复保留。计数器能帮助系统判断条目质量:长期有用的条目保留,频繁误导模型的条目降权或删除。
ACE 生成的上下文长什么样
ACE 不是只产出几句“请仔细思考”。它会生成包含领域知识、工具规范、代码片段和失败案例的详细上下文。
下面是 AppWorld 基准中 ACE 生成的上下文示例。

图中展示的内容更接近工程手册,而不是传统提示词。它包含可直接复用的任务策略、工具调用注意事项和代码级提示。这样的上下文对人类来说可能偏长,但 LLM 可以在推理时从中挑选相关信息。ACE 的立场是:不要过早替模型删掉可能有用的细节,让模型在长上下文里自己做选择。
实验设置:智能体任务和金融任务
ACE 的验证覆盖两类任务。
一类是智能体任务,使用 AppWorld 基准。AppWorld 关注多轮推理、工具调用和环境交互,适合衡量一个智能体是否能在真实流程里完成任务,而不是只会生成文本。
另一类是金融领域任务,包含 FiNER 和 Formula:
- FiNER:识别 XBRL(可扩展商业报告语言)财报文档中的细粒度实体类型;
- Formula:在结构化财报中做数值推理和计算。
对比方法包括:
| 方法 | 含义 | 特点 |
|---|---|---|
| ICL | In-Context Learning,上下文学习 | 在输入里给少量示例,让模型模仿 |
| MIPROv2 | 一种提示词优化方法 | 使用贝叶斯优化搜索提示词 |
| GEPA | 一种反思式提示词进化方法 | 通过反思和演化改进提示词 |
| Dynamic Cheatsheet | 动态备忘单机制 | 在测试时积累可复用知识 |
| ACE | 智能体式上下文工程 | 生成、反思、整编,增量维护作战手册 |
整体结果如下图所示。
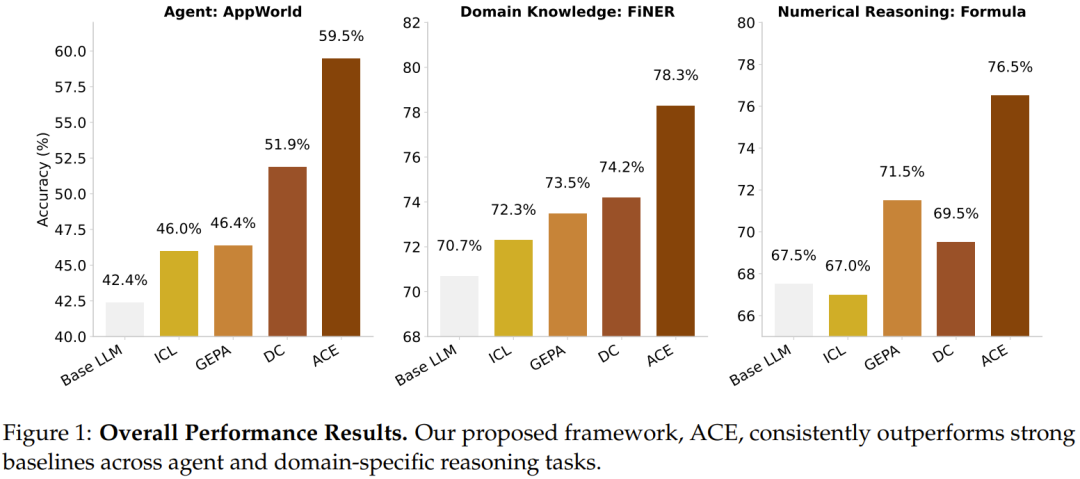
图中的对比强调了 ACE 的核心优势:在相同基模型和运行条件下,通过上下文演化获得更高准确率,同时适应速度和成本也更有竞争力。它不是靠训练新参数,而是靠持续改进输入给模型的作战手册。
AppWorld:不用标注数据,也能靠执行反馈改进智能体
在 AppWorld 上,ACE 只利用执行反馈就能改进智能体表现,不需要额外标注数据。实验中性能提升最高达到 17.1%,让一些开源小模型的表现接近强商用系统。
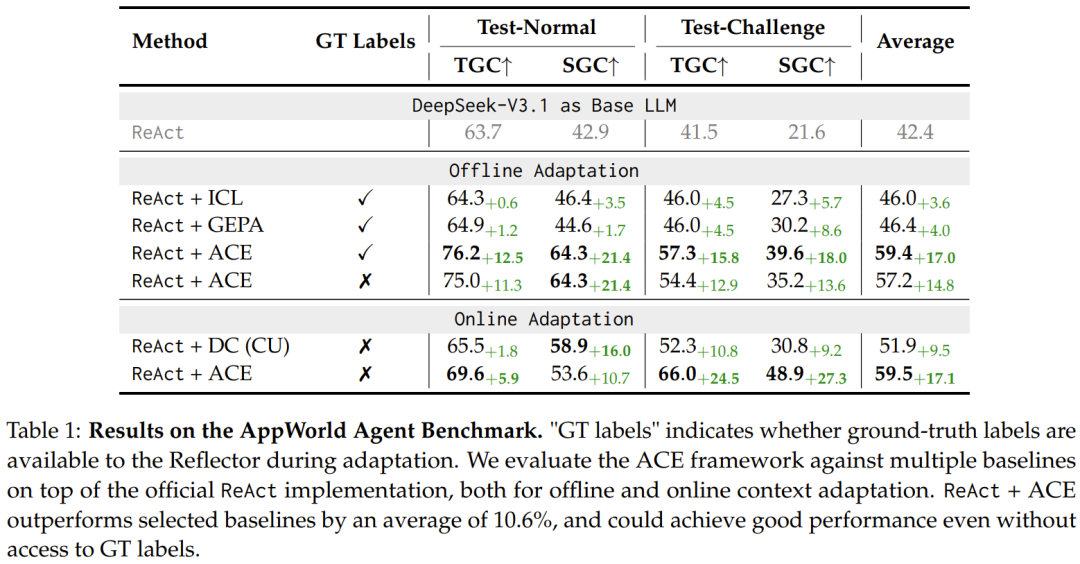
这类任务特别适合 ACE,因为智能体会留下大量可学习的过程信息:工具调用顺序、失败原因、环境返回值、缺失参数、边界条件。反思器可以从这些轨迹里提炼非常具体的经验,再让整编器写入上下文。
例如,智能体如果多次因为日期解析错误导致工具调用失败,ACE 可以沉淀出类似规则:
在调用日历工具前,先把相对日期解析为绝对日期;
如果任务环境提供当前日期,必须使用环境日期,不要使用模型默认日期;
如果用户给出时间范围,要检查开始时间是否早于结束时间。
这样的规则放进作战手册后,后续任务就能直接受益。
金融任务:领域知识越细,作战手册越有用
金融分析依赖大量细粒度规则。模型不仅要读懂字段,还要知道字段之间能不能比较、能不能相加、时间范围是否一致、单位是否一致。很多错误不是语言理解错误,而是领域规则错误。
在 FiNER 和 Formula 上,ACE 通过积累领域知识作战手册,平均性能提升 8.6%。
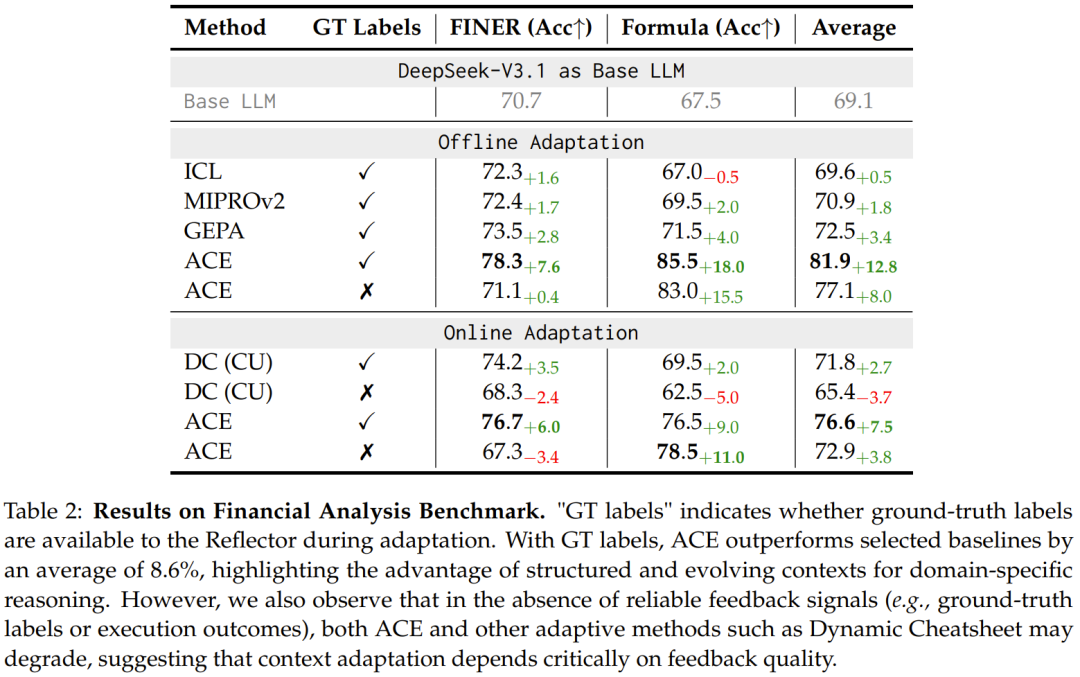
这说明 ACE 不只适合工具调用智能体,也适合知识密集型任务。尤其是那些“规则很多、容易犯错、反馈可获得”的任务,ACE 能把模型每次踩坑的经验保存下来。
消融实验:反思器和多轮蒸馏很关键
ACE 的效果不只来自“上下文变长”。消融实验显示,反思器、多轮蒸馏等组件对性能有明显影响。
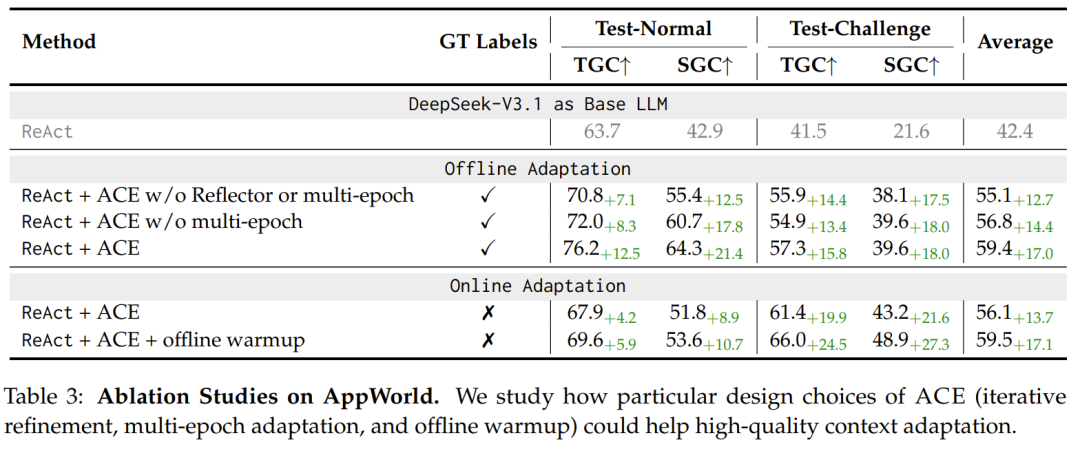
这点很重要。如果只是把所有历史轨迹直接塞进上下文,模型会被大量噪声干扰。ACE 真正有价值的部分在于反思和整编:它不是机械保存日志,而是把日志转成可复用策略,再通过去重和修订维持上下文质量。
成本与延迟:长上下文不必然等于高 Serving 成本
ACE 生成的上下文通常比 GEPA 这类提示词优化方法更长,但实验显示,增量更新和轻量合并能显著降低适应延迟,平均降幅达到 86.9%,同时减少生成消耗。
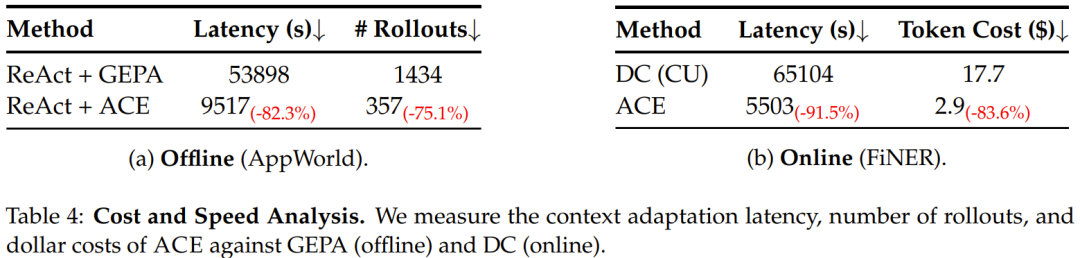
原因在于 ACE 不反复重写整份上下文,而是生成小块 delta,再用非 LLM 逻辑合并。另一方面,现代推理服务可以复用稳定上下文的 KV 缓存。对于多次调用都会使用的作战手册,系统可以缓存它的前缀计算结果,避免每次从头算。
但长上下文仍然有工程边界:
- 新上下文第一次预填充仍有成本;
- 动态变化太频繁会降低缓存命中;
- 上下文过长会增加检索、排序和剪枝负担;
- 无关内容过多仍可能干扰模型注意力;
- 多租户系统还要处理隐私隔离和缓存失效。
所以“长上下文不一定贵”成立的前提是:上下文结构稳定、复用率高、合并策略合理,并且有服务层优化配合。
在工程系统里怎样落地 ACE
一个可落地的 ACE 系统通常需要五个模块。
flowchart TD
A[任务输入] --> B[生成器]
P[作战手册] --> B
B --> C[轨迹日志]
B --> D[任务输出]
D --> E[评测器或环境反馈]
C --> F[反思器]
E --> F
F --> G[整编器]
G --> H[Delta 条目]
H --> I[合并与去重模块]
I --> P
比较稳妥的实现步骤如下:
-
设计作战手册结构
不要只维护一个大字符串,可以按章节组织:任务目标、工具 API、领域规则、常见错误、示例模板、禁止事项。 -
记录生成器轨迹
轨迹至少包含任务输入、使用的上下文条目、推理过程摘要、工具调用、环境返回、最终结果。 -
建立可靠反馈
智能体任务可以用环境执行结果,代码任务可以用单元测试,结构化任务可以用标准答案或规则检查。 -
让反思器提炼具体经验
反思器输出不应该是“下次更谨慎”,而应该是“调用 X 工具前必须检查 Y 字段”。 -
由整编器做格式化和去重
整编器负责把经验变成统一条目,并避免重复、冲突和过度增长。
一个反思器提示模板可以这样写:
你会看到一组任务轨迹、工具调用和评测反馈。
请只提炼可复用的具体经验,不要写泛泛建议。
输出格式:
- 适用场景:
- 可复用规则:
- 常见错误:
- 推荐工具调用顺序:
- 需要更新或删除的旧规则:
整编器则可以要求输出结构化 JSON:
{
"new_entries": [
{
"type": "tool_rule",
"content": "调用 calendar.search_events 前必须解析相对日期,并使用环境当前日期。",
"source_task_ids": ["task_102", "task_118"]
}
],
"update_entries": [
{
"id": "calendar-004",
"operation": "merge",
"content": "补充:如果用户给出时间范围,要验证开始时间早于结束时间。"
}
],
"delete_entries": []
}
ACE 适合什么,不适合什么
ACE 不是微调的全面替代。它适合的是应用层可观察、可反馈、可积累经验的场景。
| 场景 | 是否适合 ACE | 原因 |
|---|---|---|
| 工具调用智能体 | 适合 | 轨迹丰富,错误可复盘,策略可沉淀 |
| 领域分析任务 | 适合 | 规则多,经验细,作战手册能持续补充 |
| 少标注数据场景 | 适合 | 可以利用执行反馈,不强依赖训练集 |
| 需要快速回滚的系统 | 适合 | 上下文条目可审计、可删除 |
| 需要模型学会全新语言或底层能力 | 不太适合 | 上下文很难弥补模型能力边界 |
| 极低延迟、极短输入预算 | 不太适合 | 长上下文和检索治理有成本 |
| 稳定格式、大规模同分布任务 | 视情况而定 | 微调可能更省推理成本 |
| 高敏感记忆场景 | 谨慎使用 | 需要隐私过滤、选择性遗忘和访问控制 |
ACE 更适合解决“模型其实会,但缺少任务经验和上下文知识”的问题;微调更适合解决“模型分布不匹配、风格需要固化、能力需要内化”的问题。
需要注意的坑
反馈不可靠会污染作战手册
如果评测器本身经常误判,反思器就会从错误反馈里提炼错误规则。上线前最好给 delta 条目设置审核、置信度或灰度机制。
条目越多不代表越好
作战手册需要增长,也需要治理。重复条目、过期规则、错误经验都会伤害模型表现。harmful_count、语义去重、版本回滚都很重要。
不能把私密信息无脑写入上下文
ACE 的记忆机制可能保存用户数据、业务数据或敏感字段。工程系统需要做脱敏、权限隔离、保留周期控制和选择性删除。
长上下文需要配合检索
即使模型支持长上下文,也不代表每次都要塞入全部作战手册。更合理的做法是按任务检索相关条目,再把高相关内容放进输入。
微调没有消失,学习位置发生了变化
ACE 的价值在于把“系统如何从经验中变好”这件事做到了上下文层。模型参数保持不变,作战手册持续演化;每一次任务执行都可能产生新经验,每一次失败都可能变成下一次成功的规则。
这条路线给 LLM 应用带来几个现实好处:更新快、可解释、易回滚、能跨模型共享,也能支持选择性遗忘。它不会取代所有微调需求,但会改变很多智能体和领域应用的优化方式。
当任务有清晰反馈、经验能被结构化表达、上下文可以被稳定复用时,ACE 是一种很有工程吸引力的模型进化方式:不改模型本体,而是让模型身边那本作战手册越写越好。