Deep Research 类 Agent(智能体)的目标,是把一个开放问题拆成多个子问题,自动检索资料、阅读网页、整合证据,最后生成一份结构完整的研究报告。
这类系统看起来已经很强:输入一个复杂问题,它能在短时间内访问大量网页,整理出几千字甚至上万字内容。但真正影响质量的,往往不是“搜得够不够多”,而是报告有没有稳定主线、证据是否服务于结论、前后是否一致。
Google Deep Researcher 提出的 Test-Time Diffusion,解决的正是这个问题:不要把检索和写作拆成两个割裂阶段,而是让粗糙草稿在推理时不断被检索结果修正,像“去噪”一样逐步变成高质量报告。
这里的 Diffusion 不是图像生成里的扩散模型,也不是训练一个新的扩散网络。它是一种工作流比喻:初始草稿是噪声较多的状态,后续每轮检索和改写都在降低噪声。
传统 Deep Research 流程的问题
常见深度研究 Agent 通常采用这种流程:
flowchart LR
A[用户问题] --> B[一次性规划]
B --> C[生成检索问题]
C --> D[搜索网页或数据库]
D --> E[整理检索片段]
E --> F[生成最终报告]
这个流程容易实现,也符合很多 RAG(Retrieval-Augmented Generation,检索增强生成)系统的基本思路:先查资料,再让 LLM(Large Language Model,大语言模型)根据资料回答。
问题在于,开放研究任务不是简单问答。研究报告需要在写作过程中不断调整判断:
| 问题 | 传统流程中的表现 | 对最终报告的影响 |
|---|---|---|
| 规划过早固定 | 一开始拆出来的子问题决定了后续搜索方向 | 如果初始规划漏掉关键角度,后面很难补救 |
| 检索缺少全局目标 | 每个子问题各搜各的,信息之间缺少互相约束 | 报告像资料拼接,主线不清 |
| 冲突发现太晚 | 生成报告时才发现不同来源说法不一致 | 容易出现前后矛盾 |
| 新信息难以重塑结构 | 检索结果通常被塞进既有大纲 | 重要发现可能只变成局部补丁 |
| 质量评估粒度太粗 | 常常只在最终报告阶段检查 | 中间步骤的错误会层层传递 |
更关键的是,传统流程里 Agent 在检索阶段并不知道最终报告会长什么样。它只是根据早期计划完成信息填空,而不是围绕一个正在成形的观点持续查漏补缺。
Test-Time Diffusion 的核心:先写粗稿,再带着粗稿检索
Test-Time Diffusion 的核心状态不是“检索问题列表”,而是一份不断变化的报告草稿。Agent 先基于已有知识写出一个粗糙版本,再把这份草稿当作上下文,反向判断下一轮最需要什么信息。
这会把研究流程改成循环:
- 生成初始研究计划和粗糙报告。
- 阅读当前草稿,找出缺口、薄弱论证、可能冲突和缺失证据。
- 基于这些缺口生成新的检索问题。
- 搜索并阅读资料,提取可引用证据。
- 不只更新某个段落,而是重新审视整份报告。
- 判断报告质量是否足够;不够就继续循环。
这套循环可以理解为报告从粗糙状态逐步去噪:
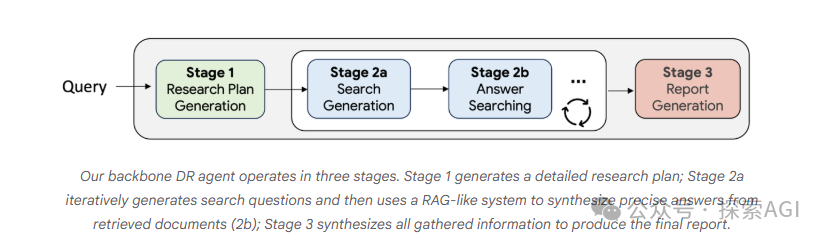
图里的关键不是“多搜几轮”,而是每一轮检索都被当前报告状态驱动。草稿提出问题,检索回答问题,答案再改变草稿。这样做能让后续搜索更聚焦:不是为了堆更多资料,而是为了修正报告里最影响质量的部分。
用流程图表示会更清楚:
flowchart TD
A[用户研究任务] --> B[生成初始计划]
B --> C[生成粗糙报告草稿]
C --> D[诊断草稿缺口]
D --> E[生成下一轮检索问题]
E --> F[搜索与读取资料]
F --> G[抽取证据与结论]
G --> H[报告级改写]
H --> I{质量是否达标}
I -- 否 --> D
I -- 是 --> J[输出最终报告]
这个机制和普通 RAG 的差别很大:
| 维度 | 普通 RAG | Test-Time Diffusion |
|---|---|---|
| 核心输入 | 用户问题 | 用户问题 + 当前报告草稿 |
| 检索目标 | 找和问题相关的信息 | 找能修正当前草稿缺陷的信息 |
| 中间状态 | 检索片段、摘要 | 持续演化的报告 |
| 更新方式 | 把资料喂给模型生成答案 | 对整份报告做去噪式改写 |
| 适合任务 | 明确问答、事实查询 | 开放研究、长报告、多步推理 |
报告草稿为什么能提升检索质量
粗稿的价值不在于一开始就写得好,而在于它暴露了问题。
一个复杂研究任务经常存在几类缺口:
- 某个结论没有证据支撑。
- 某段论证只覆盖了单一视角。
- 不同来源之间存在冲突。
- 报告结构和用户问题不匹配。
- 大纲里有重要子问题没有展开。
- 引用资料太旧,缺少最新进展。
- 某个概念被模糊使用,没有定义边界。
如果没有草稿,Agent 只能根据用户问题猜测该搜什么;有了草稿,Agent 可以针对具体缺口生成更好的检索问题。
例如,用户问:
“比较当前 Deep Research Agent 在企业知识管理中的应用价值和风险。”
传统流程可能直接拆成:
- Deep Research Agent 是什么?
- 企业知识管理是什么?
- 应用价值有哪些?
- 风险有哪些?
Test-Time Diffusion 运行一轮后,草稿可能已经写出“能提升知识发现效率”,但缺少真实企业场景证据。下一轮检索就可以变成:
- “enterprise knowledge management AI agent case study”
- “deep research assistant enterprise search compliance risk”
- “AI research assistant hallucinated citations enterprise knowledge base”
- “knowledge management retrieval agent access control risk”
这些查询明显更贴近报告当前缺口。
两个关键技巧:自我进化和报告级降噪
Google Deep Researcher 不只是把“检索—改写”循环起来,还加入了两个重要设计:自我进化和报告级降噪。
自我进化:一步输出前先生成多个候选
在生成检索问题、整理检索结果、改写报告等环节,系统不是只让模型输出一个版本,而是生成多个候选状态,再让模型评价、修改和融合。
这个过程可以拆成四步:
| 阶段 | 作用 |
|---|---|
| Initial states | 生成多个候选答案、查询或改写版本 |
| Environmental feedback | 让 LLM 对候选进行打分,指出缺陷 |
| Revision | 按反馈修正候选 |
| Cross-over | 融合多个候选中质量较高的部分 |
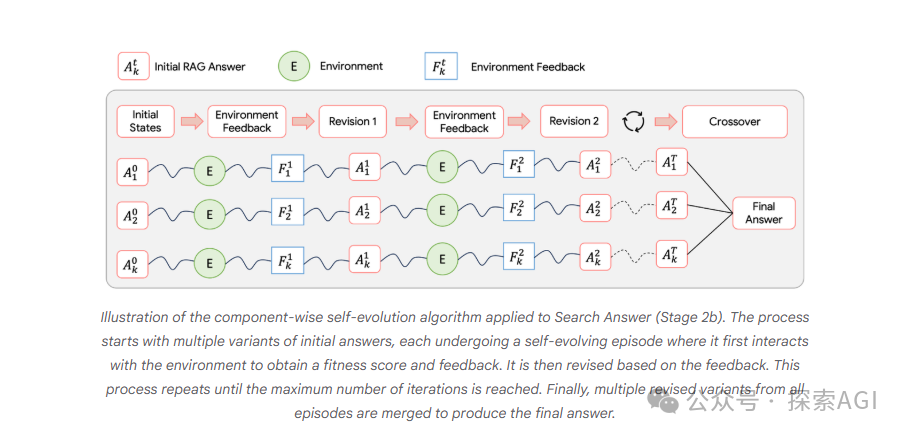
图中展示的是一个小型“进化”过程:模型先产生多个初始状态,再引入反馈进行修订,最后把不同候选的优点合并。它类似工程里的多方案评审:不是相信第一次输出,而是让模型在同一步骤内完成生成、批判、修补和融合。
可以把它抽象成下面的伪代码:
def evolve_step(task, context, n=4):
# 生成多个候选
candidates = [
llm.generate(task=task, context=context)
for _ in range(n)
]
# 对候选进行批判性反馈
feedback = [
llm.critique(task=task, context=context, candidate=c)
for c in candidates
]
# 根据反馈修订候选
revised = [
llm.revise(candidate=c, feedback=f)
for c, f in zip(candidates, feedback)
]
# 融合优点,形成最终输出
final = llm.merge(task=task, context=context, candidates=revised)
return final
这种做法会增加推理成本,但能减少单次生成带来的随机偏差。尤其在检索问题生成阶段,多候选机制能覆盖更多搜索角度;在报告改写阶段,多候选机制能避免一种结构走到底。
报告级降噪:新证据要重写整体,而不是局部追加
很多研究 Agent 的更新方式是“哪里缺就补哪里”。这种做法短期方便,但长报告很容易变成补丁集合。
报告级降噪要求每轮拿到新证据后,重新审视整份草稿:
- 新证据是否推翻了已有判断?
- 某个小节是否需要调整位置?
- 引言里的问题定义是否要改?
- 结论是否需要收敛或改变强度?
- 旧证据和新证据是否冲突?
- 引用是否仍然支撑对应句子?
这相当于把报告作为一个整体状态来更新。
flowchart LR
A[新检索证据] --> B[检查与当前草稿的关系]
B --> C{影响范围}
C -- 局部补充 --> D[增强某段证据]
C -- 结构变化 --> E[调整章节顺序]
C -- 结论变化 --> F[重写核心判断]
C -- 冲突证据 --> G[加入对比与不确定性说明]
D --> H[生成新版报告]
E --> H
F --> H
G --> H
这一步非常关键。研究写作不是把资料按时间顺序粘贴起来,而是不断让证据、结构和结论互相校准。
一个最小可实现版本
如果要自己实现类似工作流,可以先做一个简化版。核心不需要复杂框架,只需要维护一个“报告状态”和一组“证据状态”。
数据结构
from dataclasses import dataclass, field
from typing import list
@dataclass
class Evidence:
url: str
title: str
snippet: str
extracted_claims: list[str]
reliability_note: str = ""
@dataclass
class DraftState:
plan: str
report: str
gaps: list[str] = field(default_factory=list)
evidence: list[Evidence] = field(default_factory=list)
iteration: int = 0
quality_score: float = 0.0
主循环
def deep_research(user_task, max_iter=6, target_score=0.85):
state = initialize_draft(user_task)
for i in range(max_iter):
state.iteration = i + 1
state.gaps = diagnose_gaps(
task=user_task,
plan=state.plan,
report=state.report,
evidence=state.evidence,
)
queries = propose_search_queries(
task=user_task,
report=state.report,
gaps=state.gaps,
)
new_evidence = []
for query in queries:
pages = search_web(query)
new_evidence.extend(read_and_extract(pages, query=query))
state.evidence.extend(new_evidence)
state.report = revise_report_globally(
task=user_task,
old_report=state.report,
gaps=state.gaps,
evidence=state.evidence,
)
state.quality_score = evaluate_report(
task=user_task,
report=state.report,
evidence=state.evidence,
)
if state.quality_score >= target_score:
break
return state.report
草稿诊断 Prompt
你是研究报告审稿人。请审查当前报告草稿,找出最影响质量的缺陷。
用户任务:
{task}
当前计划:
{plan}
当前报告:
{report}
已有证据:
{evidence}
请输出:
1. 缺失但必须回答的问题
2. 证据不足的结论
3. 可能存在冲突的说法
4. 结构不连贯的位置
5. 下一轮最值得检索的 3~8 个信息需求
检索问题生成 Prompt
请根据报告草稿的缺口生成搜索查询。
要求:
- 每个查询必须对应一个明确缺口
- 查询要能找到可引用证据
- 避免泛泛搜索
- 覆盖不同来源和视角
- 输出 JSON 数组,每项包含 gap、query、expected_evidence
报告级改写 Prompt
请基于新证据对整份报告做报告级改写,而不是只追加段落。
用户任务:
{task}
旧报告:
{old_report}
草稿缺口:
{gaps}
证据:
{evidence}
改写要求:
- 保留有证据支持的内容
- 删除或弱化证据不足的判断
- 对冲突信息给出对比说明
- 调整章节结构,使论证更连贯
- 每个关键结论都要能追溯到证据
- 不要编造来源
质量评估不能只看流畅度
深度研究报告最容易“看起来很完整,但细节经不起查”。因此评估器不能只问“写得是否自然”,还要检查证据和结构。
可用的评分维度如下:
| 维度 | 检查问题 |
|---|---|
| 任务覆盖 | 是否回答了用户问题中的所有关键约束 |
| 证据支撑 | 关键结论是否有来源或可验证依据 |
| 一致性 | 前后说法是否冲突 |
| 结构 | 章节顺序是否服务于论证 |
| 深度 | 是否只停留在定义层面,还是解释了原因、代价和边界 |
| 时效性 | 对快速变化主题是否使用了足够新的资料 |
| 引用准确性 | 引用内容是否真的支持对应句子 |
| 不确定性 | 对争议、缺口、未知部分是否明确说明 |
可以让评估器输出结构化结果:
{
"score": 0.78,
"blocking_issues": [
"缺少企业部署案例",
"风险部分没有区分数据安全和合规风险",
"第二节和第四节对成本的判断不一致"
],
"next_search_needs": [
"enterprise AI research assistant deployment case",
"AI agent enterprise knowledge management data security risk",
"deep research agent citation hallucination benchmark"
]
}
这个结果可以直接进入下一轮检索,形成闭环。
Benchmark 结果说明了什么
实验结果的重点不只是“某个系统超过另一个系统”,而是消融对比显示了两个组件的价值。
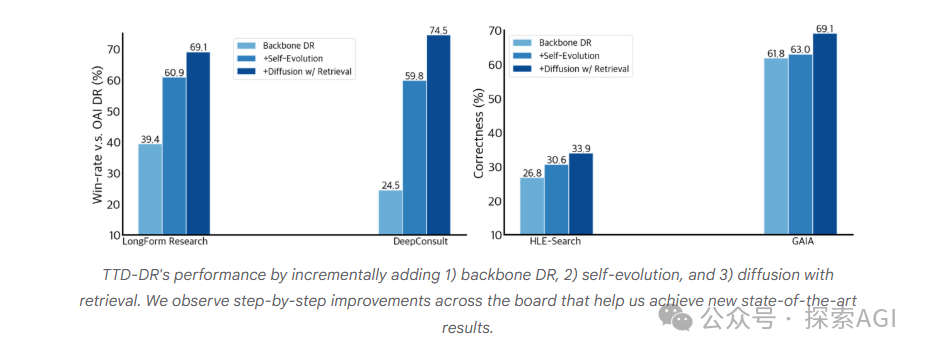
图中的对比思路是:只使用基础 Backbone Deep Research 架构时,系统表现还不够强;加入自我进化和 Test-Time Diffusion 后,表现明显上升,并在 GAIA 等需要多步推理和检索的任务上取得更好结果。
这说明提升来自两个方向:
- 每一步输出更可靠:自我进化让查询、摘要和改写不再完全依赖单次生成。
- 整体报告持续变好:Test-Time Diffusion 让检索围绕草稿缺口展开,并通过报告级改写吸收新证据。
对于 Deep Research 任务来说,单纯扩大搜索数量并不一定带来更好报告。真正关键的是:搜索是否回答了当前报告最缺的信息,改写是否让整份报告更一致。
适合和不适合的场景
Test-Time Diffusion 更适合开放式、多轮推理、证据密集的任务,不适合所有问答。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 行业研究报告 | 适合 | 需要多来源证据、结构化论证和反复修正 |
| 技术方案调研 | 适合 | 需要比较方案、补齐约束、处理取舍 |
| 学术主题综述 | 适合 | 需要围绕草稿不断补证据和找反例 |
| 企业知识库深度问答 | 适合 | 可以用草稿发现缺失文档和冲突信息 |
| 简单事实查询 | 不适合 | 直接检索回答成本更低 |
| 低延迟客服问答 | 通常不适合 | 多轮搜索和改写会增加响应时间 |
| 明确数据库查询 | 不适合 | SQL 或结构化检索更直接 |
| 高风险合规结论自动生成 | 谨慎使用 | 仍需要人工复核证据、引用和责任边界 |
实现时容易踩的坑
1. 搜索查询越来越偏
草稿如果一开始方向错了,后续检索可能会围绕错误假设不断强化。诊断阶段需要显式要求模型寻找反例和替代解释。
请不要只寻找支持当前报告的证据。
必须列出可能推翻当前结论的检索方向。
2. 报告被反复改写后丢失引用关系
报告级改写会调整结构,如果不维护引用映射,很容易出现“句子还在,证据丢了”的情况。更稳妥的做法是把 claim 和 evidence 单独存储。
@dataclass
class Claim:
text: str
evidence_ids: list[str]
confidence: float
3. 停止条件过于主观
让模型自己判断“足够好了”并不可靠。停止条件最好混合使用:
- 最大迭代次数
- 最低质量分
- 连续两轮质量提升低于阈值
- 没有发现新的高价值缺口
- 检索结果重复率过高
4. 成本和延迟会明显增加
多候选生成、自我批判、多轮搜索和整篇改写都会消耗 Token 和搜索调用。工程上可以做几种控制:
| 控制手段 | 作用 |
|---|---|
| 限制每轮查询数量 | 控制搜索成本 |
| 对网页内容做去重 | 减少重复阅读 |
| 只对关键段落做高强度进化 | 避免所有步骤都多候选 |
| 对草稿做分块状态管理 | 降低长上下文开销 |
| 缓存搜索结果和摘要 | 避免同类任务重复调用 |
5. “去噪”不等于不断润色
如果每轮只是把语言写得更流畅,而不是解决证据、结构和冲突问题,Test-Time Diffusion 就会退化成多轮润色。每次迭代都应回答一个明确问题:
这一轮减少了哪一种噪声:事实噪声、结构噪声、证据噪声,还是推理噪声?
和普通 Agent 架构的关系
Test-Time Diffusion 不要求推翻现有 Agent 架构。它更像是在 Planner、Retriever、Reader、Writer 外面加了一个“报告状态循环”。
flowchart LR
U[用户任务] --> S[报告状态 State]
S --> P[Planner / Gap Finder]
P --> Q[Query Generator]
Q --> R[Retriever]
R --> E[Evidence Extractor]
E --> W[Global Rewriter]
W --> S
S --> C[Critic / Evaluator]
C -->|继续迭代| P
C -->|达标| O[最终报告]
这个架构中,State 是核心。只要报告状态维护得好,底层检索可以接网页搜索、企业知识库、学术数据库,也可以接代码仓库、日志系统或内部文档平台。
Google Agentspace 的 Research Assistant 已经提供了相关能力入口:
https://cloud.google.com/agentspace/docs/research-assistant
关键启发
Deep Research 的质量瓶颈不只是模型能力,也不只是搜索覆盖率,而是“研究过程是否围绕一个不断演化的中间成果展开”。
Test-Time Diffusion 把粗糙报告变成工作流中心,让 Agent 每轮都问自己:
- 当前报告哪里最不可靠?
- 哪些信息能最大幅度修正它?
- 新证据是否需要改变整体结构?
- 最终结论是否仍然成立?
当检索由草稿驱动,写作由证据校准,报告就不再是资料堆叠,而是一个持续去噪后的研究结果。