FireRedTTS-2 是一个面向对话语音生成的 TTS(Text-to-Speech,文本语音合成)模型。它要解决的不是普通的“给一段文字生成一段语音”,而是更复杂的多说话人对话合成:同一段音频里有多个角色轮流说话,每个角色要保持自己的音色,句子之间要有自然停顿和衔接,长对话里还不能频繁出现读错字、换错人、韵律断裂等问题。
典型应用包括 AI 播客、多人有声内容、虚拟主播对话、语音助手多轮交互,以及给语音识别、对话理解等下游任务批量生成训练数据。FireRedTTS-2 的核心设计可以概括为两点:
- 用低帧率、语义信息更强的离散语音编码器,把语音压缩成更适合大模型处理的 token 序列;
- 用文本-语音混排的生成格式,让模型既能利用历史上下文,又能支持逐句生成和流式起播。
多说话人对话合成难在哪里
普通 TTS 只需要关注一件事:一段文字对应一段语音。多说话人对话合成要同时处理四类问题。
| 问题 | 具体表现 | 对系统的要求 |
|---|---|---|
| 发音正确性 | 中文读错字、英文读错词、跨语言发音不稳 | 文本到语音 token 的映射要稳定 |
| 说话人一致性 | A 说着说着变成 B 的声音,或者角色切换边界混乱 | 说话人标签和音色条件要可靠 |
| 对话韵律 | 每句话单独听还行,连起来像拼接音频 | 模型要理解上下文里的停顿、重音、情绪 |
| 生成灵活性 | 整段一次性生成后不好改,交互式场景无法边生成边播放 | 需要逐句生成、低首包延迟和流式解码 |
早期做法通常把对话按说话人和句子切开,每句话独立合成,再把音频拼起来。这个方案实现简单,但有明显缺陷:模型看不到完整对话上下文,句子之间的停顿和情绪衔接很容易断掉。另一类方案会一次性输入完整对话文本,然后输出整段多说话人音频。它能建模全局上下文,但不适合编辑,也不适合实时交互,因为必须等整段生成完才能处理后续音频。
FireRedTTS-2 选择的是中间路线:输入格式里保留历史文本和历史语音,让模型理解上下文;生成方式上支持逐句输出,让系统可以一边生成一边播放,也方便修改某一句话。
flowchart LR
A[对话文本与说话人标签] --> B[文本-语音混排序列]
C[说话人参考音频] --> D[离散语音编码器]
D --> E[说话人语音 token / 条件信息]
B --> F[文本语音合成模型]
E --> F
F --> G[生成离散语音 token]
G --> H[语音编码器的流式解码器]
H --> I[连续音频流]
这条链路里,TTS 模型并不直接预测波形,而是预测离散语音 token。真正把 token 还原成音频的工作由语音编码器的解码端完成。
总体架构:语音编码器 + 文本语音合成模型
FireRedTTS-2 的系统结构由两个核心模块组成:离散语音编码器和文本语音合成模型。
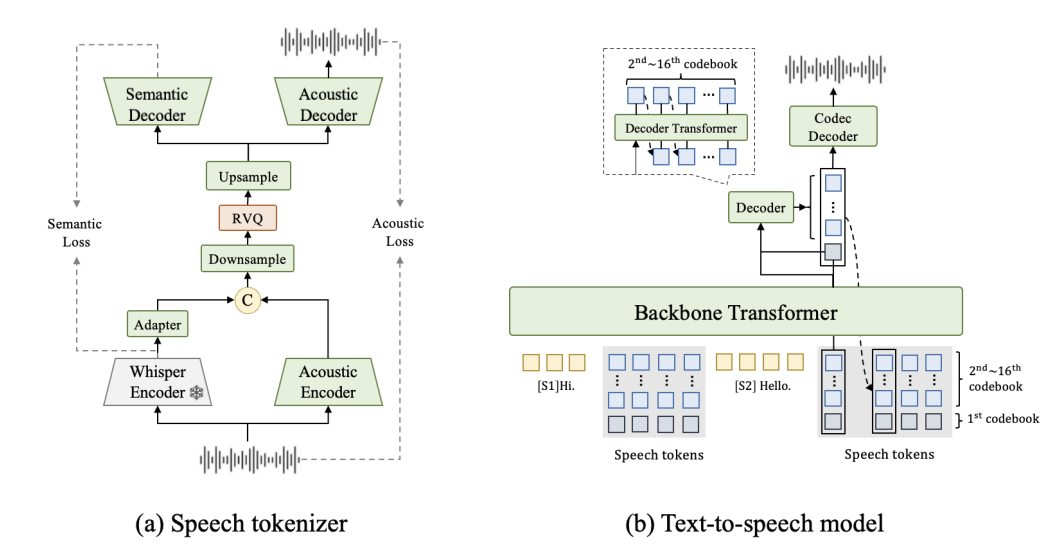
结构图里可以看到两条主线:训练阶段先把真实语音压缩成离散 token,供 TTS 模型学习;推理阶段由 TTS 模型生成语音 token,再通过语音解码器把 token 还原成连续音频。这个设计的关键是把复杂的波形建模问题,转成更适合 Transformer 处理的离散序列建模问题。
离散语音编码器:把语音压缩到 12.5Hz
离散语音编码器(Speech Tokenizer)的作用,是把连续语音信号转换成离散标签序列。可以把它理解成语音领域的 tokenizer:文本大模型处理的是文字 token,语音生成模型处理的则是语音 token。
FireRedTTS-2 的语音编码器输出帧率是 12.5Hz,也就是 1 秒语音大约只对应 12.5 个离散标签。低帧率带来两个直接好处:
| 设计 | 作用 |
|---|---|
| 12.5Hz 低帧率 | 缩短语音 token 序列,降低长对话建模成本 |
| 语义监督 | 让离散标签包含更强的语义信息,而不是只记录声学细节 |
| 流式解码 | 生成一部分 token 后即可开始还原音频,降低起播等待时间 |
| 多阶段训练 | 先保证泛化,再用高质量语音优化重建音质 |
为什么低帧率重要?假设一个语音 tokenizer 每秒输出 50 个 token,10 分钟对话就有 30000 个 token;如果降到 12.5Hz,同样时长只有 7500 个 token。序列越短,Transformer 的建模压力越小,长对话里的上下文利用也更现实。
不过,帧率低并不等于可以丢掉关键信息。FireRedTTS-2 在训练编码器时引入预训练语音模型提取的语义特征,并对离散标签做语义监督,使 token 不只是保存音高、能量、频谱等声学信息,也能携带更接近“说了什么”的语义信息。这样 TTS 模型从文本预测语音 token 时,学习目标会更清晰。
训练策略分成两步:
- 在约 50 万小时多样化语音数据上训练,提升对不同说话人、语种、录音条件的泛化能力;
- 在约 6 万小时高质量语音上继续训练,重点优化重建音质。
推理时,语音 token 不需要等整句全部生成完再解码。流式解码器可以逐步输出音频,因此 FireRedTTS-2 更容易接入实时语音交互、边播边生成的播客系统等场景。
文本-语音混排:逐句生成还能保留上下文
多说话人对话合成需要明确“谁在说哪句话”。FireRedTTS-2 使用文本-语音混排格式,把说话人标签、文本、历史语音 token 放在同一个序列里建模。
抽象后的输入格式类似这样:
[S1] 你今天想聊什么?
<AUDIO_TOKENS_OF_S1>
[S2] 我想聊聊最近的 AI 播客生成。
<AUDIO_TOKENS_OF_S2>
[S1] 那我们可以从多说话人语音合成讲起。
<AUDIO_TOKENS_TO_GENERATE>
其中 [S1]、[S2] 是说话人标签,后面的文本告诉模型当前要说什么,历史音频 token 提供上下文和角色信息。模型生成当前句子的语音 token 后,可以继续追加到上下文里,再生成下一句。
这种格式比“逐句独立合成”多了一份上下文记忆,也比“整段一次性生成”更灵活。某一句话要修改时,不需要重做整段;实时交互时,也不必等用户输入完整剧本。
sequenceDiagram
participant U as 上层应用
participant T as FireRedTTS-2
participant D as 语音解码器
participant P as 播放端
U->>T: 输入 [S1] 当前句文本 + 历史上下文
T-->>D: 逐步生成语音 token
D-->>P: 流式输出音频片段
U->>T: 输入 [S2] 下一句文本 + 更新后的上下文
T-->>D: 逐步生成语音 token
D-->>P: 继续播放
逐句生成的难点在于:模型不能只看当前句,否则对话会像拼起来的单句音频;也不能完全依赖历史音频,否则计算量和延迟都会上升。FireRedTTS-2 通过混排序列和双 Transformer 架构来平衡这两个目标。
双 Transformer:粗粒度语音 + 声学细节分开建模
FireRedTTS-2 的文本语音合成模型包含两个 Transformer:
| 模块 | 参数规模 | 主要职责 |
|---|---|---|
| Backbone Transformer | 1.5B | 建模混排序列中的粗粒度语音信息,理解文本、说话人和上下文 |
| Decoder Transformer | 0.2B | 补充声学细节,让输出语音更自然、更稳定 |
Backbone Transformer 负责决定“这句话应该怎么说”:包括文本内容、说话人身份、句子在对话中的位置、前后句衔接方式等。Decoder Transformer 更关注“具体声音细节”:比如音色细节、局部声学变化、语音自然度。
常见的 Delay Pattern 方法通常通过错位预测多个 codebook 来生成语音 token,但上下文里的文本与历史语音利用不够充分。FireRedTTS-2 的双 Transformer 设计把上下文建模和声学细节建模拆开,让模型既能保持对话连贯性,又能降低首包延迟。配合 12.5Hz tokenizer 的流式解码,系统可以更快输出第一段可播放音频。
训练同样分成两个阶段:
| 阶段 | 数据规模 | 目标 |
|---|---|---|
| 单句语音预训练 | 约 110 万小时 | 建立稳定的文本到语音能力 |
| 对话语音继续训练 | 约 30 万小时 | 学习 2 到 4 人对话中的说话人切换、上下文韵律和对话节奏 |
单句预训练让模型先学会“把文字说对”;对话继续训练让模型再学会“在多人对话里说得连贯”。这两个能力缺一不可。只做单句训练,多人对话容易断裂;只做对话训练,基础发音和覆盖面又不够稳。
音色克隆与随机音色生成
FireRedTTS-2 支持两类常见用法。
一种是音色克隆:给每个发音人提供一句参考语音,模型就可以在后续对话中模仿对应音色和说话习惯。抽象输入可以表示为:
# 伪代码:表示输入组织方式,不是具体 API
speaker_refs = {
"S1": "speaker_1_reference.wav",
"S2": "speaker_2_reference.wav",
}
dialogue = [
("S1", "欢迎来到今天的节目。"),
("S2", "今天我们聊聊多说话人语音合成。"),
("S1", "这个任务最难的是角色稳定和韵律连续。"),
]
另一种是随机音色生成:不指定真实说话人的参考音频,由模型生成不同风格的音色。这个能力适合批量生产训练数据,比如给语音识别、多轮对话、跨语言语音理解等任务构造多音色、多语种样本。
已覆盖的语种包括中文、英语、日语、韩语、法语等。跨语言合成对文本规范化要求更高,例如数字、缩写、人名、外来词都可能影响读法。在实际系统里,TTS 前通常还要接一层文本归一化和分句模块,避免模型直接面对格式混乱的输入。
评测指标:不只听自然度,还要看说话人是否稳定
对话合成不能只用“听起来像不像真人”来评价。FireRedTTS-2 和 MoonCast、ZipVoice-Dialogue、MOSS-TTSD 等系统在中英文对话测试集上做了对比,评测分为客观指标和主观偏好两类。
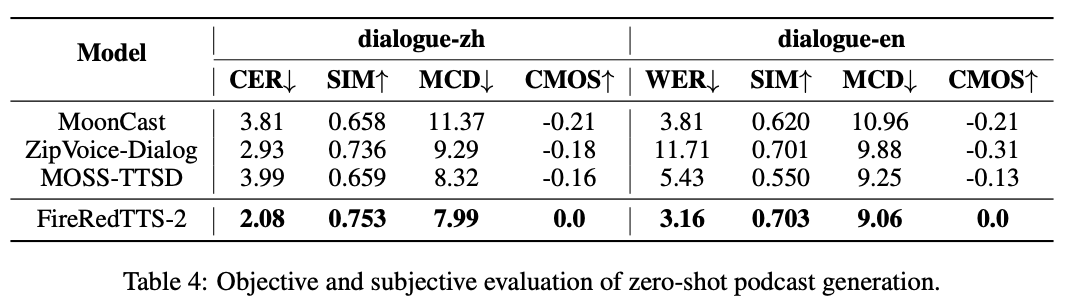
评测结果图汇总了不同系统在发音正确性、说话人保持、声学距离和主观偏好上的表现。几个指标分别对应不同问题:
| 指标 | 全称 / 含义 | 越高越好还是越低越好 | 关注点 |
|---|---|---|---|
| CER | Character Error Rate,字符错误率 | 越低越好 | 中文发音和内容正确性 |
| WER | Word Error Rate,词错误率 | 越低越好 | 英文发音和内容正确性 |
| SIM | Speaker Similarity,说话人相似度 | 越高越好 | 合成语音是否保持目标说话人身份 |
| MCD | Mel-Cepstral Distortion,梅尔倒谱失真 | 越低越好 | 合成语音和真实语音的声学差异 |
| CMOS | Comparative Mean Opinion Score,对比平均意见分 | 越高越好 | 人耳主观偏好和自然度 |
这些指标覆盖了多说话人对话合成的主要风险:CER/WER 高说明内容容易说错;SIM 低说明角色声音不稳定;MCD 高说明声学质量离真实录音更远;CMOS 低说明人耳不喜欢或者觉得不自然。
从对比结果看,FireRedTTS-2 在这些主客观指标上都处于更优位置,说明它不仅减少了读错内容的问题,也改善了说话人切换和对话韵律。
小数据微调:50 小时特定播客录音能带来什么
通用模型可以覆盖大量音色和语种,但如果目标是做固定角色的播客,通常还需要更贴近目标节目风格的音色定制。FireRedTTS-2 支持用少量特定说话人数据微调。
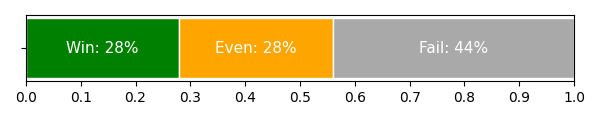
在约 50 小时特定播客说话人录音上微调后,测试结果显示 CER 为 1.66%。主观听评里,28% 的样本被认为比真实播客录音更自然,另有 28% 的样本难以区分合成语音和真实录音。合并来看,56% 的样本在自然度上达到或超过真实录音。
这个结果说明,通用 TTS 模型加少量领域数据微调,可以把“能合成”推进到“接近目标节目听感”。不过,50 小时并不等于没有成本:录音质量、说话人稳定性、标注准确性、文本清洗都会影响微调效果。如果数据里有大量噪声、抢话、背景音乐或转写错误,模型会把这些问题一起学进去。
和其他对话合成路线的对比
FireRedTTS-2 的设计重点不只是音质,而是把可编辑性、上下文一致性和实时性放在同一套框架里处理。
| 路线 | 做法 | 优点 | 主要问题 |
|---|---|---|---|
| 单句合成再拼接 | 每句话独立 TTS,最后拼音频 | 实现简单,易于替换某一句 | 句间韵律断裂,说话人上下文弱 |
| 整段一次性生成 | 输入完整对话,输出完整音频 | 能建模全局上下文 | 不利于编辑,实时交互困难 |
| 文本-语音混排逐句生成 | 历史文本/语音与当前句一起建模 | 兼顾上下文、编辑和流式播放 | 需要设计稳定的说话人标签和上下文管理 |
FireRedTTS-2 适合的场景比较明确:
| 适合场景 | 原因 |
|---|---|
| AI 播客生成 | 需要多人角色、长对话韵律、音色保持 |
| 语音助手多轮交互 | 逐句生成和低首包延迟更重要 |
| 多语种语音数据合成 | 随机音色和多语言覆盖能提高数据多样性 |
| 固定角色音色定制 | 少量数据微调可以贴近目标说话人风格 |
| 有声内容生产 | 方便按句修改、替换和重生成 |
不适合的场景也要提前识别:
| 不适合场景 | 原因 |
|---|---|
| 未经授权的真人音色复制 | 音色克隆需要明确授权和合规边界 |
| 需要精确控制每个音素时长的场景 | 生成式模型的细粒度可控性有限 |
| 强背景音乐、音效混合生成 | 可控音效插入并不是当前核心能力 |
| 无限说话人长对话 | 说话人数量和上下文长度仍会受到模型上下文窗口限制 |
工程落地时容易踩的坑
1. 说话人标签必须稳定
同一个角色在整段对话里要始终使用同一个标签,例如 [S1] 不要中途改成 [SpeakerA]。标签混乱会直接增加说话人错位的概率。
2. 文本清洗会影响发音错误率
数字、日期、英文缩写、特殊符号、人名地名都要尽量规范化。比如“2026/06/07”应该根据语境转换成自然读法,而不是直接把符号交给模型猜。
3. 长对话要管理上下文长度
历史语音 token 能帮助模型保持对话连贯,但上下文无限增长会带来计算压力。实际系统可以保留最近几轮对话、关键说话人参考片段和必要文本摘要,而不是把所有历史都塞进去。
4. 流式播放要处理句尾边界
逐句生成不等于每句话之间机械拼接。播放端需要处理句尾停顿、缓冲长度和下一句起播时机,否则模型本身生成得自然,最终听感也可能被播放器破坏。
5. 音色克隆必须有权限控制
只要系统支持参考音频克隆,就需要加入授权校验、使用范围限制、水印或溯源机制。技术上能模仿一个声音,不代表业务上可以随意使用。
关键设计可以浓缩成三句话
FireRedTTS-2 用 12.5Hz 低帧率语音 tokenizer 缩短语音序列,并通过语义监督让 token 更适合文本到语音建模。文本语音合成模型采用混排格式和双 Transformer 架构,在逐句生成的同时利用历史上下文。评测结果显示,它在发音正确性、说话人保持、声学质量和主观自然度上都优于 MoonCast、ZipVoice-Dialogue、MOSS-TTSD 等对话合成系统。
相关技术资源: