DeepSeek-V4 的核心目标不是单纯把参数量做大,而是让大模型在 1M token 上下文下仍然能训练、能推理、能部署。
公开参数里有两个版本:
| 模型 | 总参数量 | 稀疏激活参数 | 默认上下文 |
|---|---|---|---|
| DeepSeek-V4-Pro | 1.6T | 49B | 1M token |
| DeepSeek-V4-Flash | 284B | 13B | 1M token |
Flash 不是 Pro 的蒸馏版本,而是独立预训练的 MoE(Mixture of Experts,混合专家)模型。两个版本都默认支持 1M 上下文,不再把长上下文作为单独开关或特殊模型来处理。
公开评测可以先帮助定位 DeepSeek-V4 的整体能力:
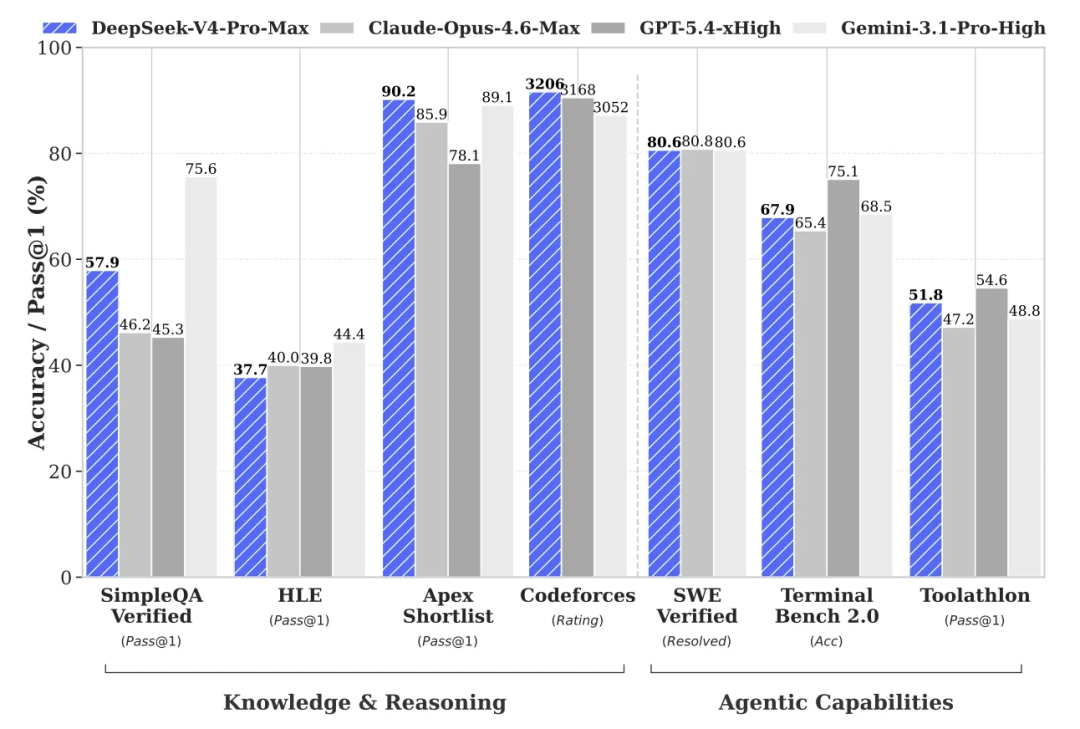
图里的重点不只是分数接近闭源第一梯队,而是几个方向同时靠前:代码、数学、Agent、长文本推理。这些能力背后的共同要求是长程依赖建模。模型不能只记住最近几千个 token,而要在几十万甚至上百万 token 里找到真正相关的信息。
1M 上下文到底解决什么问题
很多普通聊天任务不需要百万级上下文,几千到几万 token 已经够用。但 Agent、整仓代码分析、长文档推理不是普通聊天,它们会不断把工具调用、文件内容、执行结果和中间推理塞进上下文。
| 场景 | 为什么会消耗大量 token | 1M 上下文的价值 |
|---|---|---|
| Coding Agent 多轮任务 | 每轮包含用户指令、源码片段、shell 输出、错误日志、修改记录、推理轨迹 | 不必频繁丢弃历史状态,模型能保留任务连续性 |
| 整仓库代码理解 | 中型项目可能有几百个文件、十几万行代码,token 化后接近百万级 | 跨文件重构、调用链检查、类型推导不依赖局部检索命中 |
| 法律、财报、论文长文档 | 单份材料可能达到几十万 token,多附件合并后更长 | 可以直接在完整材料上做跨章节推理,减少切块摘要造成的信息损失 |
RAG(Retrieval-Augmented Generation,检索增强生成)仍然有价值,但它适合“相关片段可以被检索出来”的任务。代码重构和长文档审查经常需要全局一致性:漏掉一个调用点、一个例外条款、一个跨章节定义,结果就可能出错。1M 上下文的意义在于让模型有机会直接看到全局材料。
标准 Transformer 为什么撑不住 1M 上下文
标准 Transformer 的瓶颈主要出现在三个地方。
flowchart TD
A[1M token 上下文] --> B[Prefill 阶段注意力计算]
A --> C[Decode 阶段 KV Cache]
A --> D[更深更宽的模型]
B --> B1[复杂度 O(L²)]
C --> C1[显存与带宽随 L 线性增长]
D --> D1[残差通路稳定性变差]
Prefill 阶段会一次性处理整段输入,标准注意力需要计算每一对 token 的关系,复杂度是:
[
O(L^2)
]
当上下文长度从 128K 增加到 1M,长度大约变成 8 倍,注意力计算量会增加到 64 倍。
Decode 阶段每生成一个 token,都要读取历史 token 对应的 KV Cache(Key-Value Cache,键值缓存)。上下文越长,需要搬运的 KV 越多,HBM(High Bandwidth Memory,高带宽显存)带宽压力越大。
模型本身也会变得更深、更宽。长程推理需要更强表达能力,但层数增加后,传统残差连接会出现信息混杂、层贡献不可控、训练不稳定等问题。
DeepSeek-V4 的架构可以按三条主线理解:
| 问题 | DeepSeek-V4 的方案 | 解决重点 |
|---|---|---|
| 深层网络残差通路不稳定 | mHC(Manifold-Constrained Hyper-Connections,多流约束超连接) | 多条残差流 + 受约束的层间路由 |
| 1M 上下文注意力算不动、存不下 | CSA/HCA 混合稀疏注意力 | 压缩、粗筛、精筛、稀疏精算 |
| 万亿参数训练震荡、收敛难 | Muon 优化器 + Q/K RMSNorm | 梯度更新更稳定,避免 attention logits 爆炸 |
mHC:把单条残差通路改成可控的多流通路
标准残差连接的形式很简单:
[
h_{l+1}=h_l+F_l(h_l)
]
其中 (h_l) 是第 (l) 层输入,(F_l) 可以是 attention 或 FFN(Feed Forward Network,前馈网络)模块。把它逐层展开,可以得到:
[
h_l=v_0+\sum_{i=0}^{l-1}v_i
]
这意味着深层输入可以看成所有历史层变换结果的累加。这个形式非常简洁,但它有一个隐含问题:所有历史层都沿着同一条残差通路往后传,而且默认等权进入后续层。
在浅层模型里,这种设计足够好;在百层以上、万亿参数规模的大模型里,它会变得僵硬:
| 问题 | 标准残差的表现 |
|---|---|
| 容量瓶颈 | 浅层语义、深层抽象都挤在同一条通路里 |
| 路由僵硬 | 每层无法主动决定“更需要哪些历史层的信息” |
| 稳定性风险 | 多层累加可能带来激活爆炸或梯度异常 |
三种残差机制的演进关系可以用这张结构图对齐:
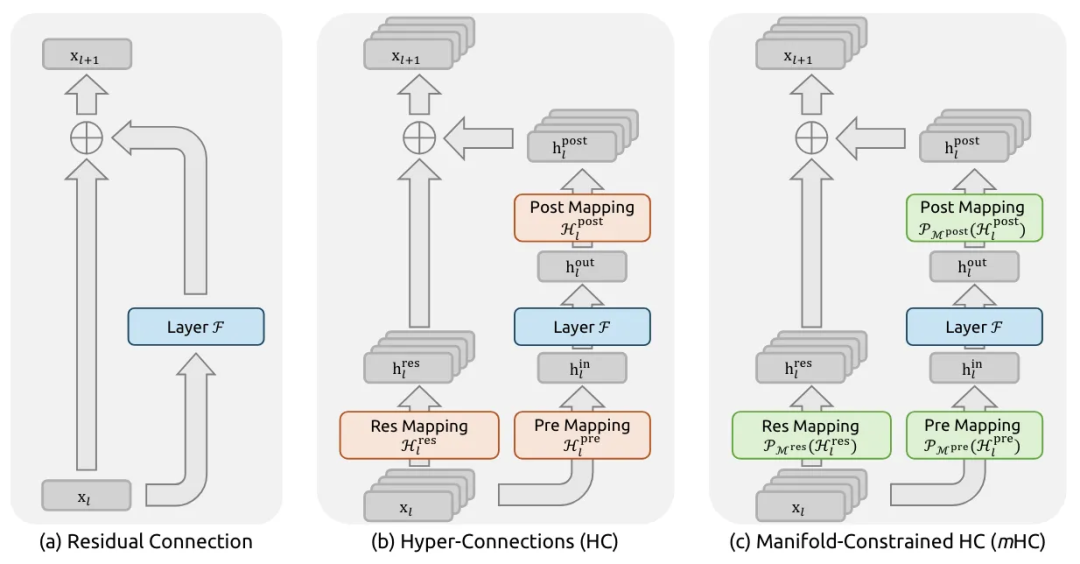
图中可以看到,标准残差只有单流直传;HC(Hyper-Connections,超连接)引入多条流,并通过 pre/res/post 三类映射做层间调度;mHC 保留多流结构,但给关键映射增加约束,避免多层矩阵连乘后数值失控。
从 HC 到 mHC:为什么要约束残差映射矩阵
HC 的基本思路是维护 (n) 条残差流。每一层变换前,先用 (H_{pre}) 把多条流降到一条流;经过 attention 或 FFN 后,再用 (H_{post}) 升回多条流;同时用 (H_{res}) 控制残差流之间如何混合。
可以把它理解成:
flowchart LR
A[多条残差流] --> B[H_pre 降流]
B --> C[Attention / FFN]
C --> D[H_post 升流]
A --> E[H_res 残差流混合]
D --> F[下一层多条残差流]
E --> F
问题在于,(H_{res}) 会跨层反复连乘。只要它没有约束,层数一深,连乘结果可能快速放大或衰减,从而引起梯度爆炸或梯度消失。
mHC 的关键设计是非对称约束:
| 矩阵 | 作用 | 约束方式 | 原因 |
|---|---|---|---|
| (H_{res}) | 控制残差流跨层混合 | 限制为双随机矩阵 | 会跨层连乘,风险最高 |
| (H_{pre}) | 变换前降流 | sigmoid 限制到 ((0,1)) | 只作用于当前层 |
| (H_{post}) | 变换后升流 | sigmoid 限制到 ((0,1)) | 只作用于当前层 |
双随机矩阵满足三个条件:
[
H_{res}\ge 0
]
[
\sum_j H_{res}[i,j]=1
]
[
\sum_i H_{res}[i,j]=1
]
也就是元素非负,每一行之和为 1,每一列之和也为 1。双随机矩阵有一个很重要的性质:两个双随机矩阵相乘,结果仍然是双随机矩阵。这样一来,即使 (H_{res}) 跨很多层连乘,系数也不会无限放大或坍缩到不可用范围。
mHC 的收益可以概括为两点:
- 多条残差流提供更多函数表示路径,缓解单通路容量瓶颈。
- 双随机约束让跨层路由保持稳定,降低深层训练风险。
同类思路也出现在注意力残差机制里。比如 Attn-Res 会让当前层通过注意力方式回看历史层,给不同历史层分配不同权重;Block Attn-Res 则把层分块,降低全历史回看的开销。mHC 和这些方案解决的是同一个大问题:深层网络里,历史层贡献不应该永远等权相加。
CSA/HCA:为 1M 上下文设计的混合稀疏注意力
标准注意力会让每个 token 和所有历史 token 建立联系。这个设计表达能力强,但在 1M 上下文里代价太高。
DeepSeek-V4 采用 Hybrid Attention,也就是由 CSA 和 HCA 组成的混合稀疏注意力。
- CSA(Compressed Sparse Attention,压缩稀疏注意力):把 token 分组压缩,再通过索引选择少量相关压缩块做精确注意力。
- HCA(Heavily Compressed Attention,高度压缩注意力):用更大的粒度压缩上下文,负责快速定位大范围相关区域。
整体流程可以看成三层筛选:
flowchart TD
A[1M token 上下文] --> B[HCA 大粒度压缩]
B --> C[定位相关大块]
C --> D[CSA 小粒度压缩与索引]
D --> E[选择 top-k 相关压缩块]
E --> F[共享 KV 的注意力计算]
F --> G[输出当前 token 表示]
CSA:先压缩,再索引,再精算
CSA 的结构图如下:
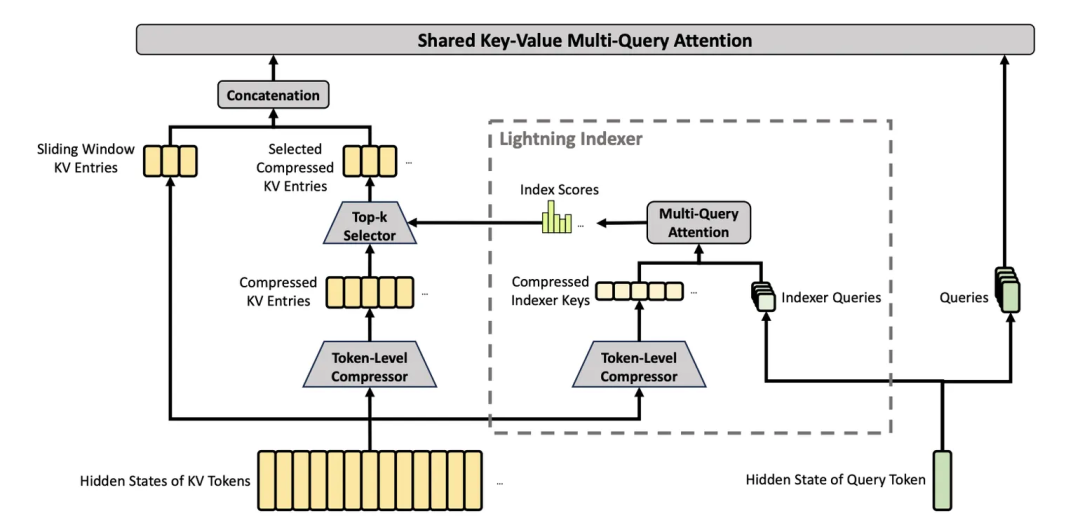
图中的流程可以拆成三步:左侧把原始 token 按组压缩,中间用轻量索引找到相关压缩块,右侧只对选中的压缩 KV 做 attention。它不是完全丢弃标准注意力,而是把“全量两两计算”改成“压缩后筛选,再对少量候选做精确计算”。
CSA 的压缩方式有两个细节。
一个组包含 (m) 个 token。压缩时不是简单平均,而是学习一个权重矩阵,让组内不同 token、不同维度有不同贡献。某个 token 在时间信息上更重要,就让它在相关维度占更高权重;另一个 token 在实体信息上更重要,也能被保留下来。
另外,CSA 会把相邻两组的压缩结果拼接在一起。这样做是为了减少切块边界造成的语义断裂。除了序列末尾,每个组都会被两个压缩表示覆盖。
索引阶段会快速计算当前 query 和所有压缩块的相关度,然后选出 top-k 压缩块。真正进入 attention 计算的只有这些候选块,所以复杂度和 KV Cache 压力都会下降。
HCA:用更大粒度做粗筛
HCA 的结构图如下:
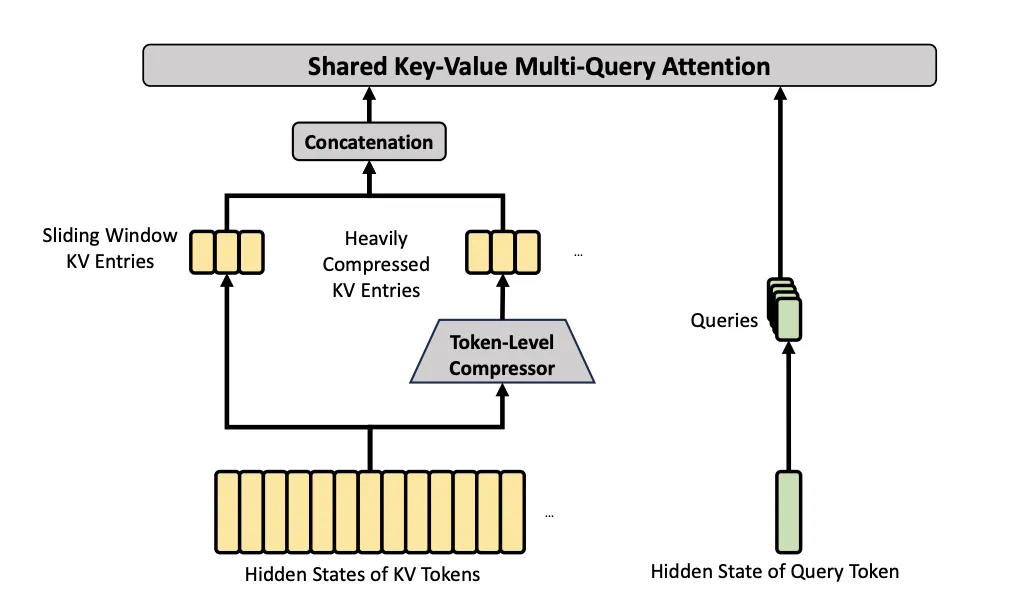
HCA 和 CSA 都会做加权压缩,但 HCA 的组更大,记作 (m'),并且 (m'\gg m)。它不再拼接相邻组,而是把一大段 token 压成一个表示。由于压缩粒度更粗,压缩块数量更少,可以直接在较少的压缩表示上做注意力或相关度判断。
CSA 和 HCA 的区别可以放在一张表里:
| 机制 | 压缩粒度 | 是否拼接相邻组 | 是否需要 top-k 索引 | 主要作用 |
|---|---|---|---|---|
| CSA | 小组,(m) 个 token | 是 | 是 | 精细选择相关上下文 |
| HCA | 大组,(m') 个 token | 否 | 通常不需要同等复杂索引 | 快速定位大范围区域 |
在 1M 上下文里,HCA 更像“海选”,CSA 更像“复筛”。HCA 先把可能相关的大块区域找出来,CSA 再在这些区域里做更细粒度选择,最终 attention 只处理少量高相关压缩 KV。
这种设计没有把长上下文问题完全交给检索系统,而是在模型内部完成压缩和稀疏选择。模型仍然能端到端学习“哪些上下文该被保留、哪些压缩块值得关注”。
Muon 与 Q/K RMSNorm:让超大模型训练更稳
长上下文和万亿参数会放大训练不稳定问题。DeepSeek-V4 在优化器和 attention 数值稳定性上做了两类处理。
Muon:把梯度更新方向正交化
Muon 优化器的核心动作是对梯度做正交化处理。直观理解,普通梯度更新可能在多个相关方向上互相干扰:一个方向刚把参数推过去,另一个相关方向又把它拉回来,训练就容易震荡。
正交化后,不同更新方向之间的耦合减少,参数更新更像沿着独立坐标轴前进。这样可以减少无效震荡,提高训练稳定性,同时加快收敛。
Q/K RMSNorm:在 softmax 前控制 logits
注意力分数来自:
[
QK^T
]
如果 Q 或 K 的某些维度数值过大,(QK^T) 里就会出现极端值。进入 softmax 后,注意力分布会变得过尖,少数 token 获得接近全部权重,其他 token 几乎没有贡献。这就是 logits 爆炸带来的问题。
DeepSeek-V4 在 attention 计算前对 Q、K 做 RMSNorm(Root Mean Square Normalization,均方根归一化),相当于先把参与点积的向量尺度拉回可控范围,再进入 softmax。它解决的是 attention 数值分布问题,不是简单调小学习率。
Infra 优化:让架构真的跑起来
架构创新只解决“模型怎么设计”,Infra 还要解决“硬件怎么高效执行”。DeepSeek-V4 的工程优化集中在 MoE 通信、算子开发、确定性、量化、训练框架和推理缓存几个方向。
MoE 计算通信重叠:把气泡压到更小
MoE 层通常包含三类动作:
sequenceDiagram
participant GPU as GPU 计算单元
participant NET as 通信网络
GPU->>NET: token 分发到专家
NET-->>GPU: 专家收到 token
GPU->>GPU: 专家矩阵计算
GPU->>NET: 专家结果回收
NET-->>GPU: 聚合输出
早期实现通常是“通信完再计算,计算完再通信”。这样会出现资源空闲:通信时计算单元等着,计算时通信链路等着。
更好的方式是计算通信重叠。DeepSeek-V4 进一步把调度粒度拆得更细,让矩阵计算和 token 分发/回收更紧密地交错执行。
三种调度方式的时间线对比如下:
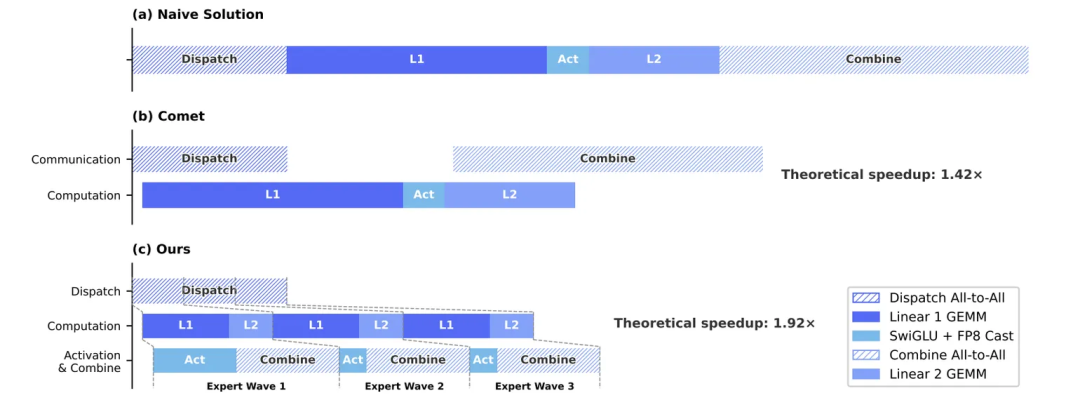
图中可以看到,粗粒度重叠仍然会留下空白气泡;细粒度重叠把计算块和通信块穿插得更密,硬件空闲时间更少。
这里有一个重要判断条件。设硬件计算能力为 (C),通信带宽为 (B),硬件的计算通信比是:
[
C/B
]
MoE 模块在模型和量化方案确定后,计算量 (V_{comp}) 与通信量 (V_{comm}) 的比例基本固定:
[
V_{comp}/V_{comm}
]
如果:
[
V_{comp}/V_{comm} > C/B
]
说明模块更偏算力密集,通信理论上可以被隐藏进计算里。也就是说,部署 MoE 不一定永远追求最高通信带宽,关键是让计算量和通信量匹配硬件比例。
TileLang:用 tile 抽象开发高性能 kernel
DeepSeek-V4 包含 mHC、CSA、HCA 等非标准结构,如果全部手写 CUDA kernel,开发和维护成本会非常高。
TileLang 的核心是面向 tile 的高层抽象。它把两件事拆开:
| 层次 | 负责内容 |
|---|---|
| 数据流逻辑 | 算子要算什么 |
| 调度策略 | tile 怎么切、线程怎么排、内存怎么搬 |
开发者用更高层的方式描述计算,编译器根据标注生成高性能 kernel。这样既能减少手写 CUDA 的复杂度,也更容易迁移到不同硬件后端,包括 NVIDIA GPU 和其他加速芯片。
Batch-Invariant:同一个 token 不应受 batch 切分影响
Batch-Invariant 可以翻译成批无关性,要求同一个 token 的输出不因为 batch 大小、batch 切分方式变化而发生 bit 级差异。
这个问题在大模型推理里很现实。同一条请求单独跑、和其他请求拼 batch 跑,如果输出 bit 不一致,就会影响缓存复用、结果复现和线上排查。
DeepSeek-V4 在 attention kernel 上对齐不同执行路径:无论单条序列由单个 SM(Streaming Multiprocessor,流式多处理器)处理,还是由多个 SM 协同处理,都保持同一条 query 的计算顺序一致。
矩阵乘法更麻烦。GEMM(General Matrix Multiplication,通用矩阵乘法)内部包含大量浮点累加,而浮点加法不满足结合律:
[
(a+b)+c \neq a+(b+c)
]
数学上等价的表达式,只要累加顺序不同,最后 bit 就可能不同。通用 cuBLAS 为了追求性能,可能在不同 batch 下选择不同切分路径。DeepSeek-V4 需要依赖 DeepGEMM 这类固定计算路径的矩阵乘法库,才能保证批无关。
Determinism:把多对一累加顺序固定住
计算确定性和批无关性相关,但不是同一个概念。
| 概念 | 关注点 |
|---|---|
| 批无关性 | batch 怎么切,单个 token 结果都一样 |
| 计算确定性 | 同一计算重复执行,结果 bit 级一致 |
attention 反向传播、MoE 反向传播、mHC split-k 归约都属于“多对一”累加场景。多个分支的梯度最终会汇聚到同一个 tensor 上,如果累加顺序变化,bit 就可能漂移。
DeepSeek-V4 的做法是允许执行并行,但固定最终加法括号结构。也就是说,任务可以乱序完成,但归约顺序必须固定。
FP4 量化感知训练:训练阶段就适应低精度
QAT(Quantization-Aware Training,量化感知训练)的思路是:不要等模型训练完再突然量化,而是在训练后期就让模型感知低精度数值扰动。这样部署时可以用低精度带来显存节省和推理加速,同时减少精度损失。
DeepSeek-V4 不是所有模块一刀切 FP4,而是按敏感度分模块处理:
| 模块 | 精度策略 | 原因 |
|---|---|---|
| MoE 专家权重 | FP4 | 参数量最大,显存收益最高 |
| CSA 闪电索引里的 q、K | FP4 | 长上下文热点路径,计算和存储压力大 |
| 闪电索引打分 | BF16 | top-k 排序对数值误差敏感 |
FP4 可以大幅压缩存储,但排序分数这类敏感位置不能过度压缩。否则 top-k 候选块选错,后续 attention 再精确也没用。
训练框架:让新结构和分布式训练兼容
DeepSeek-V4 的训练框架主要解决四类冲突。
| 冲突 | 问题 | 处理方式 |
|---|---|---|
| Muon 与参数切分冲突 | Muon 更新需要完整梯度,传统分布式会把参数切碎 | 重新设计参数分组和分配方式,减少跨机梯度通信 |
| mHC 增加流水线压力 | 多流残差会带来更多显存和通信 | 定制 kernel、选择性重算、调整流水线节奏 |
| 长文本压缩跨机器边界 | KV 压缩需要连续 token,但序列可能被切到多台机器 | 相邻机器交换边界 token,再重排压缩结果 |
| 显存和算力取舍太粗 | 传统 checkpoint 往往按层保存或重算 | 精细到 tensor 的自动重算策略 |
选择性重算的思路尤其重要。训练时保存所有中间结果会占用大量显存;完全不保存又会增加太多重复计算。DeepSeek-V4 把粒度从“整层”细化到“单个 tensor”,框架根据代价自动决定哪些值保存、哪些值需要时再算。
推理框架:异构 KV Cache 不能再套旧模板
传统 PagedAttention 通常假设每层 KV Cache 形状相对一致。但 DeepSeek-V4 的混合注意力打破了这个前提:
- CSA 有压缩 KV 和索引结构。
- HCA 有更大粒度的压缩 KV。
- SWA(Sliding Window Attention,滑动窗口注意力)保留局部未压缩缓存。
- 尾部 state 还有单独更新规则。
因此,KV Cache 必须按类型重新组织。
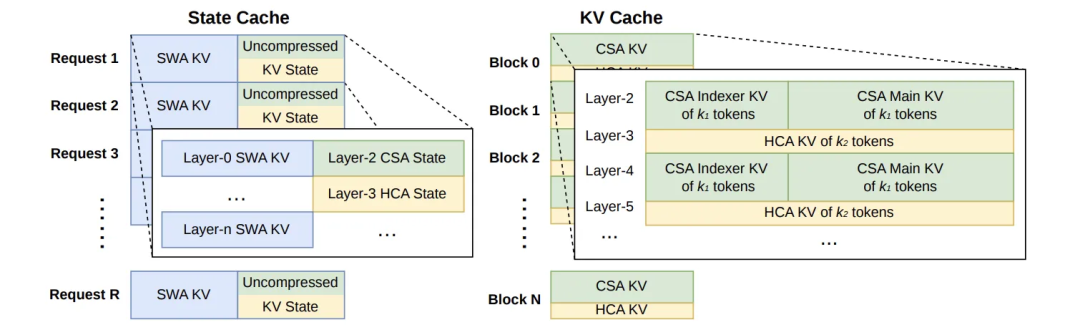
图中把不同注意力机制的缓存拆开管理:滑动窗口缓存负责近邻上下文,CSA/HCA 缓存负责压缩后的长程上下文,尾部状态处理最新 token 的增量更新。这样的设计可以避免把所有层强行塞进同一种 page 结构。
KV Cache 持久化也很关键。很多线上请求共享相同 system prompt、固定知识库文档或长上下文前缀,如果每次都重新 prefill,会浪费大量算力。更合理的方式是把已经计算好的 KV 写入磁盘或缓存系统,下次命中时直接加载。
DeepSeek-V4 的难点在于 KV 类型异构,不能简单把一整段 KV 当作统一 blob 存储。它需要把 CSA/HCA 压缩 KV、SWA 未压缩 KV、尾部 state 分开持久化,并分别设计命中、加载和更新策略。
哪些场景适合 1M 上下文模型
1M 上下文不是所有任务都需要。它适合全局信息真的会影响答案的场景。
| 任务 | 是否适合 | 原因 |
|---|---|---|
| 多轮 Coding Agent | 适合 | 工具调用、日志、文件修改历史需要长期保留 |
| 整仓代码重构 | 适合 | 调用链和类型关系跨文件分布,局部检索容易漏 |
| 法律合同审查 | 适合 | 条款引用、例外条件、附件说明可能相隔很远 |
| 长篇论文/财报分析 | 适合 | 需要跨章节对齐定义、数据和结论 |
| 普通闲聊 | 不太需要 | 上下文短,长窗口收益很低 |
| 单轮简单问答 | 不太需要 | 检索或短上下文已经足够 |
实际落地时,长上下文和 RAG 可以共存。高频短问题仍然适合 RAG;需要强全局一致性的任务,再把更多材料放进长上下文。否则 1M token 只会增加 prefill 成本,不一定带来更好结果。
DeepSeek-V4 的系统设计脉络
DeepSeek-V4 的关键不是某个单点技巧,而是把长上下文需要的能力串成一条完整链路:
flowchart LR
A[1M 上下文需求] --> B[mHC 稳定深层网络]
A --> C[CSA/HCA 降低注意力成本]
B --> D[Muon 与 Q/K RMSNorm 稳定训练]
C --> E[异构 KV Cache 支持推理]
D --> F[分布式训练框架适配]
E --> G[KV 持久化与低成本复用]
F --> H[FP4 QAT 降低部署成本]
G --> H
mHC 解决深层网络表达和稳定性;CSA/HCA 解决 1M 上下文 attention 的计算和存储;Muon、Q/K RMSNorm、确定性归约解决训练震荡和复现;TileLang、DeepGEMM、细粒度通信重叠和异构 KV Cache 则把这些结构落到硬件执行上。
百万上下文不是把窗口参数调大,而是从残差连接、注意力模式、优化器、kernel、分布式训练、量化和缓存系统一起重构。DeepSeek-V4 的技术路线说明了一件事:长上下文大模型已经从“能塞更多 token”进入“系统性处理百万级上下文”的阶段。