让大模型输出 JSON(JavaScript Object Notation)看起来很简单,只要在提示词里加一句:
请严格输出 JSON,不要输出任何解释,不要输出 Markdown。
手动测试时,这种写法经常有效。模型会返回一段看起来很规整的 JSON,复制出来也能解析。
问题会在接入真实系统后暴露出来。比如批量抽取简历、生成日报、整理会议纪要、把用户输入转换成数据库字段时,模型可能出现这些情况:
- JSON 前面多一句“好的,以下是结果”;
- 字段名从
action_items变成actions; - 本来应该是数组的字段变成了字符串;
- 多输出了后端不认识的字段;
- 少了必填字段;
- JSON 语法合法,但结构不符合业务要求。
根本问题不在于提示词写得不够“严格”,而在于提示词只是提醒,不能成为工程约束。要让模型稳定进入软件系统,需要把输出格式交给 Schema,而不是交给一句自然语言要求。
稳定格式不等于稳定内容
结构化输出解决的是格式可靠性,不是内容绝对正确。
假设用户反馈是:
我已经等了三天了,订单状态一直没有更新。客服每次都说帮我催一下,但没有任何结果。
如果今天还不处理,我就要退款了。
期望得到类似结构:
{
"sentiment": "negative",
"reason": "物流太慢",
"priority": "high"
}
真正需要稳定的是这些东西:
| 约束点 | 需要避免的问题 |
|---|---|
| 字段名固定 | sentiment 不能变成 emotion |
| 字段类型固定 | 数组不能变字符串,对象不能变列表 |
| 枚举值固定 | priority 只能是 low、medium、high |
| 必填字段不能丢 | 后端依赖的字段必须存在 |
| 不输出额外文本 | JSON 外不能包 Markdown 或解释说明 |
| 不输出多余字段 | 后端不认识的字段不要混进来 |
但 reason 里面写“物流慢”还是“订单处理时间过长”,仍然可能不同。结构化输出保证的是“像一份合格表单”,不是保证每个判断都百分百正确。
所以在工程上要拆成两层:
| 层级 | 负责什么 | 常用手段 |
|---|---|---|
| 格式层 | JSON 是否可解析、字段是否存在、类型是否正确、枚举是否合法 | JSON Schema、Structured Outputs、Function Calling、validator |
| 业务层 | 判断是否准确、事实是否可靠、是否满足业务规则 | 规则校验、数据库约束、重试、人工审核、失败队列 |
不要指望一个提示词同时负责格式约束和业务正确性。
为什么只靠提示词不稳定
大模型生成文本时,本质上是在不断预测下一个 token。你写“只输出 JSON”,模型会尽量遵守,但它并不会天然理解后端马上要执行 json.loads(),也不会因为提示词里出现“严格”两个字就变成数据库接口。
提示词更像口头要求:
这份表格一定按模板填。
Schema 更像受控表单:
只能填这些字段,每个字段只能填允许的值。
前者靠模型配合,后者靠机制约束。
提示词和 Schema 的差别可以用这张图概括:

图里的关键区别是:提示词只能影响模型“倾向于”怎么回答,而 Schema 会参与输出结构的定义。接入 API(Application Programming Interface,应用程序编程接口)后,系统可以根据 Schema 限制模型的输出空间,并在生成完成后得到可校验的数据。
在一些结构化输出实现里,还会用到 constrained decoding / constrained sampling(约束解码 / 约束采样)。它的思路是:生成过程中并不是所有 token 都能被选择,只有符合当前 Schema 状态的 token 才是合法候选。
flowchart LR
A[JSON Schema] --> C[生成状态]
B[已生成的 JSON 前缀] --> C
C --> D[计算合法的下一个 token]
D --> E[模型只在合法集合中选择]
E --> F[追加 token]
F --> C
F --> G[完成符合 Schema 的 JSON]
这类机制把“请你按格式来”变成了“你只能在合法格式里选择”。
JSON Schema 是什么
JSON Schema 可以理解成 JSON 数据的结构说明书。它用声明式方式规定:
- 顶层是对象还是数组;
- 对象里有哪些字段;
- 哪些字段必填;
- 每个字段是什么类型;
- 字段是否只能从枚举值中选择;
- 是否允许额外字段;
- 字符串长度、数组长度、数字范围等限制。
例如,要把用户反馈转换成固定结构,可以定义这样的 Schema:
{
"type": "object",
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "neutral", "negative"]
},
"summary": {
"type": "string"
},
"priority": {
"type": "string",
"enum": ["low", "medium", "high"]
},
"action_items": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["sentiment", "summary", "priority", "action_items"],
"additionalProperties": false
}
这份 Schema 表达了几条明确规则:
sentiment只能是positive、neutral、negative三选一;summary必须是字符串;priority只能是low、medium、high;action_items必须是字符串数组;- 四个字段都必须存在;
additionalProperties: false表示不允许模型额外添加字段。
additionalProperties: false 很关键。很多结构化输出事故不是字段少了,而是模型“主动帮忙”多加了字段。后端如果没有处理这些额外字段,就可能出现解析失败、数据污染或业务逻辑异常。
Structured Outputs 和 JSON mode 的区别
很多模型 API 都有 JSON mode(JSON 模式),但 JSON mode 和 Structured Outputs(结构化输出)不是一回事。
| 能力 | 保证合法 JSON | 保证符合指定字段结构 | 保证枚举值合法 | 控制额外字段 | 适合场景 |
|---|---|---|---|---|---|
| 普通提示词 | 不稳定 | 不稳定 | 不稳定 | 不稳定 | 手动试验 |
| JSON mode | 是 | 不一定 | 不一定 | 不一定 | 只要求返回 JSON 文本 |
| Structured Outputs | 是 | 是 | 是 | 可控制 | 接入业务系统、自动化流程 |
| Function Calling / Tool Calling | 是 | 是 | 是 | 可控制 | 让模型调用函数或工具 |
JSON mode 主要解决“返回内容是不是合法 JSON”。Structured Outputs 进一步解决“返回 JSON 是否符合你定义的 Schema”。
如果后续系统依赖字段名、字段类型、枚举值和必填字段,就不要只停留在 JSON mode。
用 Pydantic 定义结构化输出
在 Python 里,可以用 Pydantic 定义数据结构,再让支持结构化输出的模型 API 返回解析后的对象。
安装依赖:
pip install openai pydantic
定义一个用户反馈分析器:
from typing import Literal
from openai import OpenAI
from pydantic import BaseModel, Field
import json
client = OpenAI()
class FeedbackAnalysis(BaseModel):
sentiment: Literal["positive", "neutral", "negative"] = Field(
description="用户反馈的整体情绪"
)
summary: str = Field(
description="用一句话概括用户反馈"
)
priority: Literal["low", "medium", "high"] = Field(
description="处理优先级"
)
action_items: list[str] = Field(
description="建议后续处理动作"
)
raw_feedback = """
我已经等了三天了,订单状态一直没有更新。
客服每次都说帮我催一下,但没有任何结果。
如果今天还不处理,我就要退款了。
"""
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{
"role": "system",
"content": (
"你是一个客服反馈分析助手。"
"请把用户反馈转成结构化数据,不要扩展不存在的信息。"
)
},
{
"role": "user",
"content": raw_feedback
}
],
text_format=FeedbackAnalysis,
)
result = response.output_parsed
print(json.dumps(result.model_dump(), ensure_ascii=False, indent=2))
可能得到这样的结果:
{
"sentiment": "negative",
"summary": "用户因订单状态长期未更新且客服处理无结果而感到不满,并提出退款威胁。",
"priority": "high",
"action_items": [
"查询订单当前状态",
"升级给人工客服或物流专员处理",
"主动向用户反馈明确处理时间",
"必要时提供退款或补偿方案"
]
}
这段代码里最重要的不是 system prompt,而是这个类型定义:
class FeedbackAnalysis(BaseModel):
sentiment: Literal["positive", "neutral", "negative"]
summary: str
priority: Literal["low", "medium", "high"]
action_items: list[str]
它把模型的输出从“随便写一段回答”变成了“填写一个固定对象”。字段叫什么、类型是什么、哪些值能选,都在代码里定义清楚了。
不能使用 Structured Outputs 时,至少要校验
有些系统可能还在用旧接口、本地模型或开源模型,暂时没有 Structured Outputs 能力。这种情况下,仍然不应该让模型输出直接进入业务系统。
最低限度要做三件事:
- 让模型尽量输出 JSON;
- 用代码解析 JSON;
- 用 JSON Schema 校验结构。
Python 可以使用 jsonschema:
pip install jsonschema
校验脚本如下:
import json
from jsonschema import ValidationError, validate
FEEDBACK_SCHEMA = {
"type": "object",
"properties": {
"sentiment": {
"type": "string",
"enum": ["positive", "neutral", "negative"]
},
"summary": {
"type": "string"
},
"priority": {
"type": "string",
"enum": ["low", "medium", "high"]
},
"action_items": {
"type": "array",
"items": {"type": "string"}
}
},
"required": ["sentiment", "summary", "priority", "action_items"],
"additionalProperties": False
}
def parse_and_validate_json(raw_text: str) -> dict:
"""
解析并校验模型返回的 JSON。
不合格就抛错,避免脏数据进入后续系统。
"""
try:
data = json.loads(raw_text)
except json.JSONDecodeError as e:
raise ValueError(f"模型输出不是合法 JSON: {e}") from e
try:
validate(instance=data, schema=FEEDBACK_SCHEMA)
except ValidationError as e:
raise ValueError(f"模型输出不符合 Schema: {e.message}") from e
return data
if __name__ == "__main__":
model_output = """
{
"sentiment": "negative",
"summary": "用户对订单处理延迟不满",
"priority": "high",
"action_items": ["查询订单", "联系用户", "升级处理"]
}
"""
result = parse_and_validate_json(model_output)
print(result)
这层校验解决的是一个生产系统里非常现实的问题:模型 99 次输出正确,不代表第 100 次不会把数组写成字符串,或者多塞一个后端不认识的字段。
结构化输出流程可以拆成生成、解析、校验、重试、入库几个环节:
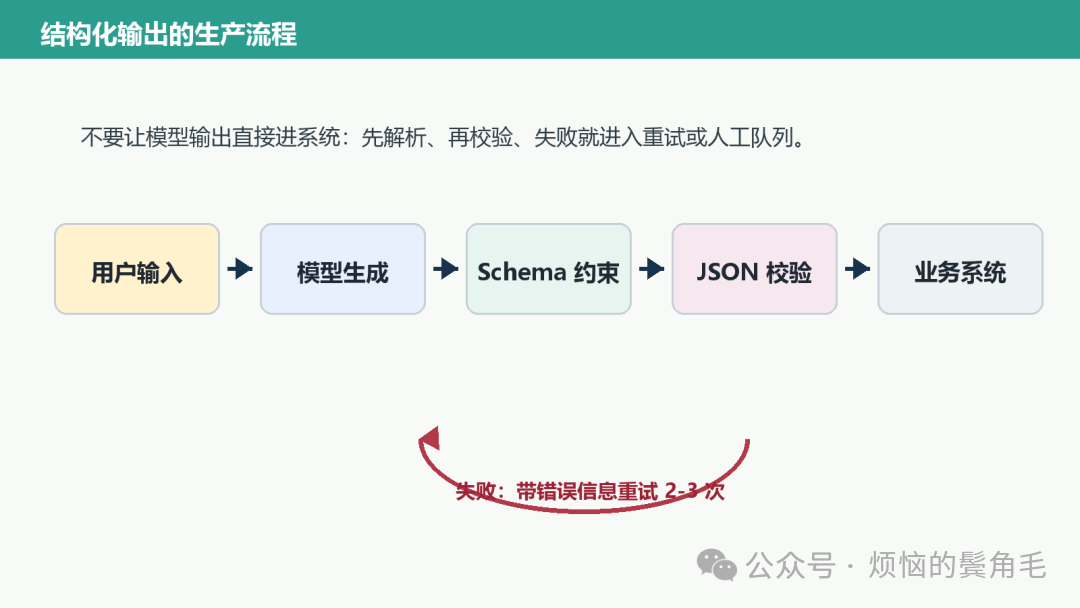
图里的重点是:模型输出不是流程终点。只有通过解析和校验的数据,才应该进入数据库、表格、任务系统或业务 API。失败的输出可以进入重试逻辑,多次失败后再放入人工处理或失败队列。
加上重试机制
生产环境不能默认“一次生成一定成功”。模型是一个可能犯错的组件,组件可能犯错,就需要错误处理。
常见流程是:
flowchart LR
A[输入文本] --> B[调用模型生成 JSON]
B --> C{解析 JSON}
C -- 失败 --> F[带错误信息重试]
C -- 成功 --> D{Schema 校验}
D -- 失败 --> F
D -- 成功 --> E[进入业务系统]
F --> G{超过最大重试次数?}
G -- 否 --> B
G -- 是 --> H[失败队列或人工处理]
可以写成伪代码:
import json
def ask_model(prompt: str) -> str:
"""
替换成实际的大模型调用。
返回模型原始文本。
"""
raise NotImplementedError
def generate_valid_json(base_prompt: str, max_retries: int = 3) -> dict:
prompt = base_prompt
for attempt in range(1, max_retries + 1):
raw_output = ask_model(prompt)
try:
return parse_and_validate_json(raw_output)
except ValueError as e:
prompt = f"""
你上一次输出的 JSON 不合格。
错误信息:
{str(e)}
请只修复 JSON,不要解释,不要输出 Markdown。
必须符合这个 Schema:
{json.dumps(FEEDBACK_SCHEMA, ensure_ascii=False, indent=2)}
原始输出:
{raw_output}
"""
raise RuntimeError("多次重试后,模型仍然没有输出合格 JSON")
重试提示词里要带上具体错误信息。比如“priority 不在枚举值中”比“格式错了”更容易让模型修复。
不过重试次数不能无限增加。超过 2 到 3 次仍然失败,通常说明输入太复杂、Schema 设计不合理,或者任务需要拆分。此时应该进入失败队列,而不是继续消耗模型调用成本。
Structured Outputs 和 Function Calling 怎么选
Structured Outputs 适合让模型返回一个固定结构的结果。Function Calling(函数调用)或 Tool Calling(工具调用)适合让模型决定是否执行某个动作。
| 需求 | 推荐方式 | 例子 |
|---|---|---|
| 抽取结构化信息 | Structured Outputs | 从简历中抽取姓名、技能、工作年限 |
| 生成固定 JSON | Structured Outputs | 把会议纪要整理成待办事项数组 |
| 分类与打标签 | Structured Outputs | 判断用户反馈情绪和优先级 |
| 查询外部数据 | Function Calling / Tool Calling | 调用搜索接口、查数据库 |
| 执行业务动作 | Function Calling / Tool Calling | 创建订单、发起退款、写入 CRM(客户关系管理)系统 |
| 多步骤 Agent 工作流 | Function Calling / Tool Calling + Structured Outputs | 先查资料,再生成结构化报告 |
判断标准很简单:
- 要模型“返回一个结果”,用 Structured Outputs;
- 要模型“调用你的系统做动作”,用 Function Calling / Tool Calling。
例如,把会议纪要整理成待办事项,这是结构化结果,适合 Structured Outputs。
但如果整理完之后还要自动创建飞书任务、Notion 页面或 Jira issue,那就涉及外部系统调用,应该把创建动作设计成工具函数,由模型通过 Function Calling / Tool Calling 发起。
Prompt 仍然重要,但不负责格式兜底
有了 Schema,不代表提示词没用了。Prompt 负责业务语义,Schema 负责输出结构。
Prompt 应该说明:
- 任务目标是什么;
- 哪些信息可以推断,哪些不能编造;
- 信息缺失时怎么处理;
- 摘要字段要多长;
- 分类标准是什么;
- 动作建议要具体到什么程度。
一个相对干净的 system prompt 可以这样写:
你是一个结构化信息抽取助手。
任务:
从用户提供的文本中抽取信息,并填入指定结构。
规则:
1. 不要编造文本中没有的信息。
2. 如果信息缺失,请使用空字符串、空数组或 Schema 中允许的默认值。
3. 分类字段必须严格按照 Schema 中的枚举值选择。
4. summary 字段控制在 50 字以内。
5. action_items 只写可执行动作,不写泛泛建议。
这个 prompt 没有把重点放在“请输出 JSON”。JSON 格式已经由 Schema 处理,prompt 只描述业务规则。这样的分工更清晰,也更适合维护。
设计 JSON 输出结构时的 7 条规则
1. 字段名要具体
不要写这种含糊字段:
{
"data": "...",
"result": "...",
"info": "..."
}
后端不知道字段含义,模型也容易填得很散。
更好的写法是:
{
"user_intent": "...",
"risk_level": "...",
"next_actions": []
}
字段名越贴近业务含义,模型越容易稳定填充,后端代码也更容易维护。
2. 能用枚举就用枚举
不要让模型自由发挥优先级:
{
"priority": "比较着急"
}
应该限制成固定值:
{
"priority": "high"
}
同时要在字段描述里写清楚判断标准,例如:
high:用户明确投诉、退款、流失风险或影响交易;medium:需要人工跟进,但没有紧急风险;low:普通咨询、低风险反馈。
3. 尽量禁止额外字段
如果后端不需要扩展字段,就设置:
{
"additionalProperties": false
}
这样可以避免模型输出类似 confidence、explanation、extra_notes 之类后端不认识的字段。
4. 复杂任务拆成多个小结构
不要让一个 JSON 同时承载用户画像、风险判断、营销建议、执行计划、邮件正文、SQL 条件。
结构越大,失败概率越高。可以拆成多步:
flowchart LR
A[用户输入] --> B[抽取事实]
B --> C[风险分类]
C --> D[生成处理动作]
D --> E[生成对外回复]
每一步只输出一个小 JSON,校验通过后再进入下一步。
5. 字段描述要写清楚
Schema 不只限制类型,也可以承载字段说明。尤其是分类字段,描述越明确,模型越不容易乱选。
例如:
priority: Literal["low", "medium", "high"] = Field(
description=(
"处理优先级。high 表示用户明确投诉、退款、流失风险或订单阻塞;"
"medium 表示需要人工跟进但没有紧急风险;"
"low 表示普通咨询或低风险反馈。"
)
)
6. 不要混合 Markdown 和 JSON
这样的输出对人友好,对程序不友好:
## 分析结果
```json
{
"summary": "用户对物流延迟不满"
}
```
接入系统时,最好只处理纯 JSON 或解析后的结构化对象。展示层需要 Markdown,可以在数据进入系统后再生成。
7. 永远保留校验层
即使用了 Structured Outputs,也建议在关键业务入口再做一层校验。Schema 能保证字段类型和结构,但不能保证业务事实一定准确。
例如:
- 模型可能把普通咨询误判为高风险投诉;
- 模型可能生成不符合内部政策的处理动作;
- 模型可能从模糊文本里过度推断用户意图。
业务校验可以包括关键词规则、数据库状态检查、权限判断、人工审核阈值等。
把模型输出当成接口设计
大模型一旦接入业务系统,它就不再只是聊天窗口,而是一个上游组件。组件之间传递的数据必须稳定、可解析、可校验。
可靠的结构化输出通常由几部分组成:
flowchart LR
A[业务输入] --> B[Prompt 描述任务]
B --> C[Schema 定义结构]
C --> D[模型生成]
D --> E[解析与 Schema 校验]
E --> F[业务规则校验]
F --> G{是否通过}
G -- 是 --> H[写入系统或触发后续流程]
G -- 否 --> I[重试、失败队列或人工审核]
这套分工可以概括为:
- 用 Prompt 说明任务;
- 用 Schema 定义结构;
- 用 API 约束输出;
- 用代码解析和校验;
- 用重试处理偶发错误;
- 用业务规则兜住内容质量。
稳定性不是来自模型“更听话”,而是来自工程约束。只要输出还是自由文本,模型更像聊天助手;当输出变成稳定 JSON,并且通过 Schema 和校验层进入系统,它才真正成为可以被后端、数据库、任务流和自动化平台消费的组件。