过去判断一张 AI(人工智能)图片,最常见的办法是看文字和界面细节:中文有没有错字,排版有没有穿帮,按钮和图标的位置是不是乱的,界面层级是否符合真实软件的习惯。
GPT Image 2 把这个判断方式变得不可靠了。它不只是能画出好看的图片,更重要的是开始能处理两类过去很容易露馅的内容:
- 复杂中文排版:试卷、报纸、海报、促销文案、漫画气泡、书法字形。
- 数字产品界面:直播间、游戏 HUD(抬头显示界面)、发布会直播、社交软件界面、电商广告页。
这意味着 AI 生图不再只是“画一张概念图”,而是越来越接近“生成一张带文字、带版式、带商业用途的视觉稿”。
GPT Image 2 解决了什么问题
AI 生图模型早期最明显的短板是文字。英文短词还能勉强处理,中文一旦进入多行、多字号、多字体、多区域排版,常见问题包括:
| 问题 | 典型表现 | 对商业使用的影响 |
|---|---|---|
| 中文乱码 | 汉字变成近似笔画,无法阅读 | 海报、广告、菜单、试卷不可用 |
| 错别字 | 字形看似正确,但内容被替换 | 需要大量人工修图 |
| 排版错乱 | 文字重叠、行距异常、标题和正文混在一起 | 很难直接交付 |
| UI(用户界面)不真实 | 按钮、图标、评论区、导航栏位置不符合真实产品 | 一眼能看出是生成图 |
| 世界知识不足 | 不知道真实软件、游戏、直播界面长什么样 | 只能画“像某类东西”,不能还原具体场景 |
GPT Image 2 的变化在于,它把“图像生成”和“文字理解、版式组织、场景知识”结合得更紧。输入一句简单提示词,它不只理解主体,还会尝试补全页面结构、字体风格、界面元素和图像质感。
可以把它的工作过程理解成下面这个流程:
flowchart LR
A[提示词] --> B[语义理解]
B --> C[场景知识匹配]
C --> D[构图与版式规划]
D --> E[文字渲染]
E --> F[图像细节生成]
F --> G[输出图片]
G --> H[人工检查与修改]
在这个流程里,最关键的不是最后一步“把图画出来”,而是前面的版式规划和文字渲染。如果模型不知道一张小学数学试卷应该有哪些区域,它就算能写字,也很难生成可信的试卷;如果模型不知道直播间 UI 的层级关系,它画出来的按钮、评论、点赞区就会乱。
中文渲染:从“能写几个字”到“能组织整页内容”
中文图片生成的难点不只是汉字数量多,还包括字体、行距、阅读顺序、标点习惯和版面结构。比如试卷、报纸、日历这类图像,文字不是装饰,而是画面的核心信息。
数学试卷测试
提示词很简单:
生成广州市小学数学试卷
生成结果保留了试卷常见结构:卷头、题号、填空线、数学符号、几何图形标注,以及类似真实试卷拍照的纸张质感。

这类结果说明 GPT Image 2 已经能把“试卷”拆成多个视觉模块,而不是随机堆文字。标题、题目、下划线和图形之间的关系比较稳定,整体看起来像一张真实纸质材料的照片。
但这类图片不能直接当作真实材料使用。试卷里的题目、数字、答案逻辑仍然需要检查,尤其是数学内容很容易出现“看起来像题目,但实际不严谨”的情况。
报纸与多栏排版测试
再看更复杂的图文排版。提示词如下:
一张泛黄的今日人工智能晚报,时间是 2049 年 4 月 21 日

报纸场景考验的是多栏布局、标题层级、日期、图片区域和正文密度。GPT Image 2 能生成带年代感的纸张质感,并把标题、日期、正文栏目组织在同一张图里。
这类能力对广告、运营、活动海报很有用,因为很多商业视觉不是单纯画图,而是要同时处理“图片 + 标题 + 卖点 + 时间 + 品牌信息”。
真实 UI 复刻:模型开始理解数字产品的视觉规律
GPT Image 2 的另一个变化,是对数字产品界面的理解变强了。过去让 AI 生成某个 App 场景,常见结果是“有手机界面的感觉”,但按钮、评论区、点赞区、顶部状态栏、信息流结构往往经不起细看。
直播间是一个很好的测试场景,因为它包含人物、背景、评论流、点赞按钮、分享入口、在线人数、礼物动效等多个层级。
提示词:
一个漂亮的美女主播在抖音直播
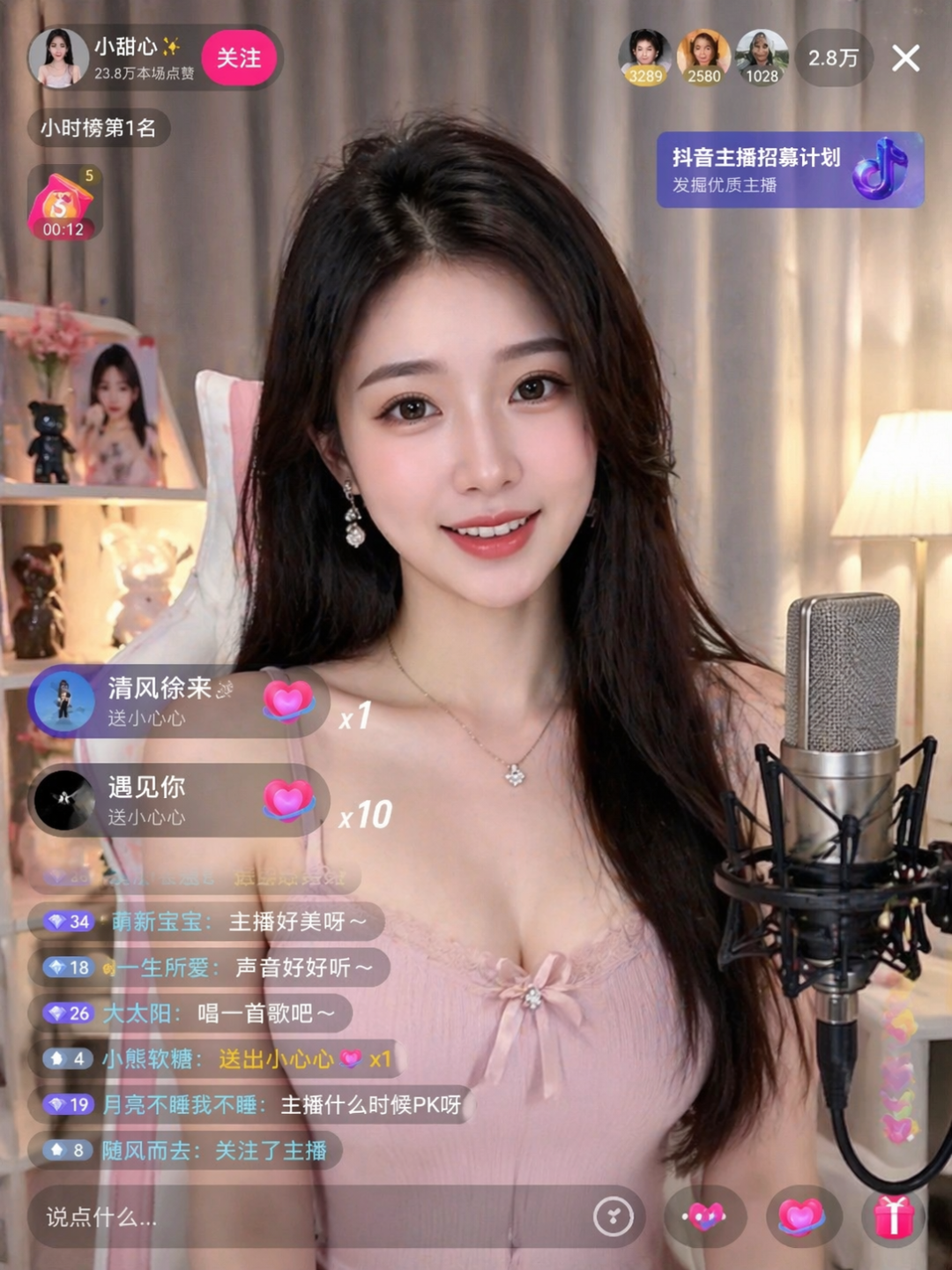
生成结果里,人物不是唯一重点。更关键的是界面元素的组织方式:评论区在左下角,右侧有互动按钮,顶部有直播状态和观众信息,整体结构接近真实短视频直播间。
这类能力来自两部分:
| 能力 | 作用 |
|---|---|
| 世界知识 | 知道常见 App、游戏、直播、视频播放器大致长什么样 |
| 版式生成 | 能把按钮、头像、评论、图标、文字放在合理位置 |
| 文本渲染 | 能生成接近真实界面的中文信息 |
| 视觉一致性 | 人物、背景、UI 元素的光影和清晰度相对统一 |
这也带来一个现实问题:当生成图足够像真实截图时,普通用户很难只靠肉眼判断真假。尤其是涉及维权、爆料、聊天记录、直播截图、商品页面时,图片本身不再能作为强证据,必须结合来源、时间戳、文件元数据、平台记录等信息交叉验证。
商业视觉:从灵感草图走向可用初稿
GPT Image 2 对设计、营销、电商、广告的影响更直接。过去很多设计任务要经历找参考、搭版式、修字体、做合成、调质感等步骤。现在一段提示词可以先生成较完整的视觉初稿,再由设计师做筛选和精修。
产品结构图
提示词:
给「张雪机车」的摩托车设计一张酷炫的产品分解图

产品分解图需要同时处理机械结构、零件排布、透视、光影和科技感背景。GPT Image 2 生成的结果适合作为概念提案、风格探索或早期沟通材料。
但它不等于工业设计图。零件结构可能并不符合真实工程约束,尺寸关系、连接方式、材料强度都不能直接用于生产。它更适合回答“这个方向看起来是什么感觉”,不适合回答“这个结构能不能制造”。
电商广告图
提示词:
产品广告照片,一个游泳圈,有吸引力,能获得大量点击率,16:9,使用中文

电商广告图的难点在于:画面要醒目,产品要突出,中文卖点要可读,比例还要符合投放平台要求。GPT Image 2 可以同时处理产品、背景、促销文字和画面构图,适合快速生成多版创意。
更合理的工作流是让模型一次生成多个方向,再挑选可用版本进入人工修图环节:
flowchart TD
A[明确商品与卖点] --> B[写提示词]
B --> C[生成多版视觉]
C --> D{筛选方向}
D -->|构图可用| E[人工修字与品牌规范调整]
D -->|卖点不清| B
E --> F[投放尺寸适配]
F --> G[上线前审核]
漫画和分镜
提示词:
经典漫画书内页,包含分镜格子、人物动态动作、对话气泡

漫画内页比单张海报更复杂,因为它要求连续画格、人物动作、对话气泡和阅读顺序。GPT Image 2 能生成带分镜感的页面,适合做故事板、广告脚本草稿、短视频分镜参考。
限制也很明显:多页连续创作时,人物一致性、服装细节、场景连续性仍然需要额外控制。单张图可以很惊艳,成套交付还需要更严格的角色设定和人工校对。
适合用在哪些场景
GPT Image 2 更像是一个视觉生产加速器,而不是完全替代设计流程的“自动交付机器”。不同场景的可用程度差别很大。
| 场景 | 适合程度 | 推荐用法 | 主要风险 |
|---|---|---|---|
| 灵感探索 | 高 | 快速生成多个视觉方向 | 容易被高完成度迷惑,忽略实际需求 |
| 电商首图草稿 | 高 | 生成构图和促销风格,再人工修字 | 促销信息、价格、功效必须复核 |
| 海报概念稿 | 高 | 生成风格方案和排版参考 | 品牌字体、Logo、版权素材需替换 |
| 产品结构概念 | 中 | 做外观方向、科技感展示 | 结构可能不符合工程逻辑 |
| UI 场景演示 | 中 | 做概念演示、故事板 | 可能误导为真实产品截图 |
| 试卷、证件、票据 | 低 | 只适合研究模型能力 | 容易被滥用,不能作为真实材料 |
| 新闻截图、爆料图 | 低 | 不应作为事实证据 | 真实性难以仅靠视觉判断 |
提示词怎么写更稳
GPT Image 2 对简单提示词的理解能力已经很强,但要得到更可控的结果,提示词最好包含五类信息:
- 主体:要生成什么。
- 场景:它出现在哪里。
- 风格:照片、海报、漫画、工业渲染、报纸、截图等。
- 文字要求:必须出现哪些中文,是否需要标题、副标题、按钮文案。
- 尺寸比例:16:9、9:16、1:1、21:9 等。
可直接套用这个模板:
生成一张【画面类型】。
主体是【主体描述】,场景是【场景描述】。
整体风格为【风格关键词】,画面比例为【比例】。
图片中需要包含中文文字:【必须出现的文字】。
文字要求清晰可读,排版符合【报纸/电商广告/直播界面/试卷/漫画】的常见布局。
示例:
生成一张 16:9 的电商广告图。
主体是一个蓝色儿童游泳圈,场景是夏天泳池边。
整体风格明亮、高饱和、适合电商首页点击。
图片中需要包含中文文字:「夏日玩水必备」「加厚防漏」「儿童专用」。
文字清晰可读,排版符合电商促销海报的常见布局。
对于中文文字较多的图片,不要一次塞入过长文案。更稳的做法是先让模型生成版式和主视觉,再用人工设计工具替换最终文案。
生成结果必须检查哪些地方
GPT Image 2 生成的图片完成度高,但越像真实成品,越需要审核。尤其是中文、数字、品牌、真实人物和产品功效,不能只看画面漂亮。
| 检查项 | 怎么看 |
|---|---|
| 中文是否可读 | 放大检查每个字,尤其是标题、价格、日期、按钮文案 |
| 数字是否正确 | 日期、价格、电话号码、百分比、题目数字都要逐项核对 |
| 排版是否合理 | 标题层级、行距、边距、对齐方式是否符合使用场景 |
| UI 是否会误导 | 是否让人误以为是真实 App 截图或真实平台公告 |
| 品牌与商标 | 是否出现受保护的 Logo、角色、商品外观 |
| 人物肖像 | 是否涉及真实公众人物或普通人的可识别形象 |
| 产品声明 | 功效、参数、认证、优惠信息是否真实 |
| 文件用途 | 是否会被当作证据、证件、票据、新闻图片传播 |
如果用于商业投放,建议把 GPT Image 2 的输出当作“高质量初稿”,而不是最终交付文件。最终版本仍然应该经过设计、法务、运营或产品负责人检查。
使用入口和速率限制
在 ChatGPT 里可以通过图片创建入口使用 GPT Image 2。常见路径是点击输入框附近的加号,选择创建图片;也可以在侧边栏的图片入口中打开。
生成频率会受到限制。连续发送多条图片生成请求时,系统可能提示需要等待一段时间。

这类限制对工作流有影响。如果要批量生成广告图、分镜或多套视觉方案,最好提前整理好提示词,减少反复试错,把每次生成都用于验证一个明确方向。
对内容真实性的影响
GPT Image 2 最大的变化不是“图片更漂亮”,而是它降低了伪造复杂视觉材料的门槛。过去中文试卷、直播截图、游戏界面、报纸版面、商业广告都需要一定设计能力才能做得像;现在只要描述清楚,模型就能生成可信度很高的结果。
这会改变两个习惯:
- 不能再把图片当作天然证据。截图、试卷、直播画面、商品页面都需要来源验证。
- 设计流程会更依赖审核能力。生成变快以后,筛选、校对、合规检查会变得更重要。
GPT Image 2 更适合承担“从 0 到 1 的视觉生成”和“多方向快速探索”。真正上线、发布、投放、举证的内容,仍然需要人来确认事实、版权、品牌规范和使用边界。