LLM Agent(基于大语言模型的智能体)越来越像一个“会调用外部能力的操作系统”。它本身负责理解任务、规划步骤和组织上下文,真正执行文件处理、代码审查、数据库迁移、API 调用、文档生成等动作时,往往依赖一组外部技能,也就是 skills、tools 或 plugins。
技能少的时候,选择并不难。把几十个技能的名称和描述放进上下文,大模型可以直接判断哪个工具适合当前任务。问题出现在技能池扩大之后:当候选技能达到几万甚至更多时,Agent 不可能把所有技能说明都塞进上下文窗口,也不能让大模型逐个阅读后再判断。上下文会被撑爆,推理成本会明显上升,技能之间的重复和相似实现还会让选择变得更不稳定。
SkillRouter 要解决的就是这个上游问题:给定一个用户任务,从大规模技能池中找出最合适的技能。
技能路由到底难在哪里
可以把一个技能表示成三部分:
skill = {
name: 技能名称,
description: 简短描述,
body: 完整实现文本,包括详细说明、代码、参数、依赖和使用逻辑
}
技能路由的输入是用户查询 q,输出是候选技能列表中最相关的技能 s。如果排在第一位的技能正好是标注答案,就记作 Hit@1 命中;如果答案出现在前 K 个候选里,就记作 Recall@K 命中。
flowchart LR
Q[用户任务] --> R[技能路由器]
P[(大规模技能池)]
P --> R
R --> C[Top-K 候选技能]
C --> A[Agent 加载并使用技能]
难点不只是“候选数量大”,更麻烦的是“候选很像”。例如一个任务里出现了 Git、Docker、PDF、database 这样的关键词,技能池里可能有几十个名称相似、描述相近的技能。它们都声称能处理相同领域的问题,但真正的差异藏在实现里:
| 差异位置 | 例子 |
|---|---|
| 依赖库不同 | 一个 PDF 技能使用 pypdf,另一个使用 pdfplumber |
| 参数支持不同 | 一个 Docker 技能只生成镜像,一个还能输出 Docker Compose |
| 输入输出格式不同 | 一个处理本地文件路径,一个只接受 URL |
| 错误处理不同 | 一个能处理缺页、乱码、权限问题,另一个只适合简单场景 |
| 组合能力不同 | 一个只做数据库检查,一个还能把迁移脚本转成容器配置 |
名称和描述通常写得很短,甚至带有营销式概括。在小技能池里这还能凑合,在 8 万规模的技能池里,信息量明显不够。
“名称 + 描述”并不够用
很多 Agent 框架采用渐进式披露设计:常驻上下文里只放技能名称和描述,只有选中某个技能之后,才加载完整的技能文件、脚本和资源。这种设计能节省上下文,但它隐含了一个前提:名称和描述足以完成技能选择。
SkillRouter 的实验直接说明,这个前提并不可靠。研究在约 8 万个技能和 75 个专家验证查询上比较了两种输入配置:
| 输入配置 | 含义 |
|---|---|
nd | 只使用 name + description |
full | 使用 name + description + body |
结果差距非常大:
| 方法 | 只用 name + description | 使用完整技能文本 | 现象 |
|---|---|---|---|
| BM25 关键词检索 | Hit@1 为 0 | Hit@1 为 34.7% | 用户查询和技能短描述几乎没有稳定词汇重叠 |
| Qwen3-Emb-0.6B | 22.7% | 58.7% | 缺少 body 后下降 36 个百分点 |
| Qwen3-Emb-8B | 30.7% | 64.0% | 更大的模型也难以弥补信息缺失 |
| 只用 nd 的重排序器 | 约 30.7% | 明显更高 | 信息不足时,重排序可能把本来较好的顺序打乱 |
这说明技能选择不是单纯的语义相似度问题。如果 body 不参与路由,模型看到的只是“这个技能大概做什么”,却看不到“它具体怎么做、支持哪些边界情况、能否满足任务里的隐含条件”。
技能 body 的作用可以用这张实验图概括:
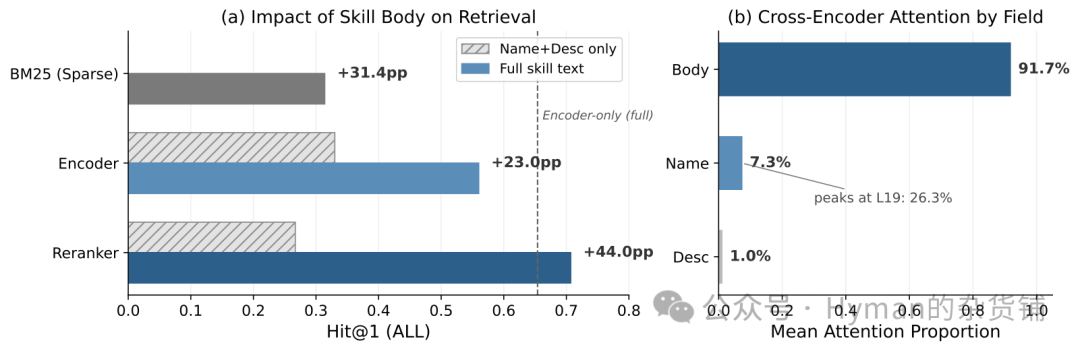
左侧结果显示,移除 body 会让不同方法的准确率下降 29 到 44 个百分点;右侧注意力分析显示,交叉编码器判断相关性时,91.7% 的注意力落在 body 上,name 只占 7.3%,description 只有 1.0%。也就是说,模型真正依赖的是完整实现信息,而不是简短介绍。
SkillRouter 的两阶段结构
SkillRouter 采用典型的“召回 + 精排”结构。第一阶段用双编码器把约 8 万技能缩小到 Top-20 候选,第二阶段用交叉编码器对这 20 个候选重新排序。两个阶段都使用完整技能文本。
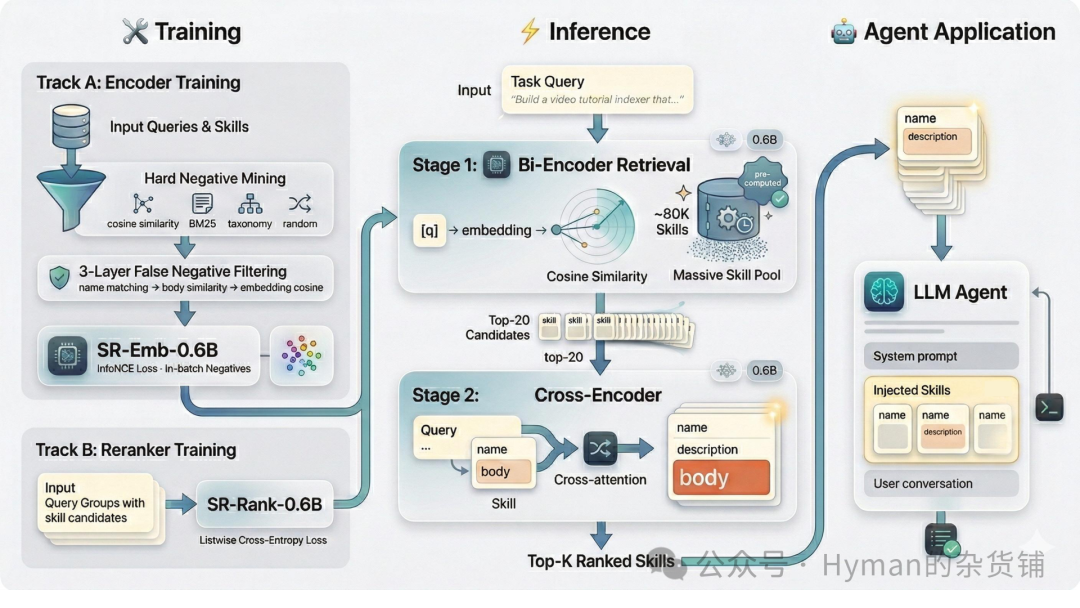
这条流水线的核心取舍很清楚:全量技能不能逐个精读,所以先用便宜的向量检索做粗筛;Top-20 数量足够小,再交给交叉编码器做细粒度判断。
flowchart LR
Q[用户查询] --> E[SR-Emb-0.6B 编码查询]
S[(预计算技能向量索引)]
E --> ANN[ANN 近似最近邻检索]
S --> ANN
ANN --> T[Top-20 候选]
T --> R[SR-Rank-0.6B 交叉编码器重排序]
R --> O[最终技能排名]
ANN 是 Approximate Nearest Neighbor(近似最近邻)搜索,用来在大规模向量库中快速找到相似向量。技能向量可以离线预计算,在线请求只需要编码用户查询、检索候选、重排 Top-20。
第一阶段:双编码器负责大规模召回
双编码器的思路是分别编码查询和技能,然后用向量相似度做检索。
flowchart TB
Q[查询文本] --> QE[查询编码器]
SK[完整技能文本] --> SE[技能编码器]
QE --> QV[查询向量]
SE --> SV[技能向量]
QV --> SIM[余弦相似度]
SV --> SIM
SIM --> TOPK[Top-K 技能]
SkillRouter 对 Qwen3-Emb-0.6B 做任务微调,得到 SR-Emb-0.6B。选择 0.6B 规模不是追求最大参数量,而是为了让路由器能在个人设备上运行。
训练数据由约 37,979 个“查询—技能”配对构成。技能从约 8 万个开源技能中分层采样,覆盖 51 个功能类别。每个技能对应的用户查询由 GPT-4o-mini 合成,生成时会读取技能 metadata 和 body,但要求不能直接提到技能名称。这样做是为了让查询更像真实需求,而不是“帮我调用某某技能”这种泄露答案的表达。
训练双编码器时,负样本非常关键。每个查询配 10 个负样本,来源分成四类:
| 负样本类型 | 数量 | 作用 |
|---|---|---|
| 语义负样本 | 4 | 由基础 embedding 模型找出相似但不正确的技能,难度最高 |
| 词汇负样本 | 3 | 由 BM25 找出关键词重叠的混淆项 |
| 分类负样本 | 2 | 从同一功能类别里随机选,模拟同领域干扰 |
| 随机负样本 | 1 | 从不同类别抽样,提供容易区分的标定样本 |
社区技能库里存在大量重复能力。如果把几乎等价的技能当成负样本,模型会被迫把本该接近的技能推远,训练信号会被污染。SkillRouter 做了三层假负样本过滤:
| 过滤方式 | 规则 |
|---|---|
| 名称去重 | 移除与正样本同名的负样本 |
| 文本重叠过滤 | 移除 body 三元组 Jaccard 相似度大于 0.6 的负样本 |
| 语义相似过滤 | 移除 embedding 余弦相似度大于 0.92 的负样本 |
这一步移除了约 10% 的挖掘负样本。消融实验显示,去掉过滤后 Hit@1 从 65.4% 降到 61.3%,在 Hard 查询上的损失更明显。
双编码器训练使用 InfoNCE 对比学习损失,可以写成:
L_i = - log exp(sim(q_i, s_i+) / τ)
--------------------------------
Σ_j exp(sim(q_i, s_j) / τ)
其中:
q_i是第 i 个查询;s_i+是对应正样本技能;s_j是 batch 内候选技能,包括正样本和负样本;sim是余弦相似度;τ是温度参数,用来调节相似度分布的尖锐程度。
这个损失会拉近查询和正确技能,同时把负样本推远。由于负样本经过专门挖掘和过滤,模型学到的不是粗略主题匹配,而是在相似技能之间做细粒度区分。
第二阶段:交叉编码器负责精排
双编码器速度快,但它有一个天然限制:查询和技能是分开编码的,向量相似度只能做整体比较。对于高度相似的技能,仅靠两个向量的距离不一定能区分“差不多”和“正好合适”。
交叉编码器把查询和候选技能拼接后一起输入模型,让查询 token 与技能 body token 直接做交叉注意力。SkillRouter 对 Qwen3-Reranker-0.6B 微调得到 SR-Rank-0.6B。
输入形式可以简化成:
[QUERY]
用户任务
[SKILL]
name: ...
description: ...
body: ...
训练重排序器时,每个查询先由 SR-Emb-0.6B 检索 Top-20 候选,再把这 20 个候选组成一个列表训练样本。每个候选带有二元相关性标签,正确技能为正,其余为负,并继续使用假负样本过滤。
重排序器的关键不是“能不能打分”,而是“用什么损失让它学会排序”。SkillRouter 对比了两种训练目标。
点式二元交叉熵把每个“查询—技能”对独立处理:
L_bce = - [ y log σ(r) + (1 - y) log(1 - σ(r)) ]
其中 r 是相关性分数,σ 是 sigmoid 函数。
列表式交叉熵直接在整个候选列表上归一化:
L_list = - log exp(r(q, s+) / τ)
-------------------------
Σ_s∈C exp(r(q, s) / τ)
其中 C 是同一个查询对应的候选列表。
实验结果差异很大:列表式交叉熵比点式二元交叉熵高 30.7 个百分点。原因在于技能池同质性很强,Top-20 里经常是一堆“看起来都相关”的技能。点式训练让模型独立判断每个候选是否相关,分数容易挤在一个很窄的区间;列表式训练要求模型在同一组候选里做相对比较,更符合“从一堆相似技能里挑出最合适那个”的任务形态。
body 为什么会成为决定性信号
交叉编码器的注意力分布给出了更细的解释。SR-Rank-0.6B 一共有 28 层,每层有多个注意力头。把注意力权重按 name、description、body 三个字段统计后,可以看到明显的层间模式。
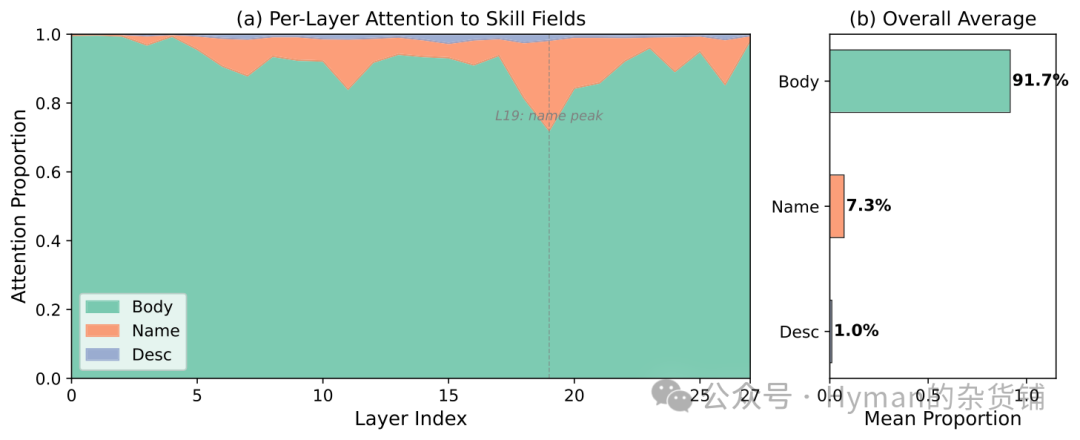
注意力大致经历三个阶段:
| 层范围 | 主要关注字段 | 含义 |
|---|---|---|
| 0–6 层 | body 约 97.3% | 解析代码、参数、依赖、实现细节等底层信息 |
| 7–20 层 | name 权重上升,第 19 层约 26.3% | 做名称级语义对齐,确认技能方向是否一致 |
| 21–27 层 | body 回到约 91.7% | 回到完整实现,判断是否真正满足任务 |
description 在所有层里的权重都很低,最高也只有约 1.4%。这并不意味着描述完全无用,而是说它的信息密度太低,且大多能从 body 中获得更完整的版本。
这个模式也解释了为什么“只给名称和描述”的路由方案会失败。模型需要判断的是功能实现是否满足具体任务,而不是标题是否看起来相关。标题和描述只能提供入口,body 才提供可验证的能力边界。
实验结果:1.2B 流水线超过 8B 零样本基线
SR-Emb-0.6B 作为单独编码器,在约 8 万技能评测基准上达到 65.4% 平均 Hit@1,超过了 Qwen3-Emb-8B 的 64.0%。这说明针对技能路由做任务微调,比单纯扩大模型参数更直接。
| 编码器 | 参数规模 | 平均 Hit@1 |
|---|---|---|
| Qwen3-Emb-0.6B | 0.6B | 58.7% |
| SR-Emb-0.6B | 0.6B | 65.4% |
| Qwen3-Emb-8B | 8B | 64.0% |
| SR-Emb-8B | 8B | 68.0% |
端到端流水线里,SR-Emb-0.6B 加 SR-Rank-0.6B 总共只有 1.2B 参数,平均 Hit@1 达到 74.0%。相比 Qwen3-Emb-8B 加 Qwen3-Rank-8B 的 68.0%,高出 6 个百分点。
| 流水线 | 参数规模 | 平均 Hit@1 |
|---|---|---|
| Qwen3-Emb-8B + Qwen3-Rank-8B | 16B | 68.0% |
| SR-Emb-0.6B + SR-Rank-0.6B | 1.2B | 74.0% |
| SR-Emb-8B + SR-Rank-8B | 16B | 76.0% |
不同查询类型上的收益也比较稳定:
| 查询类型 | 1.2B SkillRouter 相对 8B 零样本流水线收益 |
|---|---|
| Easy 查询 | +8.0pp |
| Hard 查询 | +4.0pp |
| 单技能查询 | +6.2pp |
| 多技能查询 | +5.9pp |
这组结果说明,技能路由不是“模型越大越好”的简单规模问题。只要训练数据、负样本、输入字段和排序目标设计对了,小模型也能在特定任务上超过大模型零样本方案。
重排序器带来了多少净收益
重排序器并不总是有帮助。它可能把编码器已经排对的结果打乱,也可能把编码器排在后面的正确技能拉到第一位。逐查询分解能看清它的真实贡献。
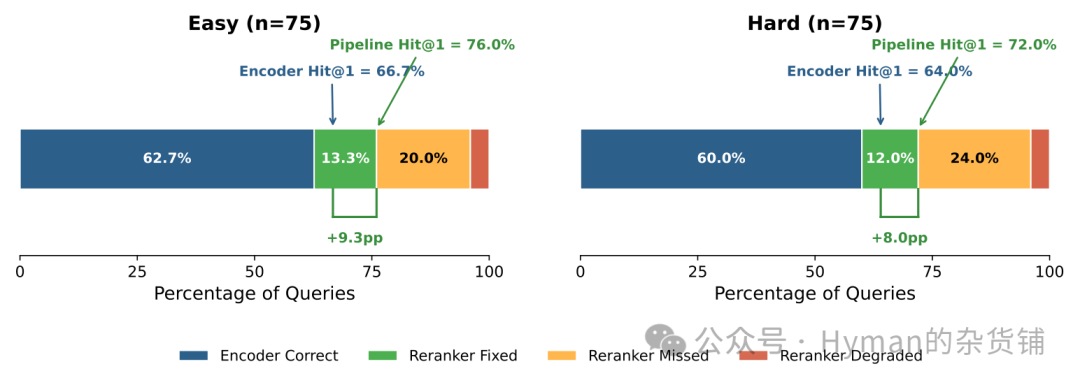
在 150 个查询中:
| 情况 | 查询数 | 占比 |
|---|---|---|
| 编码器和重排序器都正确 | 92 | 61.3% |
| 重排序器修正编码器错误 | 19 | 12.7% |
| 重排序器把正确结果改错 | 6 | 4.0% |
| 两者都错 | 33 | 22.0% |
重排序器净贡献为 +8.7pp Hit@1。它破坏了 4.0% 的查询,但修正了 12.7% 的查询。对于一个两阶段系统来说,这是比较健康的结构:精排阶段带来的收益明显大于副作用。
当前天花板来自召回阶段
重排序器只能在 Top-K 候选里重新排序。如果正确技能没有进入候选集,精排模型再强也无法补救。
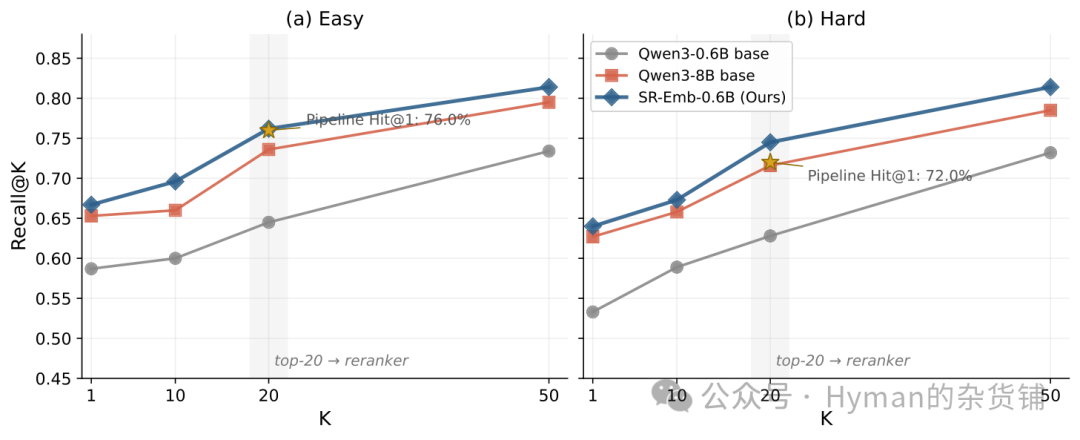
SR-Emb-0.6B 在 K=20 时 Recall@K 为 75.4%,K=50 时达到 81.4%。这意味着仍有接近 20% 的正确技能在前 50 个候选之外。当前系统的主要上限不是精排能力,而是第一阶段召回。
提升空间主要有三类:
| 方向 | 作用 | 代价 |
|---|---|---|
| 提高编码器召回率 | 让正确技能更容易进入候选集 | 需要更强训练数据和负样本策略 |
| 扩大候选窗口 | 从 Top-20 扩到 Top-50 或更多 | 重排序成本上升 |
| 多路召回 | 结合语义检索、关键词检索、类别召回 | 系统复杂度增加,需要融合排序 |
两个例子说明模型学到了什么
一个查询要求从本地教学视频中提取章节时间戳。表面关键词是 video,很多基础编码器会优先找视频剪辑、视频浏览类工具。但真正的关键步骤是语音识别:只有先把视频音频转成文本,才能获得章节时间戳。正确技能是基于 Whisper 的 speech-to-text。微调后的 SR-Emb-0.6B 能把“视频 + 时间戳”映射到“语音转录”这个间接能力上,而不是停留在关键词匹配。
另一个查询要求把数据库迁移脚本转换成 Docker Compose 配置。编码器能把正确技能召回到 Top-20,但只排在第 8 位,前面混着多个与 docker、database 相关的技能。SR-Rank-0.6B 读取候选 body 后发现,只有目标技能同时覆盖“数据库迁移”和“Docker Compose 生成”两个能力,于是把它提到第一位。这个例子体现了交叉编码器精读 body 的价值。
端侧部署为什么可行
SkillRouter 的在线流程比较轻:
sequenceDiagram
participant U as 用户
participant E as 0.6B 编码器
participant V as 向量索引
participant R as 0.6B 重排序器
participant A as Agent
U->>E: 输入任务
E->>V: 查询向量
V-->>E: Top-20 技能候选
E->>R: 查询 + 候选完整文本
R-->>A: 最终技能排名
A-->>U: 加载技能并执行任务
技能 embedding 可以提前算好并写入向量索引。在线请求只需要:
- 用 0.6B 编码器编码查询;
- 用 ANN 检索预计算技能向量;
- 用 0.6B 交叉编码器重排 Top-20。
整个主流水线只有 1.2B 参数,不需要 8B 级别模型,也不依赖云端 API。对于个人 Agent 产品,本地技能路由有两个直接好处:用户任务不必发送到外部服务,技能选择延迟也更容易控制。
对 Agent 架构的启示
SkillRouter 暴露了 Agent 技能系统里的一个结构性矛盾:Agent 执行任务时受上下文限制,不能把所有技能 body 都加载进来;但准确选择技能又高度依赖 body。
比较合理的架构是把“路由”和“执行”分开:
| 组件 | 能看到什么 | 职责 |
|---|---|---|
| 路由器 | 大规模技能索引和完整 body | 从技能池里选出最相关候选 |
| Agent | 用户任务、少量候选技能说明、必要脚本 | 规划步骤并调用已选技能 |
| 技能仓库 | name、description、body、资源文件 | 提供可检索、可执行的能力单元 |
这不是简单的工程优化,而是信息流设计。路由器必须能访问完整技能文本,Agent 则只加载被选中的少量技能,避免上下文膨胀。
还有几个设计点很重要:
| 设计点 | 原因 |
|---|---|
| 不要只依赖 name 和 description | 大规模技能池里短描述区分度不足 |
| 训练时要处理假负样本 | 相似或重复技能很容易污染对比学习 |
| 重排序适合用列表式目标 | 技能选择本质是候选之间的相对比较 |
| 编码器召回决定上限 | 正确技能不进候选集,重排序无法补救 |
| 小模型微调很有价值 | 任务数据和训练策略能弥补参数规模差距 |
SkillRouter 的核心判断可以概括成一句话:在大规模 Agent 技能池里,技能选择不是“读标题找工具”,而是“读实现判断能力”。名称和描述适合做人类浏览入口,body 才是机器路由时最可靠的判别信号。