Vibe Coding 指的是用自然语言驱动 AI(人工智能)编程工具完成软件开发。使用者不一定要从零手写每一行代码,而是把需求、约束、界面草图、错误日志、测试结果不断喂给模型,让模型生成代码、修改代码、解释问题,再由人来判断方向和验收结果。
它最适合解决一种很常见的麻烦:需求不大,但足够具体;市面上有类似工具,却总有几个细节不合适。比如 AI 对话分散在多个 IDE(集成开发环境)里不好沉淀、手机相册搜不到想要的图、做 AI 短剧需要在多个平台之间反复搬运素材、常用 PDF 和图片处理工具又担心文件上传到陌生服务器。
这些需求不一定值得成立一个完整项目组,但非常适合做成个人工具、小程序、浏览器插件、macOS 原生应用或者本地网页工具。
Vibe Coding 能做出的东西,通常有一个共同点
真正能落地的 Vibe Coding 项目,往往不是一句“帮我做个很厉害的平台”,而是从一个清晰痛点开始:
| 痛点 | 可以做成的工具 | 核心技术点 |
|---|---|---|
| AI 编程对话分散在 Cursor、Claude Code、Codex 等工具里 | 本地对话归档与技术笔记工具 | 日志同步、结构化存储、大语言模型摘要、全文搜索 |
| macOS 上多个 AI 模型和命令行工具需要手动切换 | AI + CLI 编排工作台 | 工作流引擎、模型适配器、命令执行、任务状态管理 |
| iOS 相册搜索能力弱,关键词搜不到图 | 本地相册语义搜索应用 | CLIP 图文向量、相似度检索、重复图片检测 |
| AI 短剧制作链路太散 | 从剧本到剪辑的一体化工作台 | 剧本生成、角色一致性、分镜、关键帧、视频模型、时间轴剪辑 |
| 在线工具需要上传文件,隐私不可控 | 浏览器端超级工具箱 | File API、Canvas、WebAssembly、PDF 处理、OCR |
| 租金、水电、住户信息容易混乱 | 收租记账小程序 | 表单建模、账单提醒、数据统计、云开发 |
| 划词翻译影响阅读连贯性 | 字幕式划词翻译插件 | 浏览器扩展、文本选择监听、翻译接口、浮层渲染 |
| 班前休闲、年会互动需要轻量小游戏 | 小游戏原型 | Canvas、碰撞检测、计分系统、资源管理 |
这些项目看起来差异很大,但抽象出来都是同一套流程:把一个真实场景拆成输入、处理、输出和约束,再让 AI 按模块生成可运行代码。
flowchart LR
A[具体痛点] --> B[明确使用场景]
B --> C[定义输入和输出]
C --> D[拆分功能模块]
D --> E[让 AI 生成第一版]
E --> F[运行与报错]
F --> G[把错误和期望继续喂给 AI]
G --> H[形成可用原型]
H --> I[补测试、补安全边界、补部署方式]
把一句想法改写成可执行需求
Vibe Coding 的关键不是“让 AI 自由发挥”,而是把模糊想法压缩成明确规格。一个好需求至少包含六类信息:
| 信息 | 说明 | 示例 |
|---|---|---|
| 用户 | 谁会用这个工具 | 经常使用 Cursor、Claude Code、Codex 的开发者 |
| 场景 | 在什么情况下使用 | 想把高质量 AI 对话整理成技术笔记 |
| 输入 | 用户提供什么 | 本地对话记录、项目路径、筛选条件 |
| 输出 | 工具产出什么 | 可搜索笔记、摘要、标签、原始对话索引 |
| 约束 | 不能做什么 | 数据只保存在本地,不上传服务器 |
| 验收 | 怎么判断可用 | 能同步三种来源,搜索关键词能定位到原对话 |
可以直接把需求写成这样的提示词:
我要做一个 macOS 本地工具,用来管理 AI 编程对话记录。
目标用户:
- 经常使用 Cursor、Claude Code、Codex 的开发者
核心需求:
1. 从本地目录导入不同工具的对话记录
2. 统一转换为 Conversation、Message、Note 三种数据结构
3. 调用大语言模型把长对话总结成技术笔记
4. 支持关键词搜索、标签筛选、按项目分组
5. 所有数据保存在本机 SQLite,不上传服务器
请先输出:
- 技术架构
- 数据表设计
- 主要页面
- 第一个可运行版本的开发步骤
这类提示词给出的上下文足够具体,AI 才能生成接近真实项目的方案。后续不要一次性要求它写完整系统,而是按模块推进:先建数据结构,再做导入,再做列表页,再接模型摘要,最后补搜索和导出。
案例一:把 AI 对话变成自己的技术知识库
多个 AI 编程工具同时使用时,对话记录会散落在不同位置:有的在 IDE 侧边栏,有的在命令行历史里,有的只跟某个项目目录绑定。问题不是“没有记录”,而是这些记录没有统一索引,也无法沉淀为可检索知识。
一个本地知识库工具可以按这个流程设计:
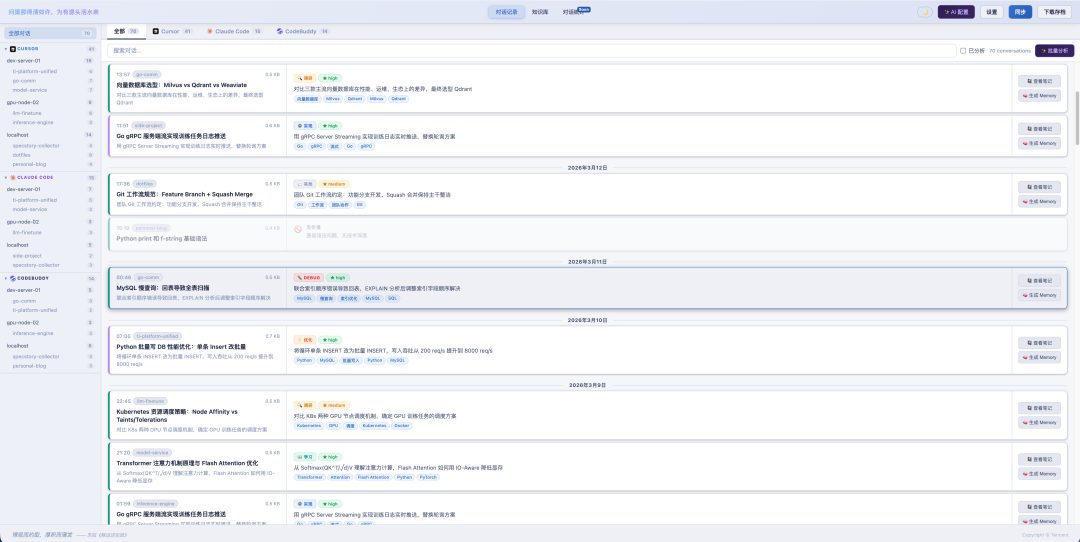
这个界面类工具的重点不在聊天本身,而在“同步、整理、搜索”。左侧通常是来源、项目或标签,主区域展示对话和摘要,用户可以把有价值的问答提炼成长期笔记。
flowchart TD
A[Cursor / Claude Code / Codex 对话记录] --> B[本地同步器]
B --> C[格式归一化]
C --> D[(SQLite 数据库)]
D --> E[长对话切分]
E --> F[大语言模型摘要]
F --> G[技术笔记]
D --> H[全文索引]
G --> H
H --> I[搜索与标签筛选]
数据结构可以从三个核心对象开始:
{
"conversation": {
"id": "conv_001",
"source": "claude-code",
"projectPath": "/Users/me/project/demo",
"title": "修复登录接口超时问题",
"createdAt": "2026-03-19T10:00:00+08:00"
},
"message": {
"id": "msg_001",
"conversationId": "conv_001",
"role": "user",
"content": "接口偶发超时,日志如下……",
"createdAt": "2026-03-19T10:01:00+08:00"
},
"note": {
"id": "note_001",
"conversationId": "conv_001",
"tags": ["Node.js", "超时", "排查"],
"summary": "登录接口超时与数据库连接池耗尽有关,修复方式是限制并发并增加超时日志。"
}
}
这种工具很适合采用“本地优先”架构。对话里可能包含代码、接口地址、业务名和调试日志,默认上传到服务器会带来隐私风险。本地 SQLite、全文索引和可选的大语言模型接口,已经能覆盖大部分个人知识管理需求。
需要注意三点:
| 问题 | 处理方式 |
|---|---|
| 对话太长,超过模型上下文窗口 | 先按主题或轮次切分,再分别摘要,最后合并 |
| 不同工具记录格式不一致 | 为每个来源写适配器,统一转换成内部数据结构 |
| 摘要可能丢失关键细节 | 摘要旁边保留原始对话链接,搜索结果能回跳 |
案例二:用 CLIP 做本地相册语义搜索
传统相册搜索依赖文件名、时间、地点或者系统识别出的少量标签。想找“那张白板上写着系统架构的照片”或者“猫趴在键盘旁边的图”,关键词经常搜不到。
图文互搜可以用 CLIP(Contrastive Language-Image Pre-training,对比语言-图像预训练)模型解决。它会把图片和文本映射到同一个向量空间:图片生成图片向量,搜索词生成文本向量,两者越接近,说明语义越相似。
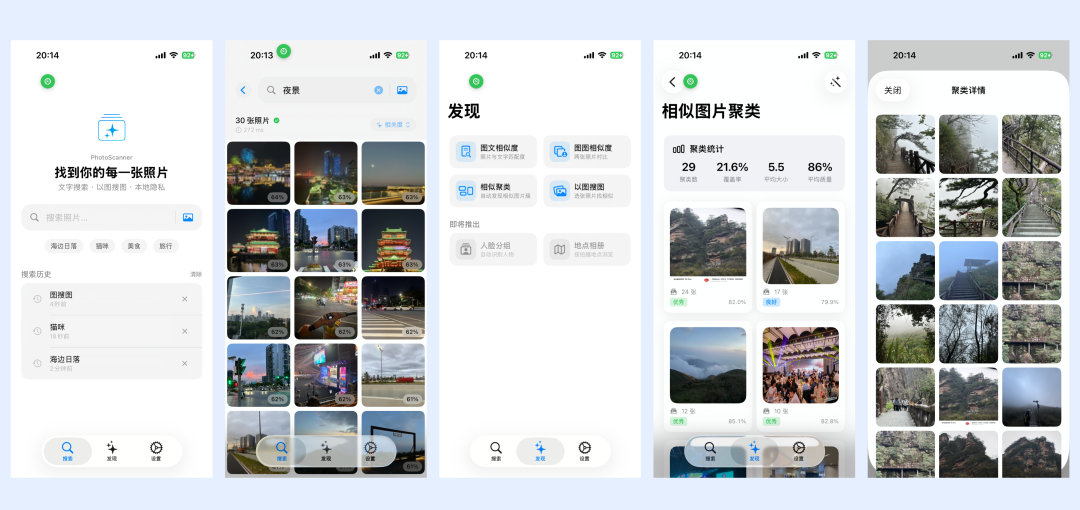
这类相册工具的界面通常由搜索框、结果网格和若干图片处理能力组成。除了“文字搜图”,还可以扩展出重复图片筛选、相似图片查找、图文相似度比较等功能。
flowchart LR
A[本地相册] --> B[读取缩略图]
B --> C[图片特征提取]
C --> D[(向量索引)]
E[用户输入搜索词] --> F[文本特征提取]
F --> G[相似度检索]
D --> G
G --> H[返回最相似图片]
核心检索逻辑可以抽象成伪代码:
def build_index(photos):
index = VectorIndex()
for photo in photos:
image = load_thumbnail(photo.path)
embedding = clip.encode_image(image)
index.add(id=photo.id, vector=embedding, metadata={
"path": photo.path,
"created_at": photo.created_at
})
return index
def search_photos(query, index, top_k=50):
text_embedding = clip.encode_text(query)
results = index.search(vector=text_embedding, top_k=top_k)
return results
移动端或桌面端实现时,工程难点主要在性能和隐私:
| 难点 | 处理方式 |
|---|---|
| 相册数量大,首次建索引慢 | 后台分批处理,优先处理最近照片 |
| 原图太大,占用内存 | 使用缩略图生成向量,必要时再读取原图 |
| 用户不希望照片上传 | 模型本地运行,索引只保存在设备内 |
| 搜索结果需要可解释 | 展示相似度、命中的标签或模型生成描述 |
这类工具非常适合 Vibe Coding,因为功能边界清楚:读取照片、生成向量、存索引、查相似度、显示结果。每个模块都能独立验证。
案例三:AI 短剧工作台要解决“流程断裂”
AI 视频创作经常卡在工具链上。剧本在一个工具里生成,角色图在另一个工具里做,分镜表还要手动整理,关键帧和视频片段分散在多个模型平台,剪辑又要切到专业软件。单个模型能力再强,流程不连贯也会浪费大量时间。
一个 AI 短剧工作台可以把流程拆成六个阶段:
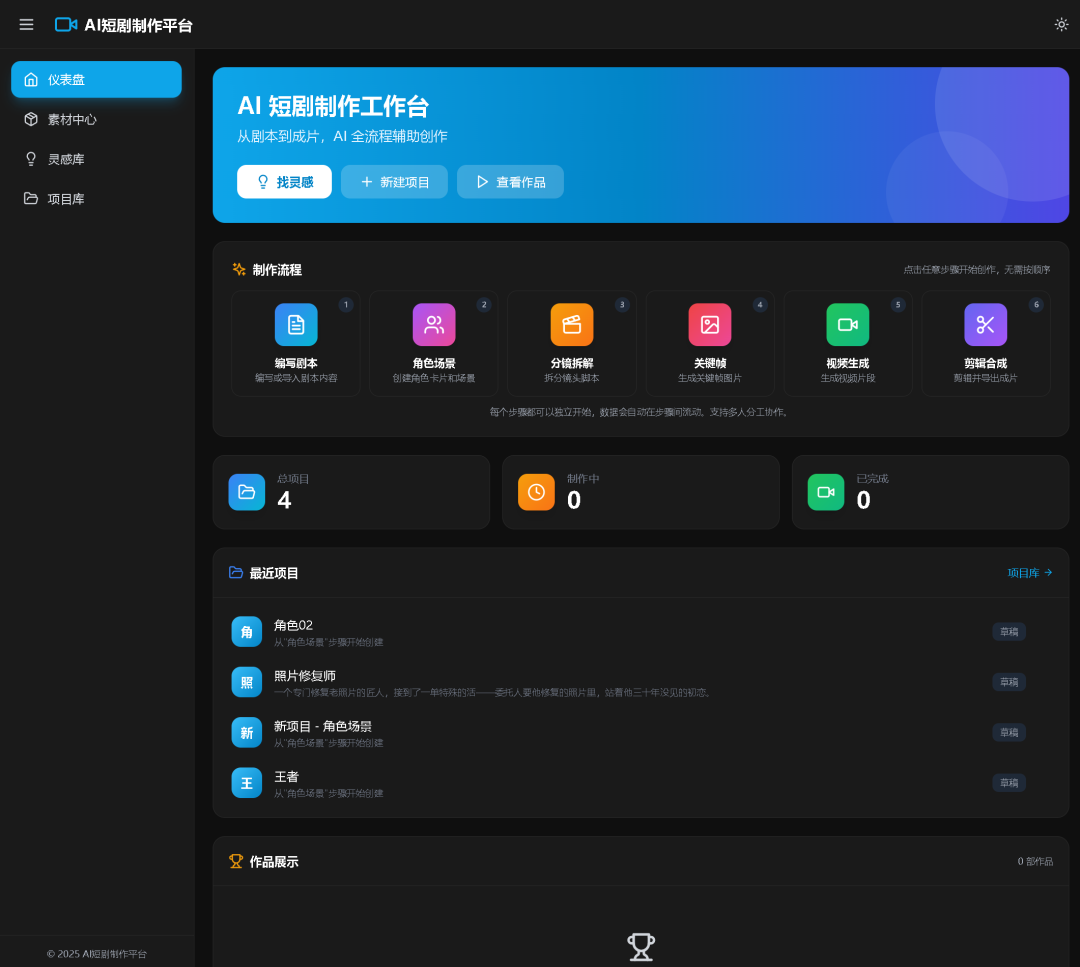
界面上需要同时表达项目、角色、分镜、关键帧、视频片段和时间轴。它不是单纯的“生成按钮”,而是一个生产流水线管理器。
flowchart LR
A[一句话想法] --> B[剧本]
B --> C[角色设定]
C --> D[分镜]
D --> E[关键帧]
E --> F[视频片段]
F --> G[时间轴剪辑]
G --> H[成片导出]
各阶段的输入输出要设计清楚:
| 阶段 | 输入 | 输出 |
|---|---|---|
| 剧本 | 故事想法、题材、时长 | 场景列表、对白、剧情节奏 |
| 角色 | 人设描述、参考图 | 角色立绘、外观约束 |
| 分镜 | 剧本场景、角色 | 镜头描述、景别、动作 |
| 关键帧 | 分镜、角色立绘 | 每个镜头的首帧或关键画面 |
| 视频 | 关键帧、动作描述 | 视频片段 |
| 剪辑 | 多个视频片段 | 时间轴、字幕、转场、成片 |
角色一致性是这类工具的核心问题。一个可行做法是把角色信息做成结构化资产,在每次生成分镜、关键帧和视频时都自动带上:
{
"character": {
"id": "char_elsa",
"name": "冰雪女王",
"appearance": "银白长发,蓝色长裙,冷色调妆容",
"referenceImages": ["assets/elsa_front.png"],
"negativePrompt": "短发,红色服装,男性化面部"
}
}
如果接入多个视频模型,还需要增加模型适配层。不同模型的参数、比例、时长、参考图能力都不同,业务层不应该直接依赖某一个模型接口。
flowchart TD
A[镜头任务] --> B[统一生成参数]
B --> C{选择模型}
C --> D[模型 A 适配器]
C --> E[模型 B 适配器]
C --> F[模型 C 适配器]
D --> G[视频结果]
E --> G
F --> G
G --> H[结果对比与挑选]
这种项目不适合一开始就追求“全自动成片”。更稳的路径是先做半自动:AI 负责生成候选,用户保留选择权和编辑权。等剧本、角色、分镜、视频片段都能稳定流转,再补批量渲染和时间轴剪辑。
案例四:浏览器端工具箱的核心是“文件不离开设备”
图片压缩、PDF 合并、视频裁剪、文字识别这些需求很高频,但很多在线工具要求上传文件。对于合同、证件、内部截图、未发布素材来说,上传本身就是风险。
浏览器端工具箱可以把运算放在用户设备上完成:
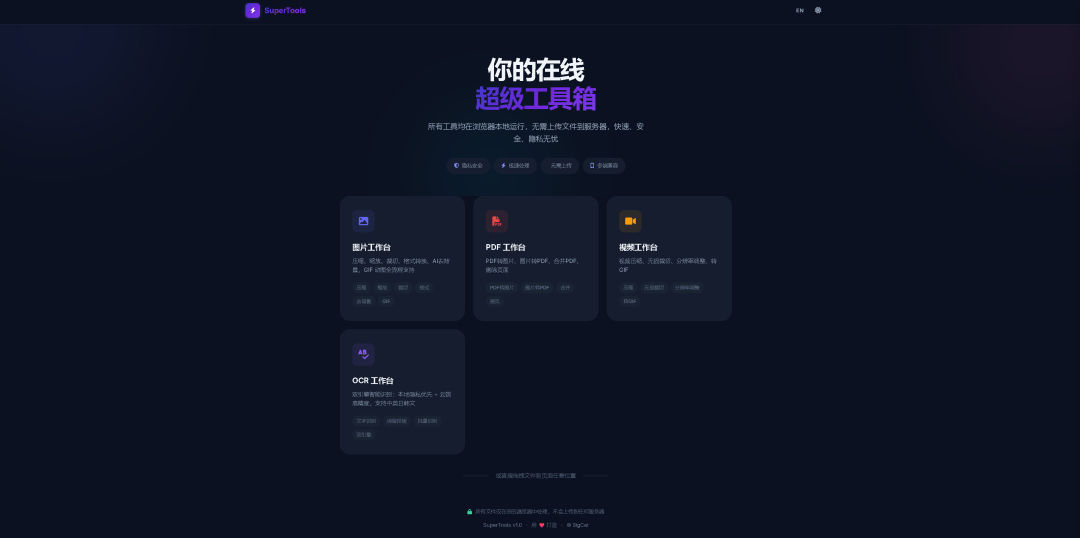
这种工具的设计重点是“打开即用”。没有账号、没有后端、没有数据库,用户拖入文件后直接在浏览器内处理。
flowchart LR
A[用户选择文件] --> B[浏览器 File API 读取]
B --> C{任务类型}
C --> D[Canvas 图片处理]
C --> E[PDF 解析与合并]
C --> F[WebAssembly 视频处理]
C --> G[OCR 文字识别]
D --> H[生成结果文件]
E --> H
F --> H
G --> H
H --> I[本地下载]
常见功能可以这样选技术:
| 功能 | 浏览器侧技术 |
|---|---|
| 图片压缩、裁剪、格式转换 | Canvas、createImageBitmap |
| PDF 拆分、合并、预览 | PDF.js、pdf-lib |
| 视频转码、截取 | FFmpeg WebAssembly |
| 文字识别 | OCR(光学字符识别)模型或浏览器侧推理 |
| 文件打包下载 | Blob、URL.createObjectURL |
浏览器端方案的限制也很明显:大文件会占用内存,移动端性能不稳定,复杂视频任务可能很慢。它适合处理轻量、高频、隐私敏感的小任务,不适合替代专业剪辑软件或大型批处理服务。
案例五:Agent 编排不是再做一个聊天框
使用多个 AI 编程工具时,经常会出现这样的流程:让一个模型写代码,再让另一个模型 Review,运行测试后把报错贴回去,再让模型修复。人工来回复制粘贴没问题,但频率高了就会变成负担。
Agent 工作台要解决的是“把多模型和命令行工具串起来”。
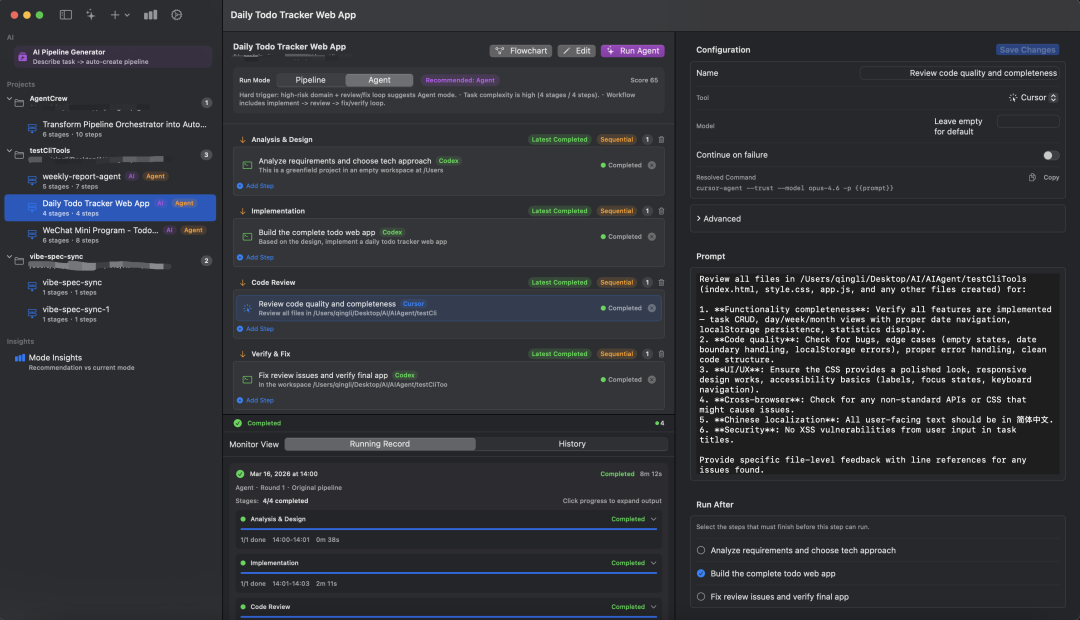
这种界面通常由任务列表、流程节点、执行日志和工具输出组成。它的价值不是把聊天框换个皮,而是把 Implement、Review、Fix、Verify 这些步骤变成可追踪、可重试的工作流。
sequenceDiagram
participant U as 用户
participant W as 工作流引擎
participant A as 实现模型
participant R as Review 模型
participant T as 测试命令
participant F as 修复模型
U->>W: 提交开发任务
W->>A: 生成代码修改
A-->>W: 返回 Patch
W->>R: 审查 Patch
R-->>W: 返回问题列表
W->>T: 执行 npm test
T-->>W: 返回测试结果
alt 测试失败
W->>F: 发送错误日志和 Patch
F-->>W: 返回修复 Patch
W->>T: 重新执行测试
else 测试通过
W-->>U: 输出结果和日志
end
一个最小可用的工作流配置可以长这样:
name: implement-review-fix-verify
steps:
- id: implement
type: ai
model: claude
input:
- task.md
- src/
- id: review
type: ai
model: codex
input:
- patch_from: implement
- id: test
type: command
run: npm test
- id: fix
type: ai
model: cursor
when: test.failed
input:
- error_from: test
- patch_from: implement
工程上要重点处理四件事:
| 模块 | 关键设计 |
|---|---|
| 模型适配器 | 屏蔽不同 AI 工具的调用方式和输出格式 |
| 命令执行器 | 限制工作目录、环境变量和可执行命令 |
| 日志系统 | 保留每一步输入、输出、错误和耗时 |
| 回滚机制 | 每次改动都生成 Patch,失败时可还原 |
CLI(命令行界面)编排和 CI/CD(持续集成/持续交付)很接近,但它更偏个人开发工作台。早期版本不需要覆盖所有场景,只要能稳定完成“写代码、审查、测试、失败修复”这个闭环,就已经能减少大量重复操作。
Vibe Coding 项目的通用架构
无论是小程序、桌面应用、浏览器插件还是本地工具,很多 Vibe Coding 项目都可以用同一个架构模板来拆。
flowchart TD
A[用户界面] --> B[状态管理]
B --> C[业务服务层]
C --> D{是否需要 AI}
D -->|需要| E[模型适配层]
D -->|不需要| F[本地算法或工具库]
E --> G[提示词模板]
E --> H[API 调用]
F --> I[文件处理 / 图像处理 / 数据计算]
C --> J[(本地存储)]
C --> K[(云端存储,可选)]
C --> L[日志与错误处理]
拆模块时可以按优先级推进:
- 先做最短闭环:输入一份数据,产出一个结果。
- 再做列表、历史记录、搜索和编辑。
- 然后补错误提示、空状态、加载状态。
- 最后考虑账号、同步、多端、权限和部署。
很多项目失败,不是因为 AI 写不出代码,而是因为一开始把范围定得太大。比如“做一个 AI 短剧平台”太宽,“输入一句故事梗概,生成 3 个分镜和对应关键帧”就具体得多。
提示词应该像开发任务,而不是许愿
让 AI 写代码时,可以把每次对话当成一个小型开发任务。推荐固定格式:
任务:
实现一个本地图片压缩页面。
技术栈:
React + TypeScript,不需要后端。
功能:
1. 支持拖拽上传 PNG/JPEG
2. 使用 Canvas 压缩图片
3. 显示压缩前后大小
4. 支持下载压缩结果
约束:
1. 文件不能上传服务器
2. 单个文件最大 20MB
3. 代码要拆成组件
4. 给出必要的错误处理
输出:
1. 文件结构
2. 关键代码
3. 运行命令
4. 可能的边界情况
当代码报错时,不要只说“运行不了”。要给出环境、命令、完整错误和期望行为:
运行环境:
- macOS 14
- Node.js 20
- pnpm 9
执行命令:
pnpm dev
错误信息:
TypeError: Cannot read properties of undefined (reading 'size')
出错文件:
src/components/ImageUploader.tsx
期望:
当用户没有选择文件时,不要报错,页面显示“请选择图片”。
请分析原因并只修改必要代码。
这种写法能减少 AI 猜测空间,也方便后续定位问题。
哪些场景适合 Vibe Coding,哪些不适合
| 场景 | 适合程度 | 原因 |
|---|---|---|
| 个人效率工具 | 高 | 使用者就是需求方,反馈快,边界清楚 |
| 内部小程序、轻量表单、提醒工具 | 高 | 业务逻辑明确,数据模型简单 |
| 浏览器插件、桌面小工具 | 高 | 功能聚焦,容易做最小闭环 |
| 多媒体创作辅助工具 | 中高 | AI 适合生成候选,但需要人工挑选和编辑 |
| 复杂交易系统 | 低 | 强一致性、资金安全、审计要求高 |
| 医疗、金融、法务等高风险决策系统 | 低 | 需要严格合规、可解释和责任边界 |
| 大型多人协作平台 | 中低 | 权限、并发、数据迁移、运维成本高 |
Vibe Coding 不是跳过工程规范,而是把写样板代码、搭界面、接接口、修小错误这些环节加速。越靠近生产环境,越需要补齐测试、安全、日志、权限和数据备份。
从原型走向可维护工具
一个能跑的原型和一个可长期使用的工具之间,还隔着几道工程关。
1. 数据先结构化
不要只把内容塞进一个大字符串。对话、图片、账单、角色、分镜都应该有明确字段。结构化数据方便搜索、筛选、迁移和二次处理。
2. 关键操作留日志
AI 工具生成、文件处理、模型调用、命令执行都可能失败。日志至少要记录输入、输出、错误、耗时和版本,方便回滚和排查。
3. 隐私默认收紧
本地相册、AI 对话、PDF 文件、租金记录都可能包含敏感信息。能本地处理就不要上传;必须调用云端模型时,要明确告诉用户哪些内容会被发送。
4. 每次只扩大一个边界
从单用户到多用户、从本地到云端、从手动到自动、从单模型到多模型,每一次扩展都会引入新复杂度。稳定的做法是一次只改一个边界,并保留回退方案。
5. 用测试固定核心流程
哪怕是个人工具,也应该给核心逻辑补测试。比如账单计算、向量检索、文件转换、工作流状态流转,这些地方一旦出错,用户很难靠界面发现根因。
def test_rent_bill_should_include_water_and_electricity():
rent = 3000
water_fee = 45
electricity_fee = 120
total = calculate_bill(
rent=rent,
water_fee=water_fee,
electricity_fee=electricity_fee
)
assert total == 3165
一个可复用的落地清单
做 Vibe Coding 项目时,可以按这份清单推进:
| 阶段 | 要完成的事 |
|---|---|
| 需求定义 | 写清用户、场景、输入、输出、约束、验收标准 |
| 最小闭环 | 做出能跑通的一条主流程 |
| 数据建模 | 定义核心对象和字段,不急着堆页面 |
| UI 原型 | 只做必要页面,先保证操作顺畅 |
| AI 接入 | 把提示词模板、模型参数、错误处理封装起来 |
| 本地存储 | 明确数据保存位置、备份方式、迁移策略 |
| 测试验证 | 覆盖计算、转换、检索、状态流转等核心逻辑 |
| 发布使用 | 写清安装方式、权限说明和已知限制 |
Vibe Coding 的价值不在于“不会代码也能做任何系统”,而在于把很多长期停留在脑子里的小工具变成可运行版本。只要问题足够具体、边界足够清楚,再配合持续运行、验错、修正和收敛,它就能成为个人软件开发的一种实用工作流。