OpenClaw 可以被理解为一套 Agent Runtime(智能体运行时)加 Gateway(网关)的组合系统。
它并不是把用户输入直接交给 LLM(大语言模型),再把模型输出原样返回。真正的运行链路要复杂得多:外部消息进入系统后,需要经过协议适配、去重、路由、会话隔离、上下文组装、技能注入、模型推理、工具调用、结果投递和状态持久化。
用一个典型请求来贯穿整个过程:
在钉钉里发来一句:
帮我整理今天的重要邮件,提炼待办,
并生成一份给老板的简报
从用户视角看,这只是一句话;从系统视角看,它是一条需要被治理、调度、执行和保存的任务请求。
完整链路可以抽象成这样:
flowchart LR
A[钉钉 / 飞书 / Slack / Web] --> B[通道适配器]
B --> C[MsgContext]
C --> D[Gateway 入站分发]
D --> E[去重与命令拦截]
E --> F[路由到目标 Agent]
F --> G[生成 sessionKey]
G --> H[会话车道排队]
H --> I[组装上下文]
I --> J[LLM 推理]
J --> K[工具调用 / 子 Agent]
K --> J
J --> L[回复投递]
L --> M[会话与记忆持久化]
OpenClaw 的工程重点就在这条链路里。它关注的不是“模型能不能回答”,而是“这条消息如何稳定、可追踪、可扩展地被执行”。
整体架构:五层把 Agent 系统拆开
OpenClaw 的整体结构可以拆成五层:用户接口层、Gateway 核心层、消息处理层、扩展插件层和基础设施层。
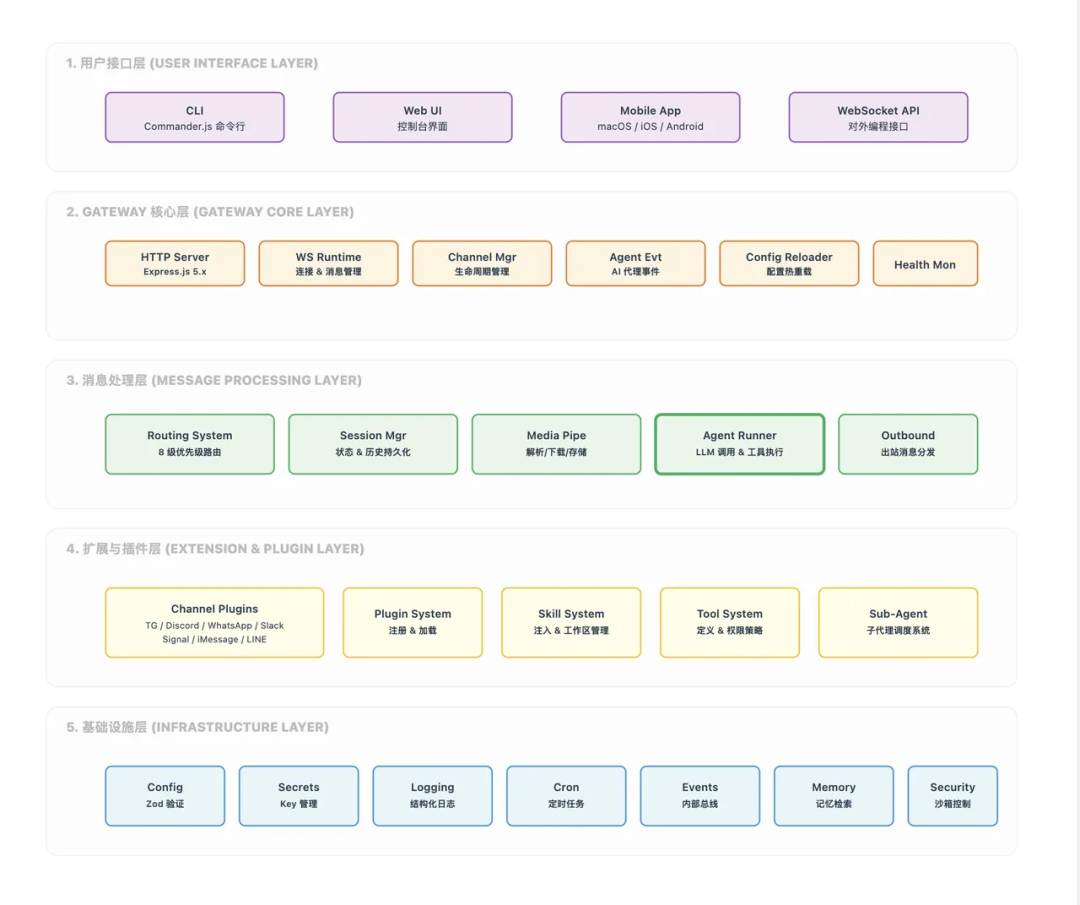
这张架构图的关键点在于:Agent 并不是系统中唯一重要的部分。真正支撑 Agent 长期运行的是外围的网关、路由、插件、记忆和运行时治理能力。
| 层级 | 职责 | 解决的问题 |
|---|---|---|
| 用户接口层 | CLI(命令行界面)、Web UI、移动端、WebSocket API(应用程序编程接口)等入口 | 把不同入口的用户操作收敛成系统请求 |
| Gateway 核心层 | 连接管理、配置加载、健康检查、请求接入 | 让系统能常驻运行、接收消息、维持状态 |
| 消息处理层 | Agent 执行器、路由系统、会话管理、媒体处理、出站投递 | 处理一条消息从进入到返回的主流程 |
| 扩展插件层 | 通道插件、Skills、Sub Agent | 对接新平台、新工具和多 Agent 协作 |
| 基础设施层 | 配置、密钥、日志、定时任务、事件总线、记忆检索、沙箱 | 保证系统稳定性、安全性和可维护性 |
这种分层的直接好处是边界清楚。比如新增一个 Slack 通道,理论上只需要扩展通道插件和配置,不应该改 Agent 执行器;新增一个技能,也不应该改 Gateway 的核心调度逻辑。
消息进门:先把平台差异收敛掉
不同平台的消息格式差异很大。
钉钉、飞书、Slack、Discord、WhatsApp、Telegram、WebSocket 都可能有自己的字段命名、线程结构、附件格式和用户身份体系。比如有的平台叫 message_id,有的平台叫 thread_ts,有的平台把引用消息、频道信息、群组信息嵌在复杂结构里。
如果 Agent 核心逻辑直接处理这些原始数据,很快会变成大量平台判断:
if (provider === "slack") {
// 处理 Slack 字段
} else if (provider === "dingtalk") {
// 处理钉钉字段
} else if (provider === "discord") {
// 处理 Discord 字段
}
这种写法会把平台差异污染到整个系统。
OpenClaw 的做法是把差异挡在入口:每个外部渠道都有对应的 ChannelPlugin,把原始消息转换成统一的内部消息对象 MsgContext。
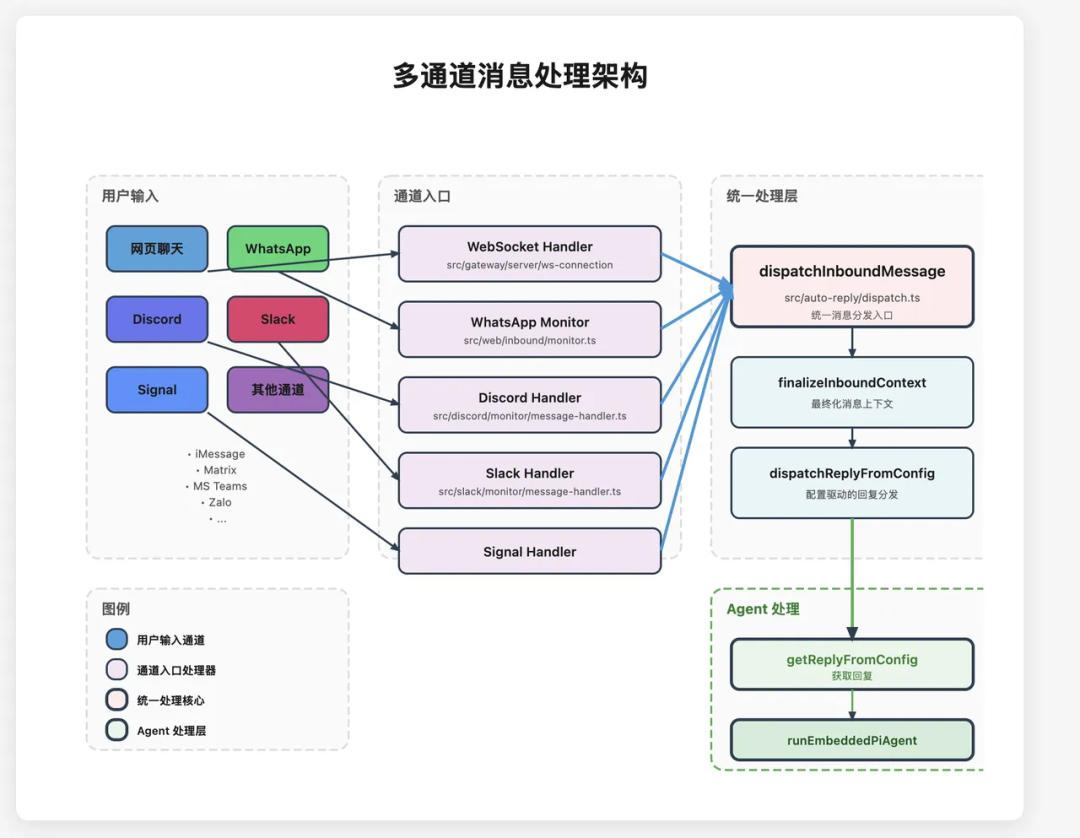
图里的核心思想是协议适配:平台消息只在入口处被解析,进入 Gateway 后就变成统一结构,后续模块只面向 MsgContext 编程。
MsgContext 大致包含这些字段:
interface MsgContext {
Body: string;
BodyForAgent?: string;
BodyForCommands?: string;
RawBody?: string;
SessionKey: string;
Provider: string;
Surface?: string;
ChatType?: "direct" | "group";
SenderId?: string;
SenderName?: string;
SenderUsername?: string;
OriginatingChannel?: string;
OriginatingTo?: string;
AccountId?: string;
MessageThreadId?: string;
CommandAuthorized?: boolean;
MessageSid?: string;
GatewayClientScopes?: string[];
}
几个字段比较关键:
| 字段 | 作用 |
|---|---|
Body | 标准化后的消息正文 |
BodyForAgent | 给 Agent 使用的正文,可能已经过滤命令或特殊标记 |
BodyForCommands | 给命令系统使用的正文 |
SessionKey | 会话标识,后续用于会话隔离和并发控制 |
Provider / OriginatingChannel | 消息来源平台 |
SenderId / SenderName | 发送者身份 |
MessageThreadId | 线程消息 ID,适合 Slack、Discord 等有线程概念的平台 |
MessageSid | 消息唯一 ID,用于去重 |
新增一个外部通道时,核心任务通常是四件事:
- 在 Registry 中声明通道元数据。
- 实现对应的
ChannelPlugin。 - 把插件注册到插件加载器。
- 补充配置 Schema、文档和测试。
核心系统不需要知道这个平台的所有细节,只需要相信插件会输出标准的 MsgContext。
入站分发:把所有消息收敛到统一入口
消息被适配后,会进入统一的入站分发函数。这个入口的意义不是处理复杂业务,而是让所有消息从同一个主开关进入运行链路。
核心结构可以简化成这样:
export async function dispatchInboundMessage(params) {
const finalized = finalizeInboundContext(params.ctx);
return await withReplyDispatcher({
dispatcher: params.dispatcher,
run: () =>
dispatchReplyFromConfig({
ctx: finalized,
cfg: params.cfg,
dispatcher: params.dispatcher,
replyOptions: params.replyOptions,
replyResolver: params.replyResolver,
}),
});
}
这里做了两件关键动作。
finalizeInboundContext 会对上下文做最终收束,包括补全字段、统一格式、修正不同插件之间的细节差异。通道插件已经做过一次适配,但进入主流程前仍然需要一道兜底标准化,避免某个插件输出的边缘字段影响后续模块。
withReplyDispatcher 则把后续执行包进回复分发器里。这样无论后面是同步返回、流式返回,还是执行过程中多次发送中间状态,都能走统一投递机制。
到这个位置,系统还没有让模型理解任务。它只是在确认:消息格式可靠,可以进入运行时主链路。
路由前置治理:去重、拦截和快速响应
消息进入主链路后,不会立即交给模型。OpenClaw 会先判断三件事:
- 这条消息有没有重复处理过。
- 它是不是控制命令。
- 是否需要先给前端返回开始执行的状态。
这些动作看起来不像 Agent 能力,却是生产系统必须处理的问题。
去重:防止同一条消息被执行两次
真实的消息平台经常会重复投递。Webhook(回调通知)可能因为超时重试,网络抖动也可能让同一条消息被系统收到两次。
如果没有幂等控制,后果可能不只是多回复一句话,而是重复调用工具、重复写数据库、重复触发外部 API,甚至重复扣费。
OpenClaw 会根据消息上下文生成一个幂等键:
export function buildInboundDedupeKey(ctx: MsgContext): string | null {
const provider = normalizeProvider(
ctx.OriginatingChannel ?? ctx.Provider ?? ctx.Surface
);
const messageId = ctx.MessageSid?.trim();
if (!provider || !messageId) {
return null;
}
const peerId = resolveInboundPeerId(ctx);
if (!peerId) {
return null;
}
const sessionKey = ctx.SessionKey?.trim() ?? "";
const accountId = ctx.AccountId?.trim() ?? "";
const threadId = ctx.MessageThreadId ? String(ctx.MessageThreadId) : "";
return [provider, accountId, sessionKey, peerId, threadId, messageId]
.filter(Boolean)
.join("|");
}
幂等键的格式可以理解为:
{provider}|{accountId}|{sessionKey}|{peerId}|{threadId}|{messageId}
几个例子:
whatsapp||main:+1234567890|msg_123
discord|default|agent:assistant:123|987654321||11223
slack|default|main:default|U12345678||C12345678
只要缓存里已经存在这个键,系统就直接停止后续处理。默认 TTL(生存时间)是 20 分钟,用来覆盖平台重试和短时间重复投递场景。
命令拦截:控制指令不应该进入模型推理
并不是所有消息都应该交给 Agent。比如:
/stop
这类消息更像运行时控制命令。它要做的是中断当前任务,而不是让模型解释“stop 是什么意思”。
OpenClaw 会在前置阶段识别控制命令,并触发对应的 AbortController。这说明它不是一个简单的聊天壳,而是一个长期运行的任务系统。长期任务需要启动、取消、超时、清理等控制能力。
快速响应:先告诉用户任务已经开始
Web 请求和 WebSocket 场景下,模型推理和工具调用可能持续几秒甚至几十秒。如果前端一直等最终结果,用户会以为系统卡住了。
OpenClaw 通常会先返回一个 started 状态,再异步执行后续任务:
sequenceDiagram
participant U as 用户界面
participant G as Gateway
participant R as Runtime
U->>G: 发送消息
G-->>U: started
G->>R: 异步执行 Agent 任务
R-->>G: 流式输出 / 最终结果
G-->>U: 返回结果
这个状态不负责回答问题,只负责确认任务已进入执行队列。
路由系统:决定这条消息交给哪个 Agent
前置治理完成后,系统要确定目标 Agent。OpenClaw 对内部 Web 通道和外部通道采用不同策略。
Web 内部通道:直接使用 sessionKey
Web 客户端通常可以传入明确的 sessionKey,格式一般是:
{agentId}:{scope}
例如:
assistant:main
这种场景下,系统可以直接知道消息属于哪个 Agent、哪个会话范围,不需要再根据外部平台绑定规则反查。
外部通道:根据绑定规则匹配 Agent
Slack、WhatsApp、Discord、钉钉这类外部平台并不知道 OpenClaw 内部的 Agent 组织方式,所以要靠配置规则做绑定。
配置可以像这样:
{
"bindings": [
{
"agentId": "assistant",
"match": {
"channel": "whatsapp",
"accountId": "my_bot"
}
},
{
"agentId": "vip-assistant",
"match": {
"channel": "whatsapp",
"peer": {
"id": "+1234567890"
}
}
}
]
}
匹配维度通常包括:
| 维度 | 示例 |
|---|---|
| 通道 | whatsapp、slack、discord |
| 账户 ID | 同一平台下的不同机器人账号 |
| 用户或群组 | 某个私聊用户、某个群 |
| Discord 服务器 | 指定 guild |
| 团队 ID | Slack workspace 或企业组织 |
| 角色列表 | Discord 角色、企业内部角色 |
匹配优先级可以理解为从精确到宽泛:
| 优先级 | 匹配方式 |
|---|---|
| 1 | 精确用户或群组匹配 |
| 2 | Discord 服务器 + 角色匹配 |
| 3 | Discord 服务器匹配 |
| 4 | 通道账户级匹配 |
| 5 | 通道级匹配 |
| 6 | 默认 Agent |
回到钉钉消息的例子,系统会先识别消息来自哪个通道、哪个账号、哪个用户或群,再根据绑定规则决定交给 assistant、support-agent、vip-assistant 还是其他专用 Agent。
sessionKey:会话隔离和并发控制的基础
Agent 确定后,系统会构造 sessionKey。常见格式仍然是:
{agentId}:{scope}
一些例子:
assistant:main
assistant:whatsapp:direct:+1234567890
assistant:discord:channel:987654321
support:telegram:group:-1001234567890
sessionKey 后面承担两个核心职责:
- 标识这条消息属于哪个 Agent 的哪条会话。
- 控制同一会话内消息的执行顺序。
用户看到的是一句话,系统管理的是一个带身份、来源、会话范围和执行顺序的任务。
会话车道:同一会话串行,全局并发受控
路由完成后,系统仍然不会马上执行。原因是同一会话里多条消息如果并行跑,容易造成上下文错乱。
比如用户连续发送两条消息:
帮我整理今天的重要邮件
顺便把待办改成按优先级排序
如果两条消息同时执行,可能出现第二条先完成、第一条后完成的情况。这样模型看到的历史、工具调用状态和最终回复顺序都会乱。
OpenClaw 使用会话车道机制解决这个问题:
flowchart TD
A[入站消息] --> B{根据 sessionKey 分配车道}
B --> C[sessionKey = assistant:main]
B --> D[sessionKey = support:telegram:group]
C --> C1[消息 1]
C1 --> C2[消息 2]
C2 --> C3[消息 3]
D --> D1[消息 A]
D1 --> D2[消息 B]
C3 --> E[全局并发控制]
D2 --> E
E --> F[Agent Runtime 执行]
会话车道有两层约束:
| 控制层 | 作用 |
|---|---|
| 会话级车道 | 相同 sessionKey 的消息串行执行,避免同一对话乱序 |
| 全局级车道 | 限制整个系统同时执行的任务数量,防止运行时被打满 |
这是一种运行时治理能力。它不依赖模型“自己记住顺序”,而是在系统层面保证同一会话只有一条消息占用执行上下文。
上下文组装:模型看到的不是一句话
进入 Agent 执行阶段后,最关键的步骤是组装上下文。
很多人理解 Agent 时,会把流程想成:
用户输入 -> 模型理解 -> 工具调用 -> 输出结果
实际运行时,模型看到的内容远不止用户刚刚输入的一句话。OpenClaw 会按顺序拼出一整套上下文:
系统提示词 -> Skills 提示 -> 对话历史 -> 当前消息
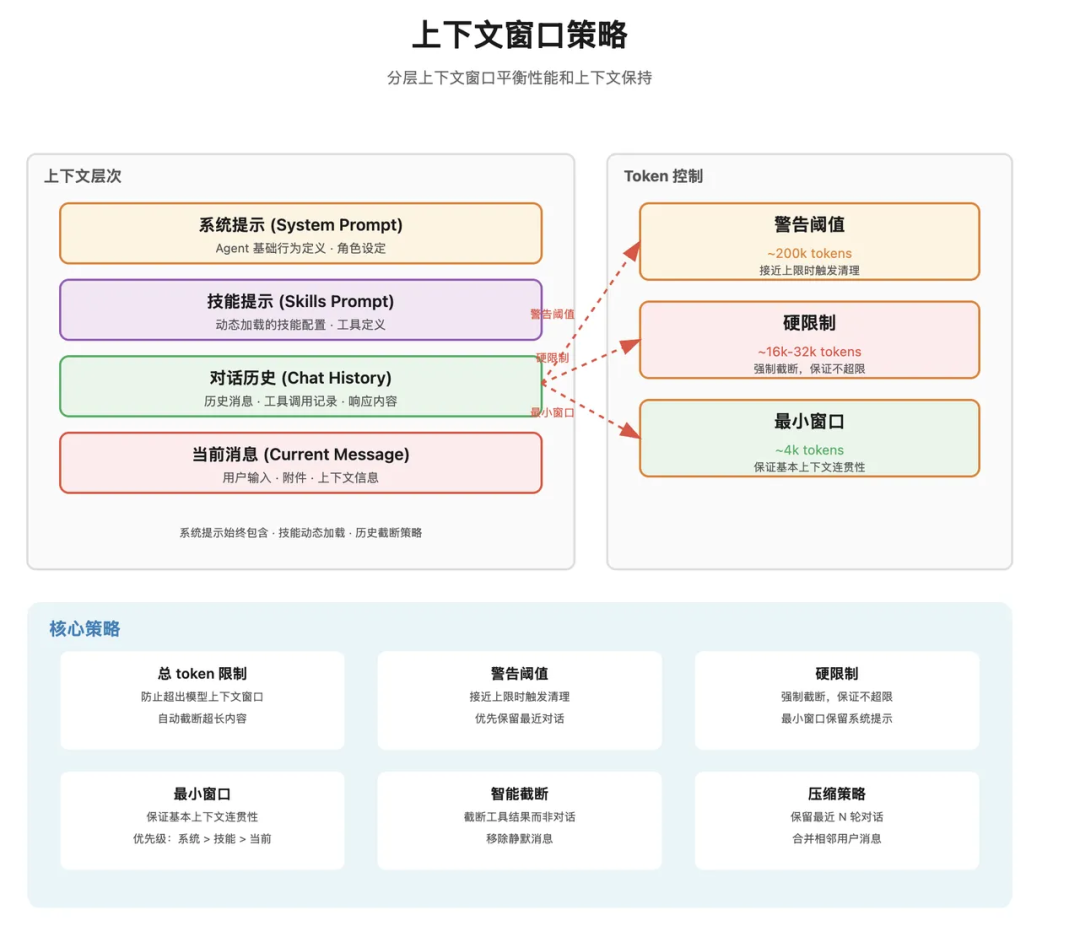
这张图表达的是模型输入的层级关系:模型先知道自己的身份和规则,再知道自己有哪些技能,然后读取历史,最后处理当前请求。
| 上下文部分 | 作用 |
|---|---|
| 系统提示词 | 定义 Agent 身份、行为边界、安全规则 |
| Skills 提示 | 告诉模型可用能力、使用方式和限制 |
| 对话历史 | 让模型理解当前消息之前发生了什么 |
| 当前消息 | 用户本次请求及其元数据 |
Bootstrap 文件:把 Agent 身份文件化
OpenClaw 没有把系统提示词完全硬编码在程序里,而是通过工作区里的 Bootstrap 文件注入。
默认工作区通常位于:
~/.openclaw/workspace
常见文件包括:
| 文件 | 作用 |
|---|---|
AGENTS.md | Agent 行为规则和工具使用指南 |
SOUL.md | 个性、语气或人格设定 |
TOOLS.md | 工具使用说明 |
IDENTITY.md | 身份标识信息 |
USER.md | 用户偏好 |
HEARTBEAT.md | 心跳检测提示 |
BOOTSTRAP.md | 初始化引导 |
MEMORY.md / memory.md | 长期记忆入口 |
模型在处理“整理邮件、提炼待办、生成简报”之前,会先被告知:
你是谁
你应该遵守什么规则
你能调用哪些工具
用户偏好是什么
系统长期记忆里有哪些信息
这使得 OpenClaw 中的 Agent 不是每次从零开始聊天,而是从一个被配置和记忆塑造过的身份出发。
记忆召回不是“让模型自己想起来”
系统提示词里会明确规定记忆检索规则。类似这样的规则会被注入:
## Memory Recall
Before answering anything about prior work, decisions, dates, people, preferences, or todos:
run memory_search on MEMORY.md + memory/*.md; then use memory_get to pull only needed lines.
If low confidence after search, say you checked.
这段规则很重要。它没有要求模型“尽量记住”,而是把记忆变成显式动作:
涉及历史工作、决策、日期、人物、偏好、待办时,
先执行 memory_search,
再用 memory_get 拉取必要内容。
这种设计把记忆从模型上下文里的模糊残留,变成可检索、可控制的外部机制。
提示词注入要受上下文预算约束
Bootstrap 文件、记忆文件、工具说明都会消耗 token。OpenClaw 会限制:
- 单个文件最大字符数。
- 总注入字符数。
- 截断时是否显示警告。
这说明系统不会把所有内容无脑塞给模型。上下文窗口是有限资源,系统提示词本身也必须被预算管理。
Skills:不是函数列表,而是能力说明加调用边界
Skills 是 OpenClaw 里最容易被误解的部分。它不是简单的一组函数,也不是普通工具列表。更准确地说,Skills 是一套“告诉 Agent 如何使用能力”的方法包。
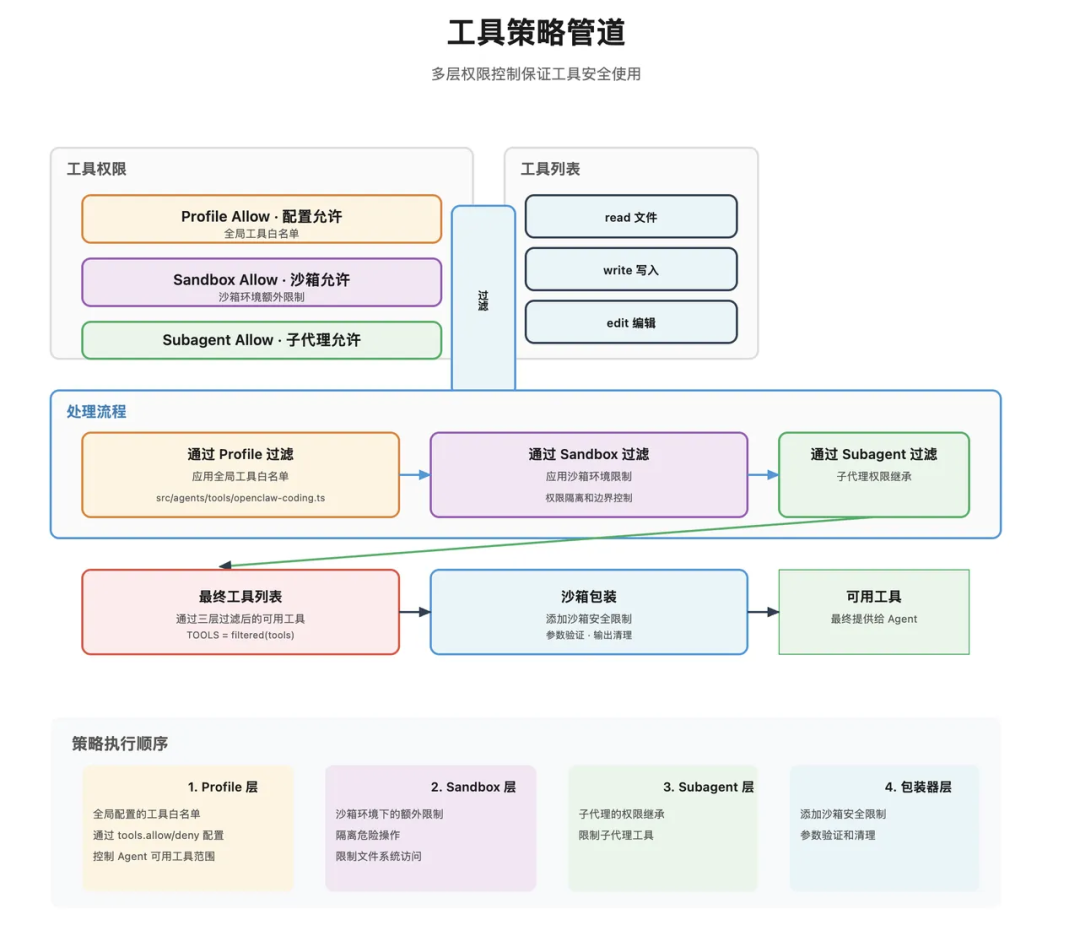
图里的流程可以理解为:系统先发现技能,再根据当前环境过滤和检查权限,最后把可用技能描述注入上下文。模型在推理时根据这些描述决定是否调用真实工具。
Skills 的加载通常经历四步。
发现技能
系统会从多个位置扫描技能文件:
| 来源 | 含义 |
|---|---|
| 工作区目录 | 当前项目或当前 Agent 专属技能 |
| 用户全局目录 | 用户级可复用技能 |
| 内置目录 | OpenClaw 默认提供的技能 |
| 插件目录 | 插件扩展出来的技能 |
过滤技能
发现到的技能不一定都能用。过滤条件可能包括:
- 当前平台。
- 当前消息通道。
- 发送者权限。
- 黑名单和白名单配置。
- Agent Profile 配置。
例如,某个技能只允许 Web 内部通道使用,不应该暴露给外部群聊;某个邮件技能只允许授权用户触发,不应该被普通群成员调用。
安全检查
OpenClaw 对 Skills 有多层安全策略:
| 策略 | 作用 |
|---|---|
| Profile 过滤 | 根据 Agent 配置决定技能是否可见 |
| Sandbox 隔离 | 把高风险执行放进受限环境 |
| Sub Agent 继承 | 子 Agent 是否能继承主 Agent 的能力由配置决定 |
一个技能能不能用,不只取决于它是否存在,还取决于当前 Agent、当前通道、当前用户和当前安全边界。
生成技能提示词
通过检查后的技能会被格式化成提示文本,注入模型上下文。
一个技能描述可以抽象成这样:
## skill: mail_summary
适用场景:
- 读取当天邮件
- 提取重要事项
- 汇总待办和责任人
使用限制:
- 只能读取授权邮箱
- 涉及敏感邮件时需要返回摘要,不暴露原始全文
可调用工具:
- mail.search
- mail.get
- doc.create
当用户说“整理今天的重要邮件,提炼待办,并生成给老板的简报”时,模型会根据 Skills 判断:
- 是否存在邮件检索能力。
- 是否存在摘要和待办提取能力。
- 是否存在文档生成能力。
- 是否需要拆分任务交给子 Agent。
Skills 的价值不只是“能调用工具”,而是让模型知道工具什么时候该用、怎么用、有什么边界。
Memory 和会话历史:轻量索引加重度转录
OpenClaw 的记忆系统分成两类:会话历史和长期记忆。会话历史记录对话过程,长期记忆保存跨会话可复用的信息。
会话历史采用双层存储结构。
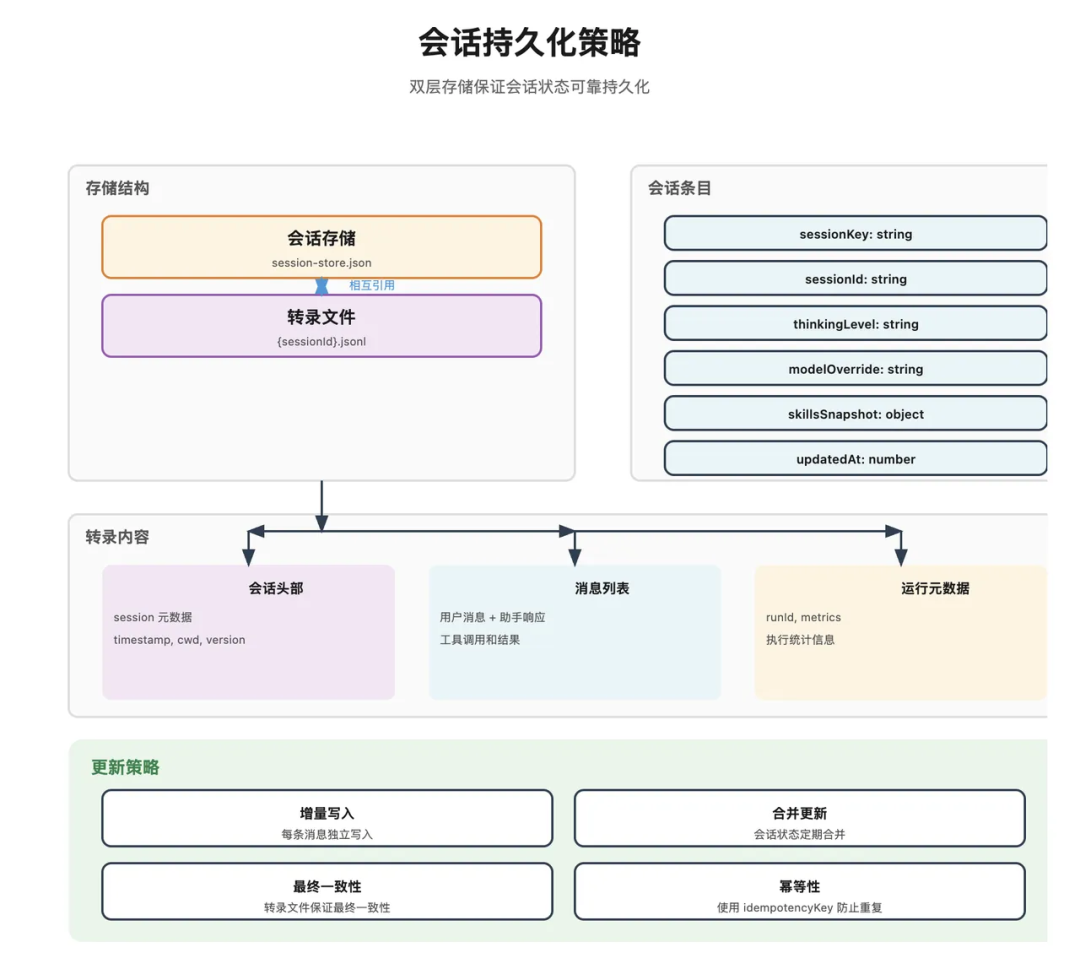
图里展示的是轻量索引和完整转录的分工:sessions.json 负责快速找到会话元数据,具体对话内容放在对应的 JSON Lines 文件里。
sessions.json:保存会话元数据
sessions.json 通常位于:
~/.openclaw/agents/{agentId}/sessions/sessions.json
它保存的是轻量元数据,例如:
{
"sessions": [
{
"sessionId": "01HRX8Y2...",
"sessionKey": "assistant:main",
"transcriptPath": "01HRX8Y2.jsonl",
"updatedAt": "2026-03-16T08:00:00.000Z",
"modelOverride": null,
"skillsSnapshot": ["mail_summary", "doc_writer"]
}
]
}
这些信息适合快速检索、恢复会话和定位转录文件。
JSONL 转录:保存完整对话过程
完整会话内容放在 {sessionId}.jsonl 里。JSON Lines(逐行 JSON)的特点是每一行都是一个独立 JSON 对象,适合追加写入和流式读取。
示例:
{"role":"user","content":"帮我整理今天的重要邮件","createdAt":"2026-03-16T08:01:00.000Z"}
{"role":"assistant","content":"我会先检索今天的邮件,再提取待办。","createdAt":"2026-03-16T08:01:01.000Z"}
{"role":"tool","name":"mail.search","content":"找到 18 封邮件,其中 5 封高优先级","createdAt":"2026-03-16T08:01:03.000Z"}
这种设计把“会话列表”和“完整内容”拆开,避免每次加载会话索引时读入大量历史文本。
历史加载:按 token 预算取最近上下文
模型调用前,系统会从转录文件中加载历史消息。加载过程通常会做几件事:
- 从最新消息向前读取。
- 控制历史轮数或 token 数量。
- 过滤不需要放回模型的消息类型。
- 恢复正确时间顺序。
- 估算历史内容占用的 token。
真正送进模型的历史不是“全部聊天记录”,而是在上下文预算内选出的最近有效片段。
上下文压缩:防止提示词和历史把窗口撑爆
当系统提示词、Skills、记忆、历史记录、当前消息和工具结果都进入上下文后,窗口迟早会接近模型限制。
OpenClaw 需要一套防爆机制。
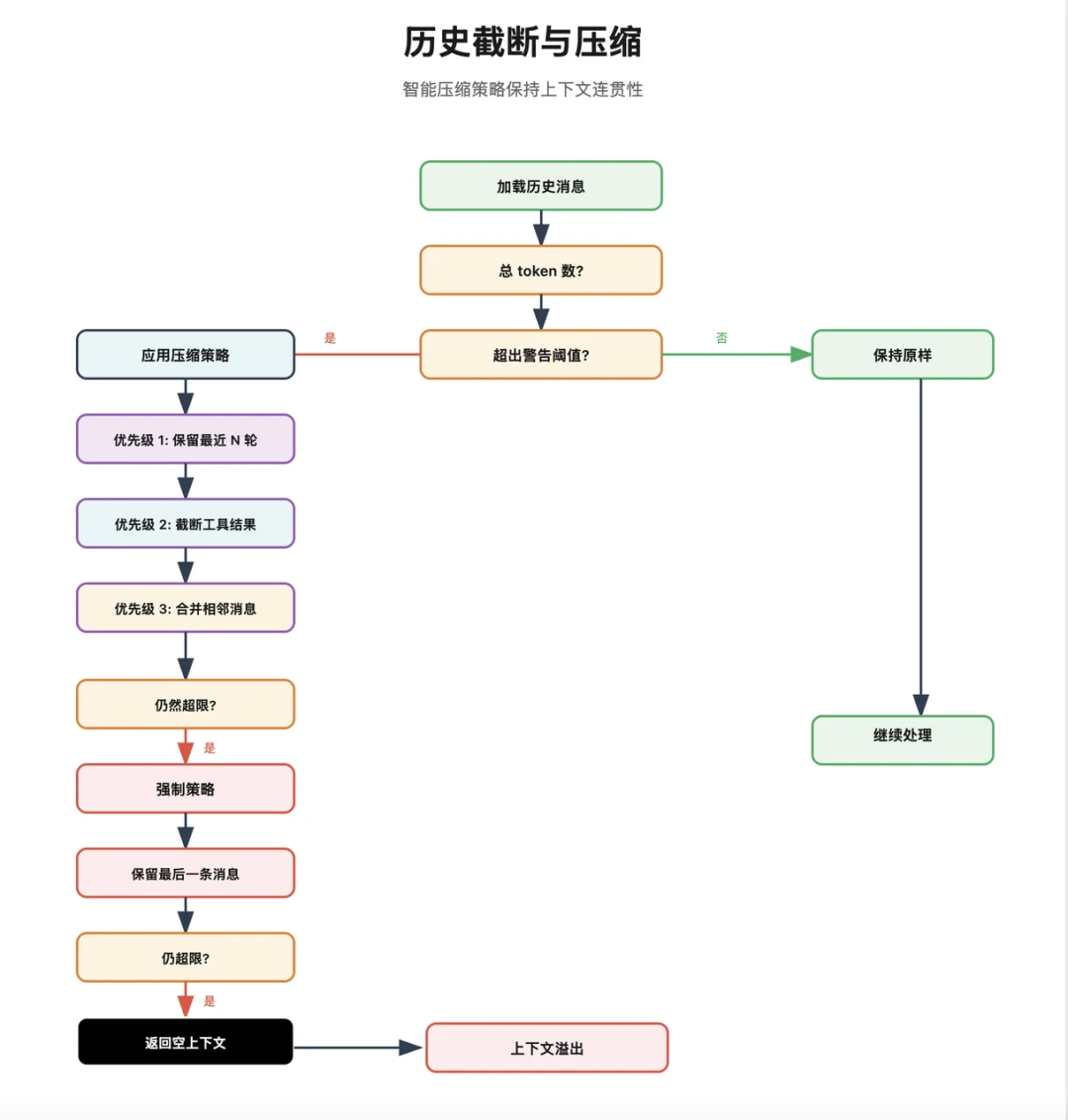
图里关注的是上下文窗口管理:历史轮次限制、工具结果截断、摘要压缩和降级策略共同保证模型调用不会因为输入过大而失败。
历史轮次限制
最直接的方式是限制保留历史轮数。系统从最新消息向前扫描,超过限制的早期消息不再注入。
这种策略简单可靠,但缺点是可能丢失早期的重要决策,所以只适合做第一层保护。
工具结果截断
工具调用结果经常比用户输入大得多,例如:
- 多页网页内容。
- 大段日志。
- 长 JSON。
- 邮件全文。
- 搜索结果列表。
如果把工具输出完整塞回模型,很容易直接超出上下文窗口。
OpenClaw 会对工具结果做截断。常见策略有两类:
| 策略 | 适合内容 |
|---|---|
| 只保留开头 | 普通长文本、网页正文 |
| 头尾保留 | 日志、错误堆栈、JSON 结构、命令输出 |
头尾保留很实用,因为日志和错误信息经常出现在末尾,只保留开头可能会丢掉真正重要的失败原因。
自动摘要压缩
当上下文仍然接近上限时,系统会把早期历史分块摘要,用摘要替代完整历史,同时保留最近几轮原文。
摘要需要保留的信息包括:
- 当前仍在进行的任务。
- 已经完成的操作。
- 用户最后的明确请求。
- 已作出的决策。
- 后续步骤依赖的信息。
- 工具调用产生的关键结果。
这不是机械裁剪,而是语义压缩。它尽量保留“继续完成任务所需的信息”,丢掉不影响执行的细节。
容错与降级
如果压缩后仍然超限,系统还可以继续降级:
- 减少历史轮数。
- 缩短工具结果。
- 降低 Bootstrap 文件注入量。
- 只保留必要 Skills。
- 要求模型先基于已有信息继续,必要时再检索记忆或调用工具。
上下文管理的目标不是让模型看到所有东西,而是让模型看到完成当前任务所需的最小充分信息。
Runtime 执行:流式输出、工具调用和持久化闭环
上下文准备好后,Agent Runtime 才真正开始执行任务。
执行过程可以看成一个循环:
sequenceDiagram
participant U as 用户
participant G as Gateway
participant L as 会话车道
participant R as Agent Runtime
participant M as LLM
participant T as Tool / Skill
participant S as Storage
U->>G: 发送消息
G->>L: 根据 sessionKey 入队
L->>R: 获得执行权
R->>S: 读取 Bootstrap / Memory / History
R->>M: 发送完整上下文
M-->>R: 生成中间输出或工具调用意图
R->>T: 执行工具
T-->>R: 返回工具结果
R->>M: 注入工具结果继续推理
M-->>R: 最终回复
R->>G: 流式投递结果
R->>S: 追加转录与更新记忆
G-->>U: 返回响应
Runtime 负责的不只是“调用一次模型”。
| Runtime 职责 | 说明 |
|---|---|
| 上下文读取 | 加载系统提示词、Skills、历史、记忆 |
| 模型调用 | 向 LLM 提交完整上下文 |
| 流式输出 | 把生成过程中的 token 或阶段性状态投递给前端 |
| 工具调用 | 根据模型请求调用真实工具 |
| 子 Agent 调度 | 复杂任务可拆给子 Agent |
| 中断控制 | 响应 /stop 等控制命令 |
| 结果持久化 | 记录会话转录、工具结果和最终回复 |
| 资源清理 | 释放执行状态、取消信号、临时文件等 |
对于“整理邮件并生成简报”这个任务,Runtime 可能会经历这样的步骤:
1. 模型判断需要读取邮件。
2. Runtime 调用邮件检索工具。
3. 工具返回当天邮件列表。
4. 模型判断哪些邮件重要。
5. Runtime 根据需要读取若干邮件详情。
6. 模型提取待办、负责人、截止时间。
7. Runtime 调用文档生成工具。
8. 模型生成给老板的简报。
9. Gateway 把结果投递回钉钉。
10. 会话历史和必要记忆被保存。
这套机制让 Agent 不再是一次性问答,而是一个可持续执行、可中断、可恢复的任务运行过程。
多 Agent 协作:主 Agent 负责任务组织,子 Agent 负责局部执行
复杂任务不一定适合由一个 Agent 从头处理到尾。
比如“整理邮件、提炼待办、生成老板简报”可以拆成几个子任务:
| 子任务 | 更适合的执行者 |
|---|---|
| 检索和筛选邮件 | 邮件分析 Agent |
| 提取待办和风险 | 任务管理 Agent |
| 写老板简报 | 写作 Agent |
| 检查格式和语气 | 审校 Agent |
OpenClaw 的多 Agent 协作可以理解为:主 Agent 负责判断任务结构,必要时 spawn 子 Agent;子 Agent 在受限上下文和受控技能集内完成局部任务,再把结果返回给主 Agent 汇总。
flowchart TD
A[用户请求] --> B[主 Agent]
B --> C{是否需要拆分任务}
C -- 否 --> D[主 Agent 直接完成]
C -- 是 --> E[创建子 Agent 任务]
E --> F[邮件分析 Agent]
E --> G[待办提取 Agent]
E --> H[简报写作 Agent]
F --> I[邮件摘要]
G --> J[待办列表]
H --> K[简报草稿]
I --> L[主 Agent 汇总]
J --> L
K --> L
L --> M[最终回复]
多 Agent 协作最重要的不是“多开几个模型实例”,而是边界控制。
子 Agent 需要独立上下文
子 Agent 不应该无脑继承主 Agent 的全部上下文。它通常只需要:
- 当前子任务描述。
- 必要的背景信息。
- 被授权的 Skills。
- 对应的安全规则。
- 输出格式要求。
这样可以减少 token 消耗,也能避免子 Agent 接触不该使用的工具或记忆。
子 Agent 的配置可以继承,也可以覆盖
多 Agent 系统里,如果每个子 Agent 都完整复制一份配置,会导致配置爆炸。更合理的方式是:未单独定义的配置回落到全局默认值,特定子 Agent 只覆盖自己需要的部分。
可以抽象成这样:
{
"defaults": {
"model": "gpt-4.1",
"temperature": 0.2,
"maxTokens": 8000,
"skills": ["memory_search", "memory_get"]
},
"subagents": {
"mail-agent": {
"skills": ["mail.search", "mail.get", "memory_search"]
},
"writer-agent": {
"temperature": 0.5,
"skills": ["doc.create", "style.check"]
}
}
}
mail-agent 只覆盖技能列表,模型等配置继承默认值;writer-agent 覆盖了温度和技能,用来适配写作任务。
多 Agent 适合和不适合的场景
| 场景 | 是否适合多 Agent | 原因 |
|---|---|---|
| 单轮简单问答 | 不适合 | 拆分成本高于收益 |
| 明确分工的复杂任务 | 适合 | 检索、分析、写作、审校可以并行或串行协作 |
| 高风险工具执行 | 适合 | 可以把危险能力隔离到专用 Agent |
| 强依赖统一上下文的推理 | 谨慎使用 | 拆分后可能丢失全局语义 |
| 多渠道客服分流 | 适合 | 不同 Agent 可以处理不同客户、语言或业务线 |
多 Agent 的价值在于任务拆解和权限隔离,而不是为了形式上“看起来更智能”。
一条钉钉消息在 OpenClaw 里的完整旅程
把所有模块串起来,那句钉钉消息会经历这样的路径:
用户在钉钉发送消息
↓
钉钉通道插件接收原始事件
↓
插件把平台消息转换成 MsgContext
↓
Gateway 对入站上下文做最终化处理
↓
系统生成幂等键,检查是否重复
↓
命令系统判断是否为 /stop 等控制命令
↓
WebSocket 或前端通道收到 started 状态
↓
路由系统根据绑定规则找到目标 Agent
↓
系统生成 sessionKey
↓
消息进入对应会话车道排队
↓
Agent Runtime 获得执行权
↓
加载 Bootstrap、Memory、Skills、历史记录和当前消息
↓
上下文预算检查,必要时压缩历史和工具结果
↓
LLM 开始推理
↓
Runtime 根据模型意图调用工具或子 Agent
↓
工具结果回填给模型继续推理
↓
主 Agent 生成最终答复
↓
回复分发器把结果投递回钉钉
↓
会话转录写入 JSONL
↓
sessions.json 更新元数据
↓
必要信息进入长期记忆或索引
↓
运行时释放资源
这条链路体现出 OpenClaw 的核心设计:把一次用户输入变成一个可治理的任务生命周期。
OpenClaw 的工程取舍
OpenClaw 的设计价值可以从几个角度看。
| 设计点 | 解决的问题 | 代价 |
|---|---|---|
| 通道插件 | 隔离平台差异,新增通道不用改核心逻辑 | 插件规范要设计清楚 |
| MsgContext | 统一内部消息模型 | 适配阶段需要补齐大量边缘字段 |
| 幂等键 | 防止重复投递导致重复执行 | 依赖平台提供可靠消息 ID |
| 会话车道 | 保证同一会话上下文不乱序 | 同一会话吞吐会被串行限制 |
| Bootstrap 文件 | Agent 身份和规则可配置 | 需要控制提示词大小 |
| Skills 系统 | 让模型理解能力边界和调用方式 | 技能描述质量会影响调用效果 |
| Memory 检索 | 把历史记忆变成显式动作 | 需要维护索引和召回质量 |
| 上下文压缩 | 防止窗口爆掉 | 摘要可能丢失细节 |
| 多 Agent | 支持任务拆解和权限隔离 | 调度复杂度和 token 成本会上升 |
OpenClaw 更像一个 Agent 网关和运行时,而不是一个单纯的聊天应用。它把消息入口、会话治理、上下文管理、技能调用、持久化存储和多 Agent 协作放进同一条工程链路里。
如果要自己实现一个 Mini-OpenClaw,最小闭环可以从这几块开始:
flowchart LR
A[统一消息结构 MsgContext] --> B[路由到 Agent]
B --> C[sessionKey 会话隔离]
C --> D[上下文组装]
D --> E[LLM 调用]
E --> F[工具调用]
F --> E
E --> G[回复投递]
G --> H[会话持久化]
先把这条最小链路跑通,再逐步加入幂等、车道、Skills 过滤、Memory 检索、上下文压缩和多 Agent 调度,系统会比一开始就堆满复杂功能更容易维护。