OpenFang 是一个面向生产环境的 Agent 工作流框架,目标不是单纯让大语言模型回答问题,而是把多个 AI 能力、工具调用、任务调度和安全约束组织成一套可以长期运行的自动化系统。
普通 Agent 通常更像“单次任务执行器”:给它一个问题,它调用模型和工具完成一次响应。任务结束后,流程也随之结束。如果每天都要重复做同一件事,例如监控竞品动态、整理行业资讯、剪辑视频、生成线索名单,就需要人不断触发、检查、补救。
OpenFang 解决的是另一类问题:把这些重复流程做成可复用、可调度、可观测、可限制权限的运行单元。它的核心抽象叫 Hands。
OpenFang 解决的核心问题
Agent 真正进入日常工作流时,麻烦往往不在“能不能回答”,而在下面几件事:
| 问题 | 传统 Agent 的常见表现 | OpenFang 的处理思路 |
|---|---|---|
| 任务需要持续运行 | 每次都要人工触发 | 通过 Hands 配置周期性或事件驱动流程 |
| 工具调用分散 | 浏览器、文件、平台接口各自配置 | 把工具权限封装进 Hand |
| 过程不可控 | 很难知道 Agent 做过什么 | 通过指标和审计记录跟踪运行过程 |
| 安全边界模糊 | Agent 拿到权限后容易越界 | 用沙箱、权限控制、人工确认限制高风险操作 |
| 结果难以复用 | 每次提示词和上下文都可能变化 | 把计划、知识和输出规范固化成能力包 |
可以把 OpenFang 理解成一个 Agent 运行时:它负责调度任务、执行工具、记录过程、约束权限;大语言模型只是其中的推理组件之一。
flowchart LR
A[目标或触发条件] --> B[Hand]
B --> C[运行计划]
B --> D[专家知识库]
B --> E[工具权限]
B --> F[指标与审计]
C --> G[执行任务]
D --> G
E --> G
G --> H[结果输出]
G --> I[运行记录]
F --> I
Hands:比普通 Agent 更接近“自动化岗位”
Hands 是 OpenFang 中最重要的设计。它不是一个简单提示词模板,而是一个预构建的自主能力包。一个 Hand 内部通常包含四类东西:
- 运行计划:定义任务怎么拆、按什么顺序执行、什么时候触发。
- 专家知识库:让任务在特定领域内有稳定的背景知识和判断标准。
- 工具调用权限:规定它能使用哪些工具,例如浏览器、文件系统、平台 API。
- Dashboard 指标:记录运行状态、成功率、失败原因、产出数量等信息。
Hands 的作用可以用下面这张图来理解:

图中的重点不在于“Agent 会调用更多工具”,而在于任务边界被提前封装好了。一个 Hand 被激活后,不需要每一步都等待人工输入,它会按照预设流程推进任务,并把中间过程和最终结果记录下来。
普通 Agent 和 Hands 的差异可以这样对比:
| 维度 | 普通 Agent | OpenFang Hands |
|---|---|---|
| 工作方式 | 接收一次指令,完成一次任务 | 按预设流程持续运行 |
| 上下文管理 | 依赖当前会话 | 内置知识库和运行计划 |
| 工具权限 | 通常临时授权或全局配置 | 每个 Hand 单独定义 |
| 可观测性 | 多数只看最终回答 | 可以看运行指标和审计记录 |
| 适合任务 | 问答、单次分析、临时生成 | 监控、调研、剪辑、线索挖掘等重复流程 |
下面这张图展示了 Hands 和传统 Agent 在工作模式上的区别:

这类抽象的价值在于,Agent 不再只是聊天窗口里的助手,而是被封装成一个具有职责、权限、流程和产出规范的自动化模块。
内置 Hands 能做什么
OpenFang 当前内置了多个 Hands,覆盖监控、销售线索、研究、视频处理和浏览器自动化等场景。几个代表性的能力如下:
| Hand | 主要用途 | 典型输出 |
|---|---|---|
| Collector | 持续监控指定目标,例如竞品动态、舆情变化、行业信息 | 告警、摘要、知识图谱 |
| Lead | 自动发现潜在客户,做网络调研、打分、去重 | CSV、Markdown 线索列表 |
| Researcher | 做深度主题调研,并对多来源信息交叉验证 | 带引用的研究报告 |
| Clip | 处理视频素材,识别高光片段、剪竖屏短视频、加字幕、生成封面 | 可发布的短视频素材 |
| Browser | 在网页中执行点击、填写表单等操作 | 自动化网页操作结果 |
这几类 Hand 对应的不是“模型能力”,而是完整业务动作。例如 Clip 不是简单让模型描述视频内容,而是把视频处理拆成多个阶段:分析素材、定位片段、生成字幕、转换比例、封装输出,必要时还可以连接发布平台。
flowchart TD
A[上传视频] --> B[识别内容与高光片段]
B --> C[裁剪为短视频]
C --> D[转为竖屏比例]
D --> E[生成字幕]
E --> F[生成封面]
F --> G[发布或导出]
Browser 这类能力尤其需要安全限制。它可以帮助处理网页上的重复操作,但涉及付款、下单、转账等高风险行为时,应该停下来等待人工确认,而不是让 AI 自行决定。
自定义 Hand:用 HAND.toml 固化流程
除了直接使用内置 Hands,也可以为自己的业务创建专属 Hand。核心入口是一个 HAND.toml 配置文件,用来声明这个 Hand 的目标、工具、参数和提示词。
一个简化后的结构可以写成这样:
name = "daily-ai-briefing"
description = "每天收集 AI 领域重要动态,并生成摘要报告"
schedule = "0 8 * * *"
[model]
provider = "openai"
model = "gpt-4.1"
[tools]
browser = true
rss = true
filesystem = true
[permissions]
write_files = true
post_to_platform = false
require_human_approval_for = ["payment", "publish"]
[prompt]
system = """
你是一个 AI 行业研究助手。
每天收集指定来源中的重要信息,过滤重复内容,
按照事件、产品、论文、开源项目四类生成摘要。
"""
[output]
format = "markdown"
path = "./reports/daily-ai-briefing.md"
真实项目中的配置会更复杂,但基本思路一致:把一个经常重复的任务,从“每次临时写提示词”变成“可版本管理、可复用、可审计的配置”。
自定义 Hand 的运行链路可以概括为:
sequenceDiagram
participant User as 使用者
participant Config as HAND.toml
participant Runtime as OpenFang Runtime
participant LLM as 大语言模型
participant Tools as 工具集合
participant Audit as 审计与指标
User->>Config: 定义目标、工具、权限、输出格式
Config->>Runtime: 加载 Hand
Runtime->>LLM: 请求规划与推理
Runtime->>Tools: 按权限调用工具
Tools-->>Runtime: 返回执行结果
Runtime->>Audit: 记录操作与指标
Runtime-->>User: 输出报告或任务结果
这种方式适合把团队内部的固定流程沉淀下来。例如每天生成竞品报告、每周整理客户线索、定时检查站点内容变更,都可以做成独立 Hand。
安全机制:Agent 权限越大,边界越要清楚
Hands 能自动调用浏览器、处理文件、连接外部服务,权限明显比普通聊天式 Agent 更大。权限扩大后,系统必须解决三个问题:
- 工具执行出错时,不能影响主进程和宿主系统。
- 每一步操作要能追踪,不能只看到最后失败。
- 涉及资金、发布、删除等高风险动作时,不能完全交给 AI 决策。
OpenFang 为此设计了多层安全机制,其中几个关键点包括:
- WASM 沙箱:工具代码运行在 WebAssembly(WASM)沙箱中,降低对主系统的影响。
- 哈希链审计:操作记录通过哈希链串起来,便于追踪执行过程和定位异常。
- 人工确认:涉及消费、交易等动作时,需要人工确认后才能继续。
- 权限隔离:不同 Hand 拥有不同工具权限,避免一个任务拿到不必要的能力。
安全体系可以参考下面这张图:

这里的关键不是堆安全名词,而是把约束放进执行架构里。Agent 每调用一个工具、写入一个文件、触发一个外部动作,都应该受到权限和审计系统管理。
flowchart TD
A[Hand 发起操作] --> B{是否有工具权限}
B -- 否 --> C[拒绝执行并记录]
B -- 是 --> D[进入 WASM 沙箱]
D --> E{是否高风险操作}
E -- 是 --> F[等待人工确认]
F --> G{人工是否批准}
G -- 否 --> C
G -- 是 --> H[执行工具调用]
E -- 否 --> H
H --> I[写入哈希链审计记录]
I --> J[返回执行结果]
这类机制不能保证系统绝对安全,但能把风险降到可管理范围。尤其是在 Agent 会操作真实账号、真实文件和真实平台时,沙箱、权限、审计、人工确认都不是可选项。
与 OpenClaw、ZeroClaw 的差异
OpenFang、OpenClaw 和 ZeroClaw 的定位并不完全相同。可以用一句话区分:
- OpenClaw:功能更完整,但资源占用较重。
- ZeroClaw:用 Rust 重写后更轻,启动和内存表现更好,但能力覆盖更少。
- OpenFang:在资源占用和功能完整度之间取中间路线,重点放在自主调度和 Hands 工作流上。
项目资料中的功能对比如下:
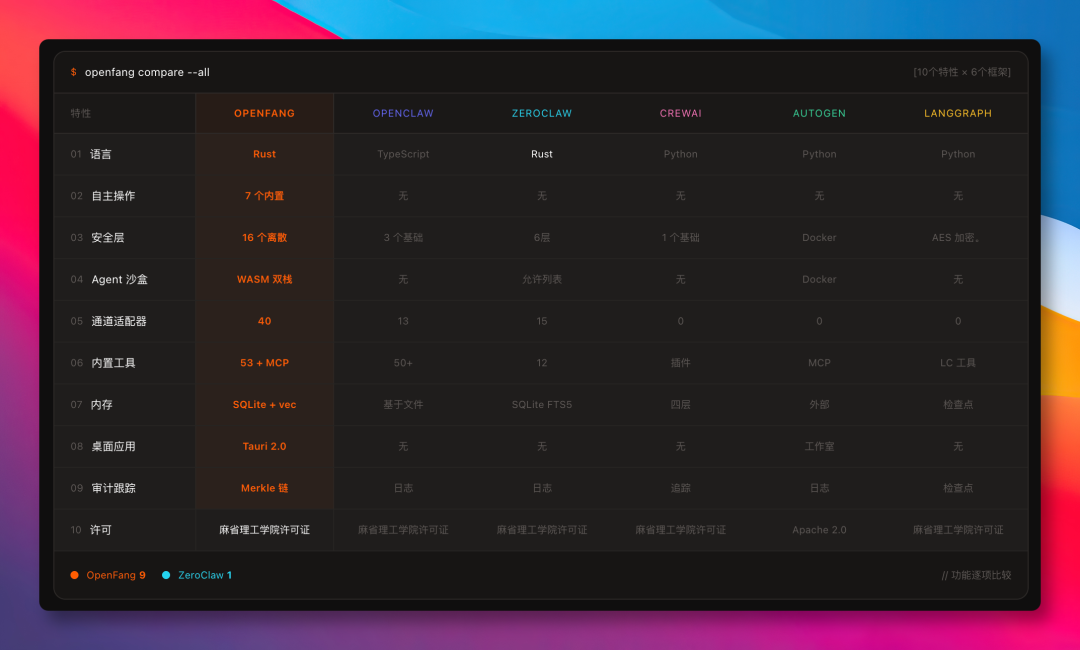
从功能维度看,自主调度是 OpenFang 最明显的差异。很多 Agent 框架能完成一次任务,但不一定具备长期运行、周期触发、流程闭环和安全审计能力。
性能对比可以参考下面这张图:
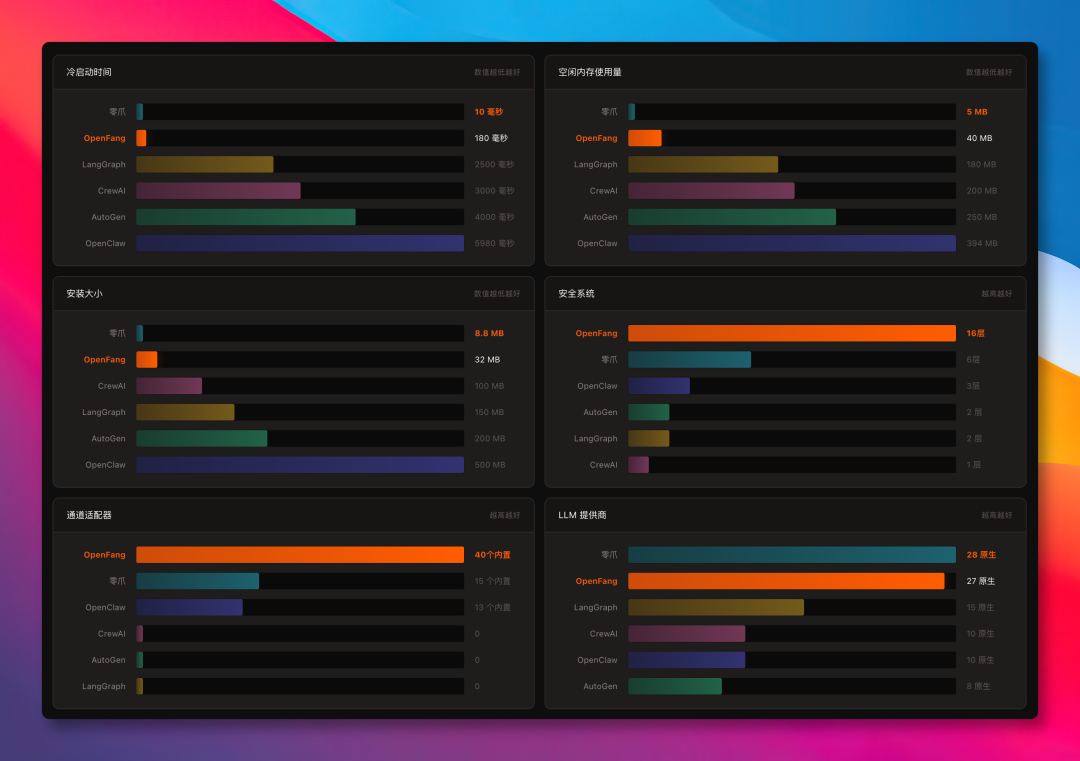
资源占用上,OpenFang 比 OpenClaw 更轻,但不会像 ZeroClaw 那样把目标集中在极致轻量。它牺牲了一部分极限性能,换来更完整的工作流能力、安全边界和内置 Hands。
更直观地看,三者适合的场景并不一样:
| 框架 | 更适合 | 不太适合 |
|---|---|---|
| ZeroClaw | 本地轻量运行、快速启动、资源紧张环境 | 复杂自动化流程、长周期任务调度 |
| OpenClaw | 功能覆盖优先、资源不是主要矛盾的环境 | 对内存和安装体积敏感的设备 |
| OpenFang | 需要 Agent 持续自动运行,并且要管理权限和审计的场景 | 只需要一次性问答或极简本地工具的场景 |
如果只是想让模型帮忙写一段代码、总结一个文件,用普通 Agent 就足够了。OpenFang 更适合那些“每天都要重复执行,而且执行过程需要管控”的任务。
安装与启动
OpenFang 提供了一键安装脚本,基本启动流程如下:
curl -fsSL https://openfang.sh/install | sh
openfang init
openfang start
启动后可以在浏览器中打开控制台:
http://localhost:4200
已经在使用 OpenClaw 的环境,可以通过迁移命令导入旧配置:
openfang migrate --from openclaw
迁移内容包括 Agent 配置、对话历史、Skills 和配置文件。由于项目仍在快速迭代,迁移前最好先备份数据目录和关键配置,尤其是模型密钥、平台授权信息和本地知识库文件。
一个较稳妥的试用步骤如下:
# 1. 备份旧配置
cp -r ~/.openclaw ~/.openclaw.backup
# 2. 安装 OpenFang
curl -fsSL https://openfang.sh/install | sh
# 3. 初始化
openfang init
# 4. 如需迁移
openfang migrate --from openclaw
# 5. 启动服务
openfang start
哪些场景适合使用 OpenFang
OpenFang 的价值主要出现在“任务可以流程化,并且需要持续运行”的场景。
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 每天整理行业资讯 | 适合 | 来源固定、流程稳定、输出格式明确 |
| 竞品动态和舆情监控 | 适合 | 需要长期运行和异常告警 |
| 销售线索挖掘 | 适合 | 可按规则调研、打分、去重并导出 |
| 视频素材批处理 | 适合 | 多阶段流程明确,适合自动化流水线 |
| 临时问答和头脑风暴 | 不一定适合 | 普通聊天式 Agent 成本更低 |
| 高风险金融交易 | 谨慎使用 | 即使有人工确认,也要额外做权限隔离 |
| 对资源极度敏感的本地环境 | 不一定适合 | ZeroClaw 这类轻量方案可能更合适 |
落地时可以先从低风险流程开始,例如资讯摘要、报告生成、文件整理。等任务稳定后,再逐步接入浏览器自动化、发布平台和业务系统接口。
使用时需要注意的坑
OpenFang 这类系统的难点不只在安装,更多在权限和流程设计。
不要给 Hand 过大的权限。
一个只负责生成日报的 Hand,不应该拥有删除文件、自动发布、支付交易等权限。权限应该按任务最小化配置。
高风险动作必须人工确认。
发布内容、购买服务、修改线上数据、删除文件,都应该进入确认流程。自动化系统最大的风险不是失败,而是在错误方向上持续执行。
输出格式要固定。
如果希望结果进入后续系统,例如 CRM(客户关系管理系统)、数据仓库或发布平台,就要提前规定字段、格式和路径,不要让模型自由发挥。
审计记录要保留。
当 Agent 自动跑了十几个步骤后,排查问题不能只靠最终结果。工具调用、输入输出、失败原因、人工确认记录都应该保存下来。
不要一开始就做大而全的 Hand。
更好的方式是把流程拆小。比如“收集信息”“去重归类”“生成摘要”“发布报告”可以先拆成几个独立步骤,确认稳定后再组合。
小结
OpenFang 的核心价值在于把 Agent 从“单次响应工具”推进到“可持续运行的工作流单元”。Hands 把运行计划、知识库、工具权限和指标封装在一起,让一个自动化任务具备明确职责、执行流程和安全边界。
它不追求像 ZeroClaw 那样极致轻量,也不是单纯复制 OpenClaw 的功能堆叠,而是把重点放在自主调度、流程闭环和生产级管控上。对于需要长期运行的 AI 自动化任务,例如监控、调研、线索挖掘和内容处理,这种结构比临时提示词更容易维护,也更容易规模化。
项目地址:
https://github.com/RightNow-AI/openfang