检索增强生成(Retrieval-Augmented Generation,RAG)的常见做法,是把文档切成片段,存入向量数据库;用户提问时,把问题也转成向量,再找出最相似的文档片段交给大语言模型(Large Language Model,LLM)回答。
这个流程适合回答具体问题,例如:
- “InfraNodus 怎么导入 CSV 文件?”
- “Dify 知识库支持哪些文件格式?”
- “如何在工作流里添加知识检索节点?”
因为这些问题里有明确关键词,向量检索很容易找到对应片段。
麻烦出现在宽泛问题上,例如:
- “这个工具能做什么?”
- “我应该怎么把它放进自己的工作流?”
- “有哪些高级用法?”
- “知识库里还有哪些容易被忽略的方向?”
这些问题不一定能和某个文档片段形成强匹配。普通 RAG 可能只捞到几个局部片段,回答就容易偏窄:它不是答错,而是只讲了知识库的一小块。
InfraNodus 可以补上这层缺失的“全局视角”。它会把文档、网页、PDF、Markdown 等内容转换成文本网络,抽取主要主题、概念关系、潜在主题和结构性空白。把这些信息加入 Dify 的 RAG 流程后,LLM 不只看到检索片段,还能知道整个知识库大概围绕哪些主题展开、哪些概念之间有关联、哪些方向值得补充。
普通 RAG 为什么容易漏掉全局信息
典型 RAG 管道可以简化成下面这个流程:
flowchart LR
A[用户问题] --> B[问题向量化]
B --> C[(向量数据库)]
C --> D[召回相似文档片段]
D --> E[LLM 生成回答]
E --> F[返回结果]
这个流程的关键是“相似度”。用户问题越具体,召回越准确;用户问题越抽象,召回结果越不可控。
以“它能做什么?”为例,这句话本身几乎没有领域信息。向量检索可能会命中知识库里任意一个看起来相关的片段,例如导入数据、图谱分析、搜索结果导入、工作流配置中的某一部分。LLM 拿到的上下文本来就不完整,生成出来的回答自然也只能围绕那几个片段展开。
问题不在 LLM 不会总结,而在检索阶段没有提供足够全面的上下文。
| 问题类型 | 普通 RAG 的表现 | 原因 |
|---|---|---|
| 精确问题 | 通常较好 | 问题关键词能直接匹配文档片段 |
| 宽泛问题 | 容易偏窄 | 问题缺少明确检索锚点 |
| 探索型问题 | 容易漏方向 | 向量检索不理解知识库整体结构 |
| 跨主题问题 | 依赖运气 | 相关片段可能分散在多个主题下 |
InfraNodus 的作用不是替代 Dify 知识库,而是在普通向量检索之外,额外提供一份“知识库地图”。
InfraNodus 提供的不是片段,而是主题图谱
InfraNodus 可以把文本转成概念网络。简单理解:
- 节点表示关键词、概念或主题;
- 边表示概念之间的关系;
- 聚类表示一组经常一起出现的主题;
- 图中的空隙表示不同主题之间尚未充分连接的区域。
InfraNodus 的分析面板会把语料转换成概念网络,并给出主要主题、关系和潜在方向:
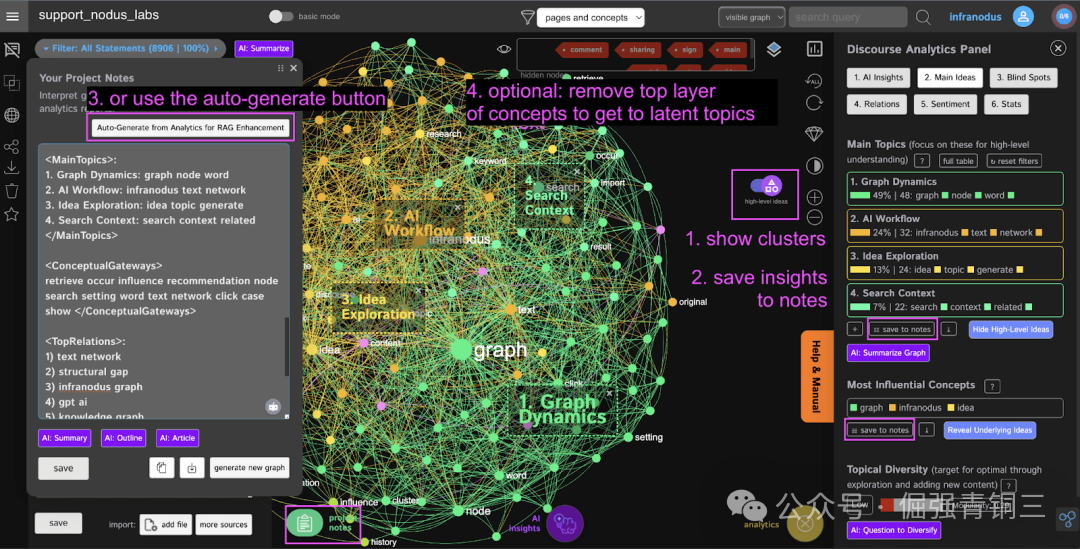
这类信息适合注入 RAG 流程,因为它解决的是“全局上下文不足”的问题。Dify 的知识检索节点负责找证据,InfraNodus 负责告诉模型“整个知识库的结构是什么”。
可以把两者的分工理解成这样:
| 组件 | 主要职责 | 适合解决的问题 |
|---|---|---|
| Dify 知识库 RAG | 从文档中召回相关片段 | 回答具体问题,提供事实依据 |
| InfraNodus | 抽取主题、概念关系和结构空白 | 处理宽泛问题、探索型问题、跨主题问题 |
| LLM | 结合检索片段和主题图谱生成答案 | 组织语言、归纳结构、给出回答 |
InfraNodus 常见可用信息包括:
| 信息类型 | 含义 | 在 RAG 中的用途 |
|---|---|---|
| MainTopics | 知识库中的主要主题 | 帮助模型覆盖核心范围 |
| Relations | 重要概念关系 | 帮助模型解释主题之间的连接 |
| LatentTopics | 潜在主题或非显性主题 | 帮助模型补充容易遗漏的角度 |
| ConceptualGateways | 连接多个主题的关键概念 | 帮助模型把分散内容串起来 |
| Structural Gaps | 结构性空白 | 帮助发现知识库里尚未充分连接的方向 |
两种接入方式:提示增强和查询改写
把 InfraNodus 接入 Dify RAG,核心有两种方式。
第一种是在回答阶段增强提示词。用户问题进入知识检索后,Dify 把检索片段传给 LLM;同时,把 InfraNodus 生成的主题图谱元信息也放进提示词里。LLM 回答时既参考具体片段,也参考全局主题。
第二种是在检索前改写用户问题。如果用户问得太宽泛,就先用 InfraNodus 的主题信息把问题改写得更具体,再送进 Dify 知识检索节点。这样可以让召回阶段更稳定。
整体流程如下:
flowchart TD
A[用户问题] --> B{问题是否足够具体}
B -->|具体| C[直接进入知识检索]
B -->|宽泛| D[结合 InfraNodus 主题图谱改写问题]
D --> C
C --> E[召回相关文档片段]
G[InfraNodus 分析知识库] --> H[主题 / 关系 / 潜在主题 / 概念入口点]
H --> D
H --> F[回答提示词增强]
E --> F
F --> I[LLM 生成答案]
I --> J[返回用户]
这两种方式可以单独使用,也可以组合使用:
- 只做提示增强:实现简单,适合先验证效果;
- 只做查询改写:能改善召回质量,适合宽泛问题较多的应用;
- 两者都做:检索前让问题更具体,生成时再给模型全局结构,适合知识库内容较复杂的应用。
数据准备:让 Dify 和 InfraNodus 使用同一批语料
要让两个系统配合,关键是让它们分析同一批知识源。可以使用以下数据来源:
| 数据来源 | 处理方式 |
|---|---|
| 上传到 Dify 知识库,同时导入 InfraNodus | |
| Markdown | 适合技术文档、产品说明、接口说明 |
| 网站页面 | 可用 Firecrawl 抓取后导入 |
| RSS / 搜索结果 / YouTube 转录稿 | 可先导入 InfraNodus 做主题分析 |
| 内部文档 | 需要注意权限和隐私边界 |
一个常见的数据流是:
flowchart LR
A[PDF / Markdown / 网站页面] --> B[Dify 知识库]
A --> C[InfraNodus]
C --> D[生成主题图谱元信息]
B --> E[Dify 知识检索]
D --> F[Dify 工作流变量或提示词]
E --> G[LLM]
F --> G
G --> H[答案]
如果知识库来自网站,可以先用 Firecrawl 抓取页面,再把结果分别送入 Dify 和 InfraNodus。这样 Dify 负责后续问答检索,InfraNodus 负责提取全局主题结构。
在 InfraNodus 中生成 RAG 可用的图谱上下文
完成语料导入后,需要从 InfraNodus 中提取适合放进提示词的结构化信息。理想格式不需要很复杂,只要清楚表达主题、关系和关键概念即可。
可以整理成类似下面的结构:
<GraphContext>
<MainTopics>
<Topic>文本网络分析:概念节点、主题聚类、关系可视化</Topic>
<Topic>AI 工作流:知识库、检索、LLM 提示增强</Topic>
<Topic>研究探索:结构性空白、潜在主题、问题生成</Topic>
<Topic>数据导入:网页、搜索结果、文档、转录稿</Topic>
</MainTopics>
<Relations>
<Relation>网络分析 与 主题聚类 相关</Relation>
<Relation>结构性空白 可用于发现新的研究问题</Relation>
<Relation>概念入口点 可连接多个主题分组</Relation>
</Relations>
<LatentTopics>
<Topic>从概念网络中发现未被充分讨论的方向</Topic>
<Topic>用图谱结构辅助 RAG 覆盖更多主题</Topic>
</LatentTopics>
<ConceptualGateways>
<Concept>检索</Concept>
<Concept>文本</Concept>
<Concept>网络</Concept>
<Concept>节点</Concept>
<Concept>主题</Concept>
<Concept>关系</Concept>
</ConceptualGateways>
</GraphContext>
XML 标签不是必须的,但很适合在提示词中隔离不同信息。LLM 能更稳定地区分“主要主题”“概念关系”和“检索上下文”。
在 Dify 中配置知识库和工作流
Dify 侧至少需要三个部分:
- 知识库:保存原始文档,供 RAG 检索;
- 工作流或 Chatflow:控制查询改写、知识检索、LLM 回答;
- 变量:保存 InfraNodus 生成的图谱上下文,避免每次重复分析。
可以按这个顺序搭建:
| 步骤 | Dify 节点或功能 | 作用 |
|---|---|---|
| 1 | 知识库 | 上传 PDF、Markdown,或接入网站抓取结果 |
| 2 | 变量 | 保存 InfraNodus 图谱上下文,例如 infranodus_graph |
| 3 | IF/ELSE | 判断 infranodus_graph 是否为空 |
| 4 | HTTP 请求或工具节点 | 为空时调用 InfraNodus 获取图谱信息 |
| 5 | 变量赋值器 | 把图谱结果写入变量 |
| 6 | LLM 节点 | 判断是否需要改写用户问题 |
| 7 | 知识检索 | 用改写后或原始问题召回文档片段 |
| 8 | LLM 节点 | 结合检索片段和图谱上下文生成回答 |
Dify Chatflow 中可以采用“先检查缓存,再检索,再回答”的结构:
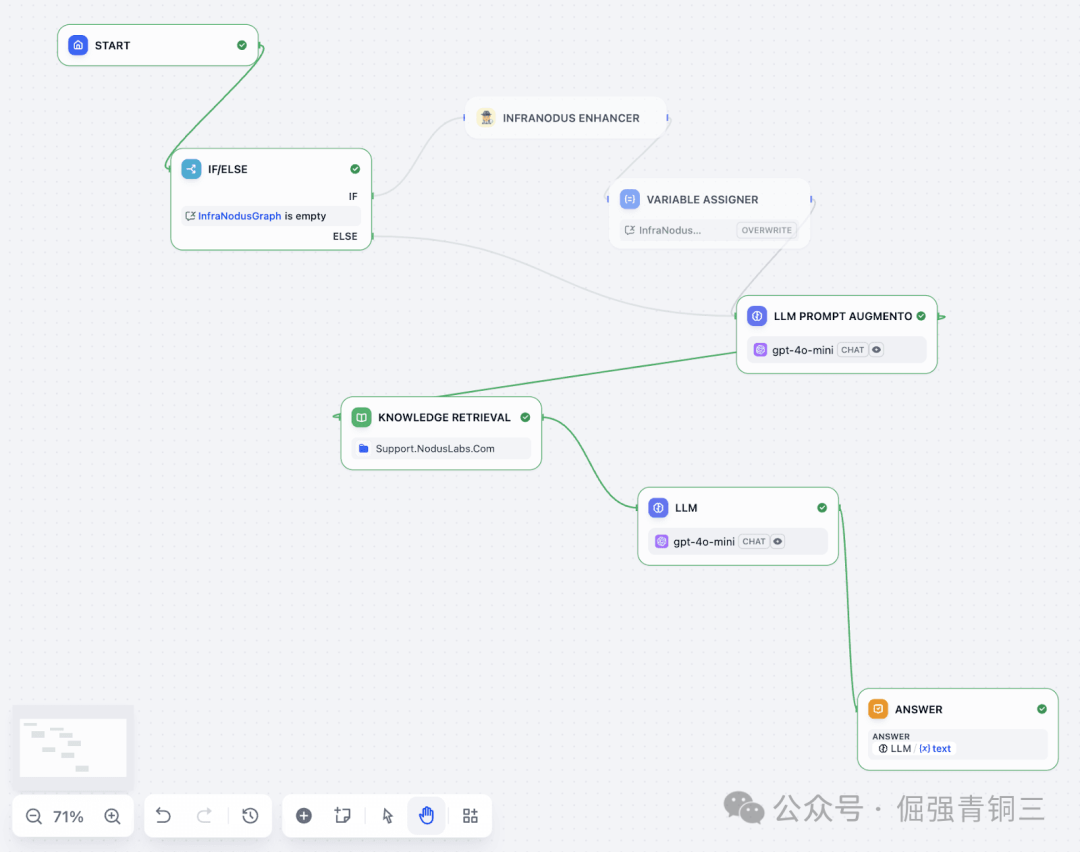
这个流程的重点是缓存 InfraNodus 结果。知识库较大时,实时生成主题图谱可能需要十几秒;如果每次用户提问都重新分析,延迟会明显增加。把图谱上下文保存到变量后,后续问题可以直接复用,只有知识库更新时再刷新。
对应的逻辑可以画成这样:
flowchart TD
A[用户开始提问] --> B{infranodus_graph 是否为空}
B -->|为空| C[调用 InfraNodus 获取图谱上下文]
C --> D[变量赋值器保存 infranodus_graph]
B -->|不为空| E[读取已有图谱上下文]
D --> F[判断是否需要改写问题]
E --> F
F --> G[知识检索]
G --> H[LLM: 检索结果 + 图谱上下文 + 用户问题]
H --> I[输出答案]
回答阶段的系统提示词模板
回答阶段的提示词要处理好一个边界:InfraNodus 的图谱上下文用于补充全局结构,Dify 检索片段才是回答事实问题的主要依据。
可以使用下面这个模板:
你是一个知识库问答助手,需要根据用户问题回答。
回答规则:
1. 优先依据 <context> 中的检索片段回答,不要编造知识库中没有的信息。
2. <GraphContext> 是知识库的全局主题图谱,用于理解主题范围、概念关系和潜在方向。
3. 当用户问题比较宽泛时,需要参考 <GraphContext> 覆盖主要主题,而不是只围绕单个片段回答。
4. 当 <context> 中没有足够依据时,明确说明知识库中缺少直接证据,并给出可继续查询的方向。
5. 回答要结构化,可以使用列表、步骤或表格。
<GraphContext>
{{infranodus_graph}}
</GraphContext>
<context>
{{#context#}}
</context>
用户问题:
{{#query#}}
这个模板有三个关键点:
- 检索片段放在
<context>中,负责事实依据; - InfraNodus 元信息放在
<GraphContext>中,负责全局结构; - 明确要求“缺少依据时说明不足”,避免模型把主题图谱当成事实来源随意展开。
检索前的查询改写模板
如果用户问题很短、很宽泛,最好先改写再检索。例如用户问:
它能做什么?
改写节点可以把它变成:
InfraNodus 在文本网络分析、主题聚类、结构性空白发现、AI 工作流和知识库检索增强方面分别能做什么?
这样一来,知识检索节点会更容易召回多个主题下的片段,而不是只命中某一个局部内容。
查询改写提示词可以这样写:
你负责改写用户问题,让它更适合进入知识库检索。
判断规则:
1. 如果用户问题已经包含明确对象、操作或主题,不要改写,直接输出原问题。
2. 如果用户问题过于宽泛,例如“它能做什么”“怎么用”“有什么功能”,需要结合 <GraphContext> 补充少量关键主题。
3. 改写后的问题不能比原问题膨胀太多,只加入最重要的 3 到 5 个主题。
4. 只输出改写后的问题,不要解释改写原因。
<GraphContext>
{{infranodus_graph}}
</GraphContext>
用户问题:
{{#query#}}
查询改写不要贪多。把所有主题都塞进问题里,反而会让检索目标变得混乱。比较合适的做法是挑出与用户意图最相关的几个主题。
一个完整的 Dify + InfraNodus RAG 工作流
把前面的步骤合在一起,可以得到一个比较完整的工作流:
sequenceDiagram
participant U as 用户
participant D as Dify Chatflow
participant I as InfraNodus
participant K as Dify 知识库
participant L as LLM
U->>D: 提交问题
D->>D: 检查 infranodus_graph 变量
alt 变量为空
D->>I: 请求知识库图谱上下文
I-->>D: 返回主题、关系、潜在主题、概念入口点
D->>D: 保存到变量
else 变量已有值
D->>D: 直接复用图谱上下文
end
D->>L: 判断是否需要改写问题
L-->>D: 返回原问题或改写后问题
D->>K: 执行知识检索
K-->>D: 返回相关片段
D->>L: 输入检索片段 + 图谱上下文 + 用户问题
L-->>D: 生成答案
D-->>U: 返回结果
这个工作流中,InfraNodus 只需要在图谱上下文为空或知识库更新时运行。日常问答时,Dify 直接复用已经生成好的元信息,可以减少延迟。
标准 RAG 与图谱增强 RAG 的差异
| 对比项 | 标准 Dify RAG | 接入 InfraNodus 后 |
|---|---|---|
| 检索依据 | 用户问题与文档片段的向量相似度 | 向量相似度 + 知识库主题图谱 |
| 宽泛问题 | 容易只回答局部内容 | 更容易覆盖主要主题 |
| 跨主题问题 | 依赖召回结果是否足够全面 | 可利用概念关系串联多个主题 |
| 回答结构 | 取决于召回片段 | 可按主题、关系、场景组织 |
| 额外成本 | 配置简单 | 需要维护图谱上下文和缓存 |
| 适合场景 | FAQ、明确操作问答 | 产品说明、研究资料、复杂知识库、探索型问答 |
如果知识库只包含少量 FAQ,普通 RAG 往往够用;如果知识库包含大量文档、教程、产品说明、研究材料,用户又经常提出开放式问题,引入主题图谱会更有价值。
速度优化:不要每次都实时分析
InfraNodus 分析完整知识库需要时间。知识库越大,图谱生成越慢。比较合理的策略是:
| 策略 | 做法 |
|---|---|
| 缓存图谱上下文 | 第一次生成后存入 Dify 变量 |
| 控制元信息长度 | 只保留 Top N 主题和关键关系 |
| 知识库更新后刷新 | 文档变化时重新生成图谱 |
| 分知识库保存 | 多个知识库不要共用一份图谱上下文 |
| 回答时复用 | 每次问答只读取缓存,不重复分析 |
可以把变量设计成类似下面的结构:
{
"main_topics": [
"文本网络分析",
"AI 工作流",
"结构性空白发现",
"数据导入",
"知识库检索增强"
],
"relations": [
"主题聚类 -> 知识结构理解",
"结构性空白 -> 新问题发现",
"概念入口点 -> 跨主题连接"
],
"latent_topics": [
"用图谱辅助 RAG 覆盖更多主题",
"从文本网络中发现隐藏研究方向"
],
"conceptual_gateways": [
"检索",
"文本",
"网络",
"节点",
"主题",
"关系"
]
}
实际放进提示词时,可以转成 XML、Markdown 或 JSON。关键不是格式,而是边界清楚、内容精简、变量可复用。
容易踩的坑
1. 把图谱上下文当成事实来源
InfraNodus 提供的是主题结构,不是事实证据。回答具体问题时,仍然要以 Dify 知识检索返回的片段为准。
错误做法:
只根据 MainTopics 回答所有问题。
更稳妥的做法:
用 MainTopics 判断回答应覆盖哪些方向,用 context 判断每个方向是否有证据。
2. 元信息太长,挤占有效上下文
如果把几十个主题、上百条关系全部塞进提示词,LLM 的注意力会被稀释,还会占用上下文窗口。一般只保留最重要的主题和关系即可。
建议控制在:
| 元信息 | 建议数量 |
|---|---|
| MainTopics | 5 到 10 个 |
| Relations | 5 到 15 条 |
| LatentTopics | 3 到 8 个 |
| ConceptualGateways | 10 到 30 个关键词 |
3. 查询改写过度
宽泛问题需要改写,但不能把问题改成一篇大纲。改写后的问题越长,检索越可能偏离用户真实意图。
合适的改写:
InfraNodus 在文本网络分析、主题聚类和结构性空白发现方面能做什么?
不合适的改写:
请全面介绍 InfraNodus 在文本网络分析、AI 工作流、Google 搜索导入、RSS、YouTube、结构性空白、概念入口点、市场研究、知识库检索、主题聚类、潜在主题发现等所有方面的功能和应用。
4. 知识库更新后没有刷新图谱
Dify 知识库更新后,如果 InfraNodus 图谱上下文仍然是旧版本,回答会出现结构偏差。可以在文档更新流程里增加一步:重新生成图谱上下文并覆盖 Dify 变量。
5. 多个知识库混用同一份图谱
不同知识库的主题结构不同。产品文档、技术教程、市场资料如果共用同一份图谱上下文,LLM 会把不相关的主题混在一起。更好的方式是为每个知识库维护独立的图谱变量。
什么时候适合接入 InfraNodus
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 小型 FAQ 问答 | 不一定需要 | 问题和答案都很明确,普通 RAG 足够 |
| 产品帮助中心 | 适合 | 用户常问“能做什么”“怎么组合使用” |
| 技术文档知识库 | 适合 | 概念多、模块多,跨主题问题常见 |
| 研究资料分析 | 很适合 | 需要发现主题、关系和结构性空白 |
| 内部知识库助手 | 适合 | 员工问题往往不完全匹配文档标题 |
| 强事实检索系统 | 谨慎使用 | 图谱只能辅助组织,不能替代证据检索 |
最实用的判断标准是:如果用户经常问开放式问题,而普通 RAG 的回答总是只覆盖一个局部,就可以考虑加一层主题图谱上下文。
核心思路
Dify 的 RAG 擅长从知识库中找相关片段,但它默认不知道整个知识库的结构。InfraNodus 可以把文档变成主题图谱,提取主要主题、概念关系、潜在主题和结构性空白。
把这份图谱上下文接入 Dify 后,可以形成一个更稳的问答链路:
flowchart LR
A[Dify RAG 找证据] --> C[LLM 回答]
B[InfraNodus 提供全局结构] --> C
C --> D[更完整地覆盖主题]
具体落地时,优先做三件事:
- 让 Dify 和 InfraNodus 使用同一批知识源;
- 把 InfraNodus 的主题图谱保存成变量,避免每次实时生成;
- 在查询改写和回答提示词中使用图谱上下文,但始终让检索片段承担事实依据。