很多 AI(人工智能)文生图模型已经能生成非常复杂的画面:电影感光影、精细材质、复杂背景、人物表情都可以做得很像样。但在一些看似简单的提示词上,它们仍然会稳定犯错。
典型例子是:
a person writing with their left hand
一个人正在用左手写字
理想结果很明确:笔应该在人物自己的左手里,右手不能拿笔。可实际生成时,模型经常画成右手写字。即使把提示词改得更具体,比如“右手拿苹果,左手写字”,画面仍可能变成“左手拿苹果,右手写字”。
这类错误不只出现在“左手写字”上。只要提示词要求模型把某个对象放进明确的左右关系里,错误率就会明显上升。
| 提示词约束 | 期望结果 | 常见错误 |
|---|---|---|
| 左手写字 | 笔在人物自己的左手 | 笔跑到右手 |
| 右手拿苹果,左手写字 | 右手苹果,左手笔 | 两只手的任务反了 |
| 左手拿橘子,右手拿苹果 | 左橘右苹 | 物品左右互换 |
| 盘子在罐头左边 | 盘子位于左侧 | 两个物体都画对,但位置反了 |
这不是简单的“模型不知道 left/right 是什么意思”。更准确的说法是:模型在训练时看过太多偏向某些固定组合的样本,导致它把“常见搭配”当成了“默认真理”。当提示词要求它生成少见组合时,文本里的约束会输给训练数据里积累出的强先验。
文生图模型不是在执行逻辑规则
文生图模型生成图片时,并不是先读懂一句话,再像程序一样执行一条条规则。更常见的过程是:文本编码器把提示词转成向量,生成模型再根据训练阶段学到的图文对应关系,一步步合成图像。
flowchart LR
A[提示词:左手写字] --> B[文本编码器]
B --> C[条件向量]
D[训练数据中的图文关系] --> E[模型学到的视觉先验]
C --> F[图像生成过程]
E --> F
F --> G[输出图片]
如果训练数据里,“写字”这个概念大多数时候都伴随着“右手拿笔”,模型就会形成一个很强的关联:
writing ≈ person + desk + notebook + pen in right hand
当提示词里出现“left hand writing”时,模型确实接收到了 left hand 这个约束,但这个约束要和“写字通常由右手完成”的统计规律竞争。对于一个训练数据严重倾斜的模型来说,少见约束很容易被常见模式压过去。
这里还有几个额外难点:
| 难点 | 为什么会影响生成 |
|---|---|
| 左右依赖视角 | “人物自己的左手”和“画面左侧的手”不是一回事 |
| 人体结构近似对称 | 左手和右手外观相似,局部细节容易混淆 |
| 标注经常不写左右 | 图片标题常写“person writing”,很少明确写“right hand writing” |
| 现实世界本来不均衡 | 右撇子比例高,写字照片天然偏向右手 |
这些因素叠加后,模型就不只是偶尔搞错,而是会在某些提示上表现出稳定偏差。
现象空间:模型到底有没有见过“可互换的关系”
论文《Skews in the Phenomenon Space Hinder Generalization in Text-to-Image Generation》提出了一个很有用的解释框架:现象空间偏差会阻碍文生图模型泛化。
“现象空间”可以理解为一个任务里所有可能出现的组合空间。它由两类东西组成:
| 概念 | 含义 | 例子 |
|---|---|---|
| filler | 被放进关系里的实体 | 圆形、三角形、猫、老鼠、盘子、罐头 |
| role | 实体在关系中扮演的位置或角色 | 上方、下方、左边、右边、追逐者、被追逐者 |
拿“猫追老鼠”来说,猫和老鼠是 filler;“追的一方”和“被追的一方”是 role。拿“圆在三角形上方”来说,圆和三角形是 filler;“上方”和“下方”是 role。
真正的关系理解要求模型知道:filler 和 role 是可以重新组合的。
flowchart TB
subgraph Fillers[实体 filler]
F1[圆形]
F2[三角形]
end
subgraph Roles[关系 role]
R1[上方]
R2[下方]
end
F1 --> R1
F2 --> R2
F1 -.也应该能.- R2
F2 -.也应该能.- R1
如果模型只见过“圆在上、三角在下”,它可能并没有学会“上方/下方”这个关系,而只是记住了一种固定搭配:圆就应该在上面,三角就应该在下面。
这就是泛化失败的根源:模型记住了搭配,却没有学会可组合的关系。
Completeness 和 Balance:数据多不等于数据好
论文里用了两个指标来描述训练数据是否足够支持关系泛化。
Completeness:完整性
Completeness 表示每个实体是否至少出现在每个角色里。
以“圆形”和“三角形”的上下关系为例,如果训练集中同时存在:
圆形在上,三角形在下
三角形在上,圆形在下
那么模型至少见过两个实体在两个位置上的互换情况,完整性比较高。
如果训练集中从来没有“三角形在上”的样本,那么模型就缺了一块关键经验。测试时要求它生成“三角形在圆形上方”,它很可能不知道该怎么处理。
Balance:平衡性
Balance 表示不同组合出现的比例是否接近。
完整性高并不代表一定够好。假设训练集中有 100 张图:
| 组合 | 数量 |
|---|---|
| 圆形在上,三角形在下 | 99 |
| 三角形在上,圆形在下 | 1 |
这种数据虽然“完整”,但非常不平衡。模型会强烈相信“圆形应该在上面”,那 1 张反例很难改变整体倾向。
更理想的训练数据应该接近:
| 组合 | 数量 |
|---|---|
| 圆形在上,三角形在下 | 50 |
| 三角形在上,圆形在下 | 50 |
完整性解决“有没有见过”的问题,平衡性解决“有没有被某种搭配压倒”的问题。
| 数据状态 | 模型容易学到什么 |
|---|---|
| 完整且平衡 | 关系可以互换,实体不绑定固定角色 |
| 完整但不平衡 | 见过少数反例,但仍偏向高频组合 |
| 不完整 | 某些实体从未出现在某些角色中,泛化困难 |
合成实验:小图标也能暴露关系泛化问题
为了排除真实图片里的复杂干扰,论文设计了一个合成数据实验。实验使用 Unicode(统一码字符集)小图标,把图像控制在 32×32 的小方块里。每张图只表达一种关系:两个东西上下叠放。
例如:
蛋糕在橡皮上方
橡皮在蛋糕上方
猫在狗上方
狗在猫上方
每张图片配一段文字描述,模型需要学习文字和图像里的上下关系。
实验关键不在于图片多复杂,而在于训练集怎么分布:
| 训练集类型 | 数据特点 |
|---|---|
| 高完整性、高平衡性 | 每个图标都当过上方,也当过下方,比例接近 |
| 高完整性、低平衡性 | 每个图标都出现过不同位置,但某些位置特别少 |
| 低完整性 | 有些图标从未出现在某些位置 |
实验结果很直接:完整性和平衡性越好,模型在测试组合上的准确率越高;两者越差,准确率越低。
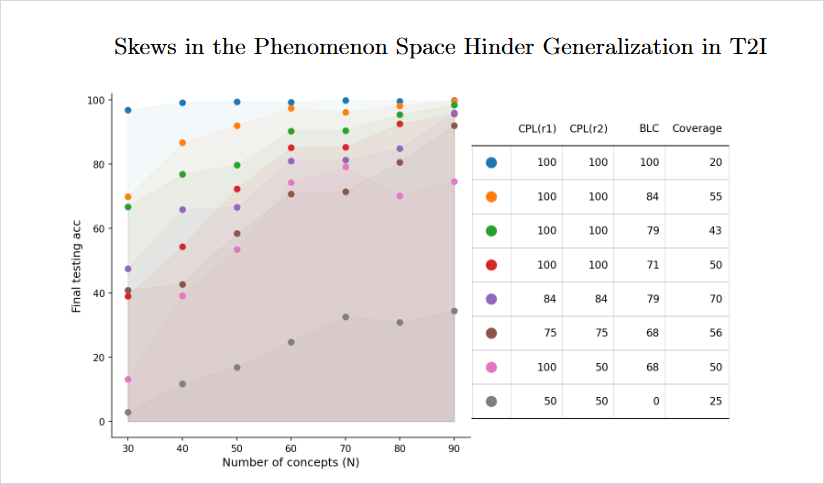
图里的 CPL 代表 Completeness,BLC 代表 Balance。蓝色散点对应完整性和平衡性都很高的训练集,测试准确率接近满分;灰色散点对应两项指标都较差的训练集,准确率明显下降,甚至低于 40%。这说明模型能不能举一反三,关键不只是训练样本数量,而是关系组合有没有被充分、均衡地呈现。
真实图片实验:物体画对了,关系却反了
合成图标实验说明了机制,但真实图片更复杂。论文进一步使用 What'sUp 基准数据集做实验。这个数据集包含自然场景图片,专门考察物体之间的位置关系,例如:
plate left of can
盘子在罐头左边
研究者从数据集中抽取不同子集:有些子集完整性和平衡性高,有些子集明显偏斜。模型训练后,再去生成没有在训练集中出现过的新组合。
结果和合成实验一致:只要视觉关系数据的完整性、平衡性下降,模型在未知组合上的准确率也跟着下降。最常见的错误不是物体不存在,而是关系反了。
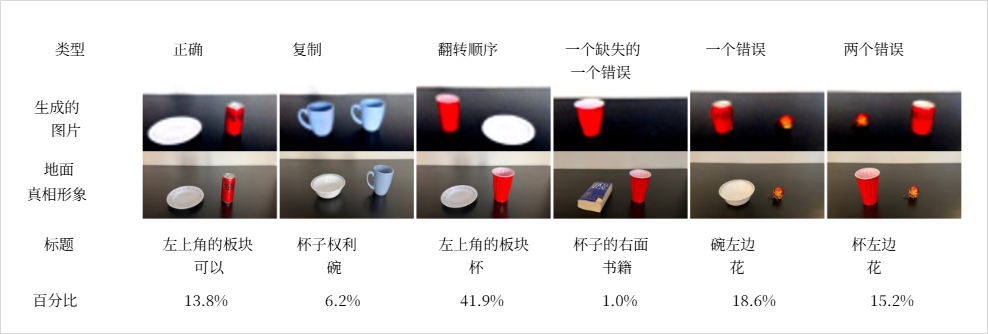
这类错误很有代表性:模型知道要画“盘子”和“罐头”,也能把它们画得合理,但没有稳定遵守“谁在谁左边”的关系。换句话说,实体识别和关系绑定是两件事;前者做对,不代表后者也做对。
为什么“左手写字”特别容易失败
把这个框架套回“左手写字”,问题就清楚了。
在这个任务里:
| 角色 | 对应内容 |
|---|---|
| filler | 人、左手、右手、笔、纸、本子 |
| role | 哪只手拿笔、哪只手空着、哪只手执行写字动作 |
| 关系约束 | 笔必须绑定到人物自己的左手 |
真实训练数据里,“写字”高度偏向右手。大量图片的标题或标签只会写:
student writing notes
person writing in notebook
hand holding pen
它们很少明确标注:
a person writing with their right hand
a left-handed student writing notes
the pen is in the person's left hand
这会带来两个问题。
一方面,左手写字样本数量少,完整性不足。模型可能看过很多“右手写字”,却很少看过“左手写字”。
另一方面,即使存在少量左手写字图片,比例也可能远低于右手写字,平衡性很差。模型会把“写字动作”和“右手拿笔”绑定在一起。
flowchart TB
A[训练图片:多数是右手写字] --> B[图片标签:通常只写 writing]
B --> C[模型学习到强关联]
C --> D[writing ≈ 右手拿笔]
E[提示词:left hand writing] --> F[生成时约束竞争]
D --> F
F --> G[输出:仍然画成右手写字]
所以,错误并不是模型完全不知道左和右,而是它在“写字”这个具体场景里学到了一个过强的默认模式。提示词里的“left hand”想改变这个模式,但权重不一定够。
这也解释了为什么加约束仍然可能失败。比如“右手拿苹果,左手写字”看起来已经很明确,但模型内部有两个强关联在竞争:
写字 -> 右手拿笔
拿东西 -> 任意手都可以
当“写字 -> 右手拿笔”的先验更强时,模型就会牺牲左右约束,把画面改成自己更熟悉的配置。
对训练数据的启发:不要只堆数量,还要查分布
大规模数据当然重要,但如果数据集中大量样本都集中在同一类组合上,模型可能只是把高频搭配记得更牢,而不是学会关系规则。
想让文生图模型更可靠地执行关系指令,数据集至少要做几类检查。
| 目标 | 做法 | 解决的问题 |
|---|---|---|
| 检查完整性 | 统计每个实体是否出现在不同角色里 | 避免某些组合完全缺失 |
| 检查平衡性 | 统计各组合比例,必要时重采样或补数据 | 避免高频组合压制低频组合 |
| 强化关系标注 | 在 caption 里明确写出 left/right、above/below、holding 等关系 | 避免模型只能从图像里隐式猜关系 |
| 增加反事实样本 | 构造“左手写字”“三角在上”“罐头在盘子右边”等少见组合 | 训练模型处理非默认配置 |
| 单独评测关系能力 | 不只看图片美观度,也测物体位置、手部绑定、动作主体 | 找出实体正确但关系错误的情况 |
需要注意,现实世界本来就不是均匀分布的。右撇子确实比左撇子多,日常图片也确实更常出现右手写字。训练数据是否应该完全均衡,取决于目标。
如果目标是生成“最常见的真实世界”,保留真实分布有意义;如果目标是准确执行用户指令,就必须让模型见过足够多的少见组合,否则它会在指令跟常识冲突时偏向常识。
提示词能缓解,但解决不了根本问题
在现有模型上,可以通过更明确的提示词降低失败概率,但这属于推理阶段的补救,不会改变模型训练时学到的偏差。
可以尝试把“左手”说得更具体:
A front-facing student writing with the student's own left hand.
The pen is held only in the student's left hand.
The student's right hand is open and resting on the table, not holding a pen.
Clear view of both hands. No pen in the right hand.
中文也可以写成:
正面视角,一个学生正在用自己身体的左手写字。
笔只在左手里,右手张开并放在桌面上,右手没有拿笔。
双手都清晰可见。
几个技巧比较实用:
| 技巧 | 作用 |
|---|---|
| 明确“人物自己的左手” | 减少“画面左侧”和“身体左侧”的歧义 |
| 给右手安排互斥任务 | 例如右手摊开放在桌上,避免它拿笔 |
| 写出否定约束 | “right hand is not holding a pen” |
| 要求双手清晰可见 | 避免模型用遮挡逃避左右关系 |
| 使用草图、姿态控制或局部重绘 | 用结构约束压过语言提示的不稳定性 |
不过,提示词再详细也可能失败。只要训练数据里的组合分布严重倾斜,生成过程仍然会被高频模式拉回去。
关键结论
“左手写字”失败背后有一个更通用的问题:文生图模型经常能画对实体,却不一定能画对实体之间的关系。
现象空间偏差给出了清晰解释:
- 只增加数据量不够,关系组合必须完整;
- 只出现少量反例也不够,组合比例还要相对平衡;
- 当某个动作和某个角色长期绑定,模型会把统计偏差学成默认规律;
- 少见组合如果缺失或占比太低,模型在测试时就容易把关系反过来。
文生图模型要真正听懂“谁在左边、谁在右边、哪只手拿笔”,训练数据不能只展示世界最常见的样子,还要覆盖那些不那么常见、但完全合理的组合。只有当模型见过足够多“角色可以互换”的例子,它才更可能学会关系,而不是背下一堆固定搭配。