生成式 AI(人工智能)刚进入大众工作流时,一个很有吸引力的判断迅速流行起来:它会降低知识工作的门槛,让经验少、技能弱的人也能完成过去只有熟练员工才能完成的任务。
这个判断并非凭空出现。2023 年,麻省理工学院两位经济学研究者在《Science》发表实证研究,发现 ChatGPT 能显著提升低绩效员工在写作类任务中的表现,而且提升幅度大于高绩效员工。换句话说,AI 看起来像一种“能力补齐器”:它让弱者进步更多,从而缩小人与人之间的生产率差距。
但后续数据给出了更复杂的答案。AI 确实能提高短期产出,却未必会自动带来平权。它可能同时产生三类影响:
| 影响层面 | 正向效果 | 潜在代价 |
|---|---|---|
| 劳动力市场 | 高技能员工能把 AI 融入工作流,扩大产出 | 初级岗位的训练价值和招聘需求下降 |
| 知识生产 | 论文、报告、方案等产出速度提高 | 主题、语言风格和论证结构趋同 |
| 个体认知 | 使用 AI 时创意数量和完成质量上升 | AI 离场后,能力提升不一定保留,思考习惯可能被锚定 |
真正需要理解的不是“AI 好不好”,而是:AI 提供的能力到底是被人内化了,还是只是临时外挂?如果大量个体都从类似模型那里获得类似答案,群体层面的思想多样性会发生什么变化?
从“工作平权”到“资历偏向”:AI 没有均匀改变劳动力市场
2025 年,两位哈佛大学经济学博士分析了 2015 到 2025 年间覆盖 6200 多万员工、1.5 亿多次招聘就业记录的数据,发现生成式 AI 对岗位结构的影响并不均匀。
在 2015 到 2022 年之间,初级岗位和高级岗位的就业增长趋势大体同步。2023 年之后,两条曲线开始分叉:高级岗位继续增长,初级岗位转向下行。对深度使用 AI 的企业来说,六个季度内初级岗位数量相对下降 7.7%,高级岗位则基本没有受到负面影响,甚至略有增长。
关键点在于,这种变化主要来自招聘减少,而不是大规模裁员。也就是说,AI 更可能影响“新人的入口”,而不是直接替换已经在岗的资深员工。
可以把这个机制简化成一条链路:
flowchart LR
A[生成式 AI 进入企业工作流] --> B[常规写作、检索、整理、初稿生成自动化]
B --> C[初级岗位承担的基础任务减少]
C --> D[企业降低初级岗位招聘需求]
A --> E[资深员工用 AI 放大经验和判断]
E --> F[高级岗位产出提升或保持稳定]
为什么会出现这种“资历偏向”?
因为很多初级知识岗位的价值,来自可拆分、可模板化、可校对的任务,例如整理资料、写初稿、改格式、生成备选方案。AI 很擅长这些工作。高级岗位的价值则更多来自问题定义、任务拆解、质量判断、跨领域取舍和责任承担。这些能力不容易被一次生成替代,反而会因为 AI 的辅助而放大。
所以,AI 不只是“让所有人更快”。它会重新分配不同能力的价值:会提问、会判断、会整合的人获得更大杠杆;只依赖模板执行的人更容易被压缩空间。
研究一:41 万篇论文中的效率提升与表达趋同
北京大学李圭泉课题组在 Technology in Society 发表的研究,把问题推进到知识生产本身:当 ChatGPT 进入学术工作流后,全球学术论文是否变得更高产?如果更高产,内容是否也变得更相似?
研究团队从 Web of Science 核心数据库抽取了 17000 多名学者,覆盖物理科学、生命科学与生物医药、应用科学、社会科学、艺术与人文等 21 个学科门类,汇总这些学者在 ChatGPT-3.5 发布前后的 419344 篇论文。
研究关心两个指标:
| 指标 | 具体测量方式 | 含义 |
|---|---|---|
| 创造力 | 论文发表数量、期刊 JCR 分区 | 学术产出的规模与发表质量 |
| 同质性 | 摘要语义相似度、语言风格相似度 | 不同论文在主题内容和表达方式上的相似程度 |
其中,JCR(Journal Citation Reports,期刊引证报告)分区是一种期刊影响力评级体系。Q1 代表该领域排名前 25% 的期刊,Q4 代表排名后 25% 的期刊。
同质性的测量更偏技术化:
- 内容相似度:使用 SBERT(Sentence-BERT,句向量语义模型)把论文摘要转成向量,再计算向量之间的余弦相似度。
- 语言风格相似度:使用字符级匹配算法,统计摘要之间重复短语、句式和表达结构的相似程度。
余弦相似度的直觉很简单:两个向量方向越接近,说明它们表达的语义越接近。
cosine_similarity(A, B) = (A · B) / (||A|| × ||B||)
趋势图展示了 ChatGPT-3.5 发布前后,学术产出创造力与同质性的变化。它的重点不是某一个点的波动,而是断点之后斜率的变化。
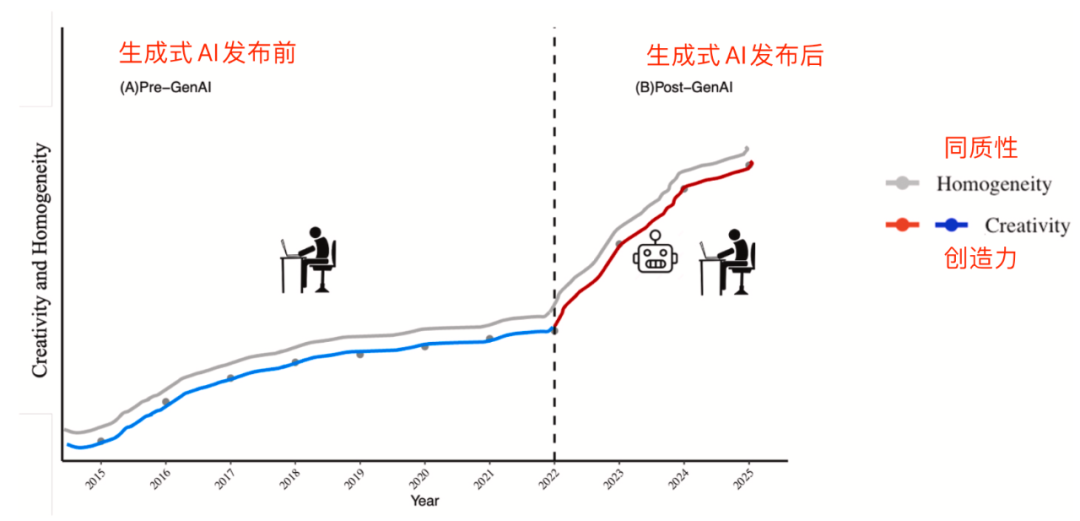
图中可以看到,2022 年之前,创造力指标和同质性指标都在相对平稳地增长;ChatGPT-3.5 发布之后,两类指标的增长速度同时抬升。这说明 AI 像一个加速器,一方面提高产出,另一方面也让表达和主题更快地靠拢。
断点回归:如何把“巧合”与“因果”分开
仅仅看到 2023 年之后趋势变化,还不能直接说这是 AI 导致的。学术界本来就可能受到其他因素影响,例如研究经费、出版政策、疫情后的科研恢复、不同学科周期变化等。
为了解决这个问题,研究使用了 RDD(Regression Discontinuity Design,断点回归设计)。这个方法适合处理一种特殊场景:某个时间点或规则阈值把样本分成两侧,而阈值附近的个体差异很小,近似可以看成随机分配。
在这个研究中,ChatGPT-3.5 于 2022 年 12 月发布,可以被视为一个时间断点:
flowchart LR
A[ChatGPT-3.5 发布前] --> B[无法使用 ChatGPT-3.5 辅助论文生产]
C[ChatGPT-3.5 发布时间点] --> D[时间断点]
D --> E[ChatGPT-3.5 发布后]
E --> F[有机会使用 ChatGPT-3.5 辅助论文生产]
论文发表在断点前还是断点后,受到审稿周期、编辑流程、期刊排期等因素影响。对单个学者来说,这些因素并不完全可控。尤其在断点附近,断点前后的论文可以近似看作两组可比样本。
断点回归关心的是:如果没有 ChatGPT,趋势应该沿着原来的路径继续;如果断点后结果突然偏离原趋势,就可以把这部分变化估计为 AI 的影响。
一个简化模型可以写成:
Y = α + τ × AfterChatGPT + f(TimeDistance) + ε
含义如下:
| 符号 | 含义 |
|---|---|
| Y | 被解释变量,例如发表数量、期刊质量、内容相似度 |
| AfterChatGPT | 是否处于 ChatGPT-3.5 发布之后 |
| τ | 断点后的跃迁效应,也就是研究最关心的 AI 影响 |
| f(TimeDistance) | 距离发布时间点的时间趋势 |
| ε | 无法解释的随机扰动 |
断点回归成立有一个重要前提:样本不能在断点附近被人为操纵。比如,如果大量学者故意把论文压到 ChatGPT 发布后再投稿,或者抢在发布前集中发表,断点附近就不再近似随机。研究团队对这种“堆积”或“抢发”行为做了统计检验,以降低这类偏差。
断点回归结果图展示了 AI 发布后各项指标的变化方向和显著性。
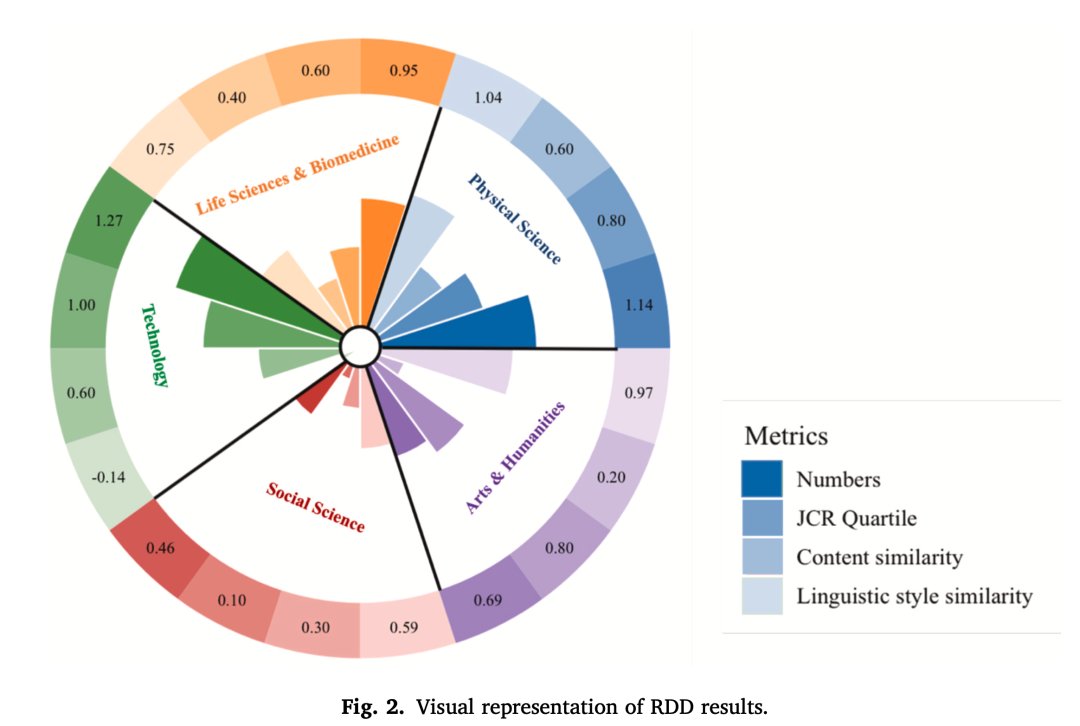
结果显示,ChatGPT-3.5 发布后,学者人均年发表量增加约 0.9 篇,发表期刊质量平均提升约 6%,技术和物理科学领域的提升更明显。但同质性也同步上升:语言风格相似度平均每年增加约 79%,内容主题也显著趋同,物理科学、艺术与人文学科中的趋同现象更突出。
这个结果很关键:AI 带来的不是单纯的生产率提升,而是一种“高产出 + 高相似”的组合。
为什么 AI 会让内容趋同:锚定效应与默认答案
生成式 AI 的输出通常具有三个特征:
- 速度快,能在几秒内给出完整结构。
- 形式稳定,经常使用清晰、顺滑、可接受的表达。
- 风险较低,倾向于给出多数场景下不会太错的答案。
这些特征非常适合提高效率,却也容易制造锚定效应。锚定效应指的是:人一旦看到一个初始答案,后续判断会被这个答案牵引,很难完全跳出去重新思考。
在 AI 工作流里,锚定效应通常是这样发生的:
flowchart TD
A[人提出问题] --> B[AI 快速生成一个完整框架]
B --> C[人觉得框架基本可用]
C --> D[后续修改围绕 AI 框架展开]
D --> E[最终作品保留 AI 的主题、结构和措辞倾向]
E --> F[大量用户得到相似输出]
F --> G[群体层面的内容同质化]
个体层面看,这是一种省力机制:不必从空白页开始,可以直接修改现成答案。群体层面看,许多人都从类似模型、类似提示词、类似训练语料中获得初稿,最后就会产生相似的主题选择、段落结构、语气风格和论证套路。
同质化不等于所有内容完全一样,而是差异变小。它可能表现为:
| 层面 | 趋同表现 |
|---|---|
| 主题 | 反复选择相似角度,绕开少见问题 |
| 结构 | 总是“背景—问题—方案—展望”的模板 |
| 语言 | 高频使用类似转折、总结和评价词 |
| 判断 | 倾向于安全、中庸、低争议的结论 |
| 方案 | 更容易给出行业通用做法,少有非典型路径 |
这就是 AI 的双刃剑:它降低了表达难度,也降低了偏离默认答案的概率。
研究二:AI 离场后,创造力提升还能留下吗
宏观数据能说明知识生产整体出现变化,但还不能回答一个更细的问题:个体使用 AI 后,创造力是真的提高了,还是只是在 AI 陪伴时看起来提高?
为此,北大研究团队设计了一项纵向行为实验。参与者是 61 名大学生,被随机分成两组:
| 分组 | 实验条件 |
|---|---|
| AI 实验组 | 第 2 到第 6 天可使用 ChatGPT-4 |
| 纯脑力对照组 | 全程不使用 AI 辅助 |
实验分为多个阶段:
- 第 1 天:所有参与者都不使用 AI,完成创造力基线测试。
- 第 2 到第 6 天:AI 实验组使用 ChatGPT-4 完成每日创造力任务,对照组不使用 AI。
- 第 7 天、第 30 天、第 60 天:所有参与者都不能使用 AI,完成追踪测试。
实验流程图展示了这种“先辅助、再撤离、再追踪”的设计。
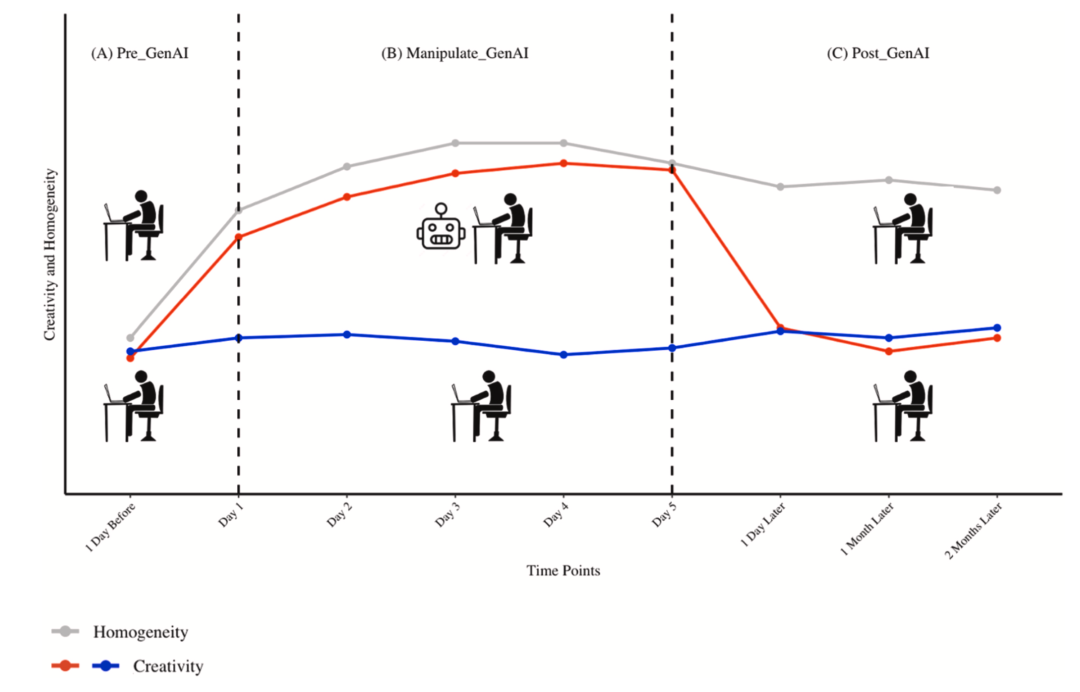
这个设计的好处在于,它不仅能观察 AI 使用期间的即时效果,还能观察 AI 被撤走后效果是否持续。如果 AI 真正提升了人的能力,那么在无 AI 测试中,实验组仍应保持优势;如果 AI 只是提供了外部脚手架,那么一旦脚手架撤走,优势就会消失。
创造力评估采用多种任务组合:
| 任务 | 英文缩写 | 测量能力 |
|---|---|---|
| 替代用途任务 | AUT(Alternative Uses Task) | 发散思维,例如为一支钢笔想出尽可能多的新用途 |
| 创意问题解决 | 无固定缩写 | 面向真实场景生成创新方案,例如为智能单车设计新功能 |
| 远距联想测验 | RAT(Remote Associates Test) | 聚合思维,从三个不相关词中找共同关联词 |
| 蜡烛问题 | Candle Problem | 洞察力和问题重构能力 |
评分使用 CAT(Consensual Assessment Technique,共识评估法)。多位专家在不知道参与者分组和实验目的的双盲条件下,对创意产出的新颖性、实用性、灵活性等维度打分。评分者信度 ICCs 高于 0.90