出国旅行时,点餐经常不是“语言不通”这么简单。
菜单上可能没有图片,菜名可能是地方叫法,配料里还夹着一堆专业词。即使用翻译软件把菜名翻成中文,也不一定知道它到底是汤、主食、炸物还是生食,更不知道辣不辣、有没有坚果、奶制品、海鲜、酒精等过敏风险。
一个真正可用的 AI 点餐助手,不能只做“拍照翻译”。它应该完成一条完整链路:
flowchart LR
A[拍摄菜单] --> B[识别菜品与价格]
B --> C[翻译并解释菜品]
C --> D[生成类似外卖的点餐界面]
D --> E[结合口味和过敏信息推荐套餐]
E --> F[生成下单文字和语音]
F --> G[与服务员实时双向翻译]
核心目标很明确:让用户在陌生语言环境里,也能像平时点外卖一样完成选菜、确认、下单和沟通。
点餐助手解决的不是翻译问题,而是决策问题
传统翻译工具通常只解决“这句话是什么意思”。但点餐场景里,用户真正关心的是这些问题:
| 用户问题 | 单纯翻译能否解决 | 点餐助手需要补充的信息 |
|---|---|---|
| 这是什么菜? | 部分可以 | 菜品类型、主料、做法 |
| 好不好吃? | 不能 | 口味描述、常见评价、适合人群 |
| 辣不辣? | 部分可以 | 辣度、调味方式 |
| 有没有过敏食材? | 不稳定 | 过敏原识别和风险提示 |
| 两个人怎么点合适? | 不能 | 分量、搭配、预算 |
| 怎么跟服务员说? | 部分可以 | 当地语言下单文本与语音 |
| 服务员临时说菜没了怎么办? | 不能 | 实时双向翻译 |
所以,产品设计不能停在“菜单 OCR(光学字符识别)+ 机器翻译”。更合理的做法是把菜单转成结构化数据,然后围绕结构化数据做解释、推荐和交互。
一条完整的 AI 点餐链路
一个可用的流程通常包含五个模块:菜单识别、菜品理解、个性化推荐、下单表达、对话翻译。
flowchart TB
U[用户] --> M[移动端 App]
M --> I[图片预处理]
I --> O[OCR / 多模态识别]
O --> S[菜单结构化解析]
S --> T[翻译与菜品解释]
T --> K[菜品知识补全 / 搜索校验]
K --> R[推荐引擎]
P[用户偏好<br/>忌口 / 过敏 / 预算] --> R
R --> UI[点餐界面]
UI --> G[下单文本生成]
G --> V[语音合成 TTS]
M --> ASR[语音识别 ASR]
ASR --> TR[实时双向翻译]
TR --> V
这套架构里,多模态大模型主要负责“看懂菜单”和“理解菜品”;传统工程模块负责稳定性、成本控制、缓存、界面交互和语音播放。
菜单识别:先把图片变成结构化数据
菜单图片的难点不只是文字识别。很多菜单有多列排版、手写字体、菜品和价格混在一起,有些菜名还夹着当地语言、英文、编号和套餐说明。
识别模块最好不要只输出一段翻译后的长文本,而是直接输出结构化 JSON,方便后续展示和推荐。
{
"restaurant_language": "ja",
"currency": "JPY",
"items": [
{
"name_original": "焼き鳥盛り合わせ",
"name_zh": "烤鸡肉串拼盘",
"category": "烧烤 / 居酒屋菜",
"price": 980,
"description_zh": "多种鸡肉部位烤串组合,通常使用盐或酱汁调味。",
"main_ingredients": ["鸡肉"],
"possible_allergens": ["大豆", "小麦"],
"flavor": {
"spicy": "低",
"sweet": "中",
"salty": "中"
},
"confidence": 0.86
}
]
}
这里有几个关键点:
-
保留原始菜名
原始菜名必须保留,因为服务员看得懂本地语言,用户也可以用它核对菜单。 -
翻译不等于解释
“烤鸡肉串拼盘”比直译更有用,但还不够。用户需要知道它是烧烤、主料是鸡肉、口味偏咸甜、可能含酱油。 -
每个字段都要有置信度
图片模糊、菜单字体特殊、菜品是地方小吃时,大模型可能猜错。置信度可以决定界面是否提示“建议向服务员确认”。 -
过敏信息不能只靠猜
如果无法确定,就应该输出“可能包含”或“需要确认”,而不是装作确定。
为什么界面应该像外卖 App
点餐助手的界面不一定要炫。越接近用户熟悉的外卖点餐界面,学习成本越低。
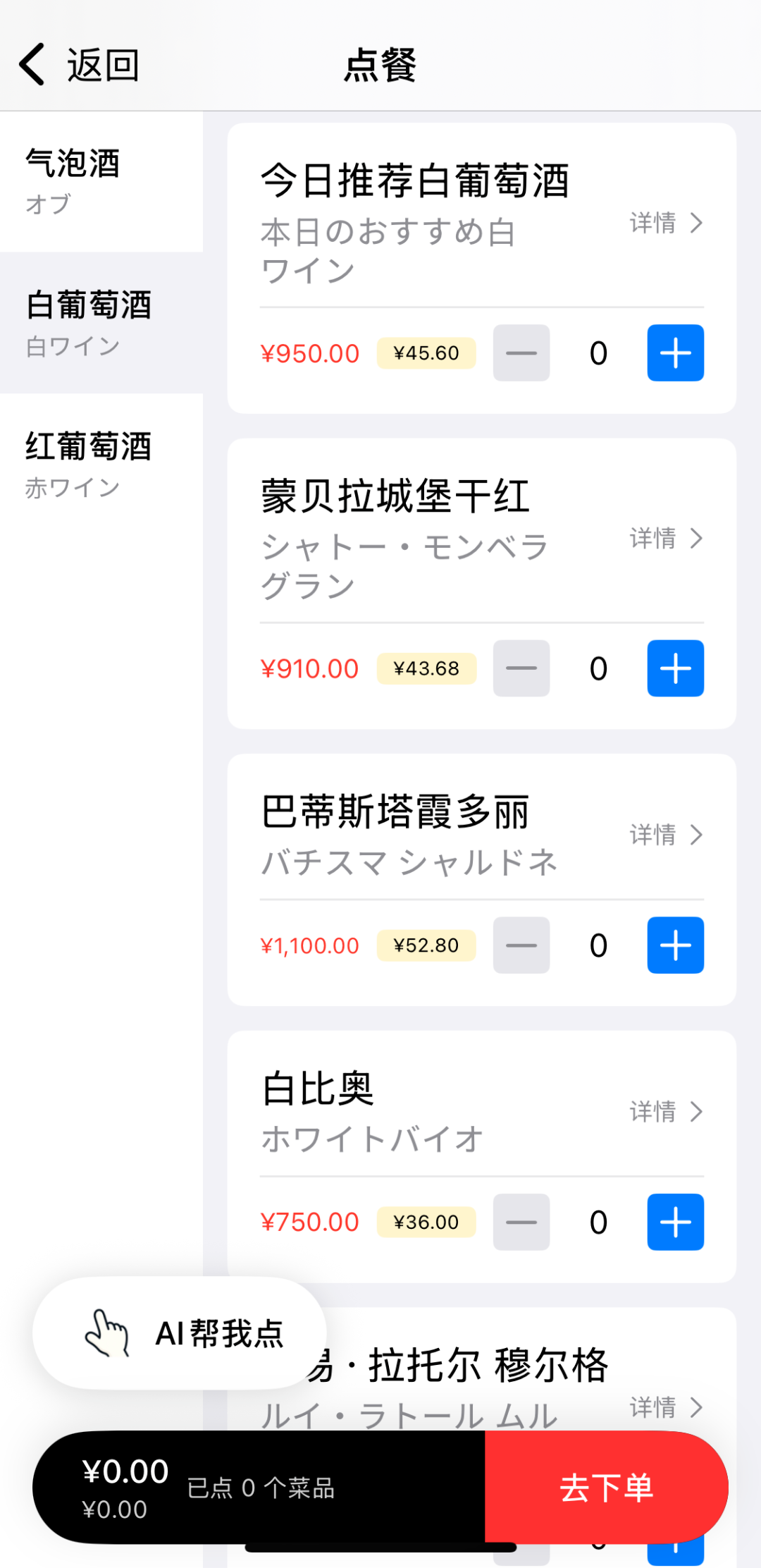
菜单识别后,可以把菜品重新组织成“分类 + 菜品卡片”的形式。用户不需要在一张陌生语言菜单里来回找,只要像平时点外卖一样浏览、加购、查看详情。
菜单识别后的核心界面应该突出三类信息:菜名、图片或图标、菜品解释。这样用户能快速判断这道菜是不是自己想点的。

上面的界面重点不是把菜单逐行翻译出来,而是把菜单重排成用户熟悉的点餐结构。菜品卡片可以承载中文名、原始名、价格、推荐标签、过敏提示等信息,比一段机器翻译文本更适合做决策。
当用户不知道怎么搭配时,AI 推荐可以进一步把“选择菜品”变成“选择方案”。
推荐界面需要明确展示推荐原因,例如“适合两人”“避开海鲜”“口味偏清淡”“包含主食和热菜”。如果只给出一个套餐列表,而不解释为什么推荐,用户很难信任结果。
个性化推荐:把用户约束写进决策过程
推荐套餐不是简单挑几个热门菜。一个点餐助手至少要处理这些约束:
| 约束类型 | 示例 | 推荐时的处理方式 |
|---|---|---|
| 人数 | 1 人、2 人、家庭出行 | 控制菜品数量和分量 |
| 预算 | 人均 100 元以内 | 过滤高价菜,优先组合套餐 |
| 口味 | 不吃辣、喜欢甜口 | 调整菜品排序和推荐理由 |
| 忌口 | 不吃生食、不吃内脏 | 直接排除相关菜品 |
| 过敏 | 花生、海鲜、乳制品 | 高风险菜品必须拦截 |
| 饮食习惯 | 素食、清真 | 标记不确定项并提醒确认 |
推荐模块可以分成两层:
flowchart LR
A[结构化菜单] --> B[硬性过滤]
P[用户限制] --> B
B --> C[候选菜品集合]
C --> D[搭配评分]
D --> E[套餐生成]
E --> F[推荐理由]
硬性过滤适合处理过敏、宗教饮食、明确忌口等不能妥协的条件;搭配评分适合处理口味、预算、冷热搭配、荤素搭配等偏好。
一个推荐结果可以长这样:
{
"set_name": "两人清淡套餐",
"items": [
"番茄牛肉汤",
"蒜香烤鸡",
"蔬菜沙拉",
"米饭"
],
"reason": [
"避开了用户标记的海鲜过敏风险",
"包含汤、主菜、蔬菜和主食,适合两人分享",
"整体辣度较低"
],
"risk_notes": [
"蒜香烤鸡可能含黄油,乳制品过敏者建议向服务员确认"
]
}
推荐理由必须具体,不能只写“为你精选”。用户在国外餐厅做决策时,最需要的是确定性。
下单生成:文字和语音都要能直接使用
选好菜之后,点餐助手要把购物车转成当地语言的下单表达。这个模块看似简单,其实很重要,因为服务员看到或听到的内容必须自然、准确、没有歧义。
下单文本可以包含:
- 菜品原始名称
- 数量
- 特殊要求
- 过敏提醒
- 是否打包
- 是否需要去掉某种配料
示例:
您好,我们想点以下菜品:
1. 焼き鳥盛り合わせ × 1
2. 味噌汁 × 2
3. ご飯 × 2
另外,其中一位客人对花生过敏。请问这些菜里是否含有花生或花生油?
如果含有,请帮我们去掉,或者推荐安全的替代菜品。谢谢。
语音合成 TTS(Text-to-Speech,文本转语音)也很有必要。很多餐厅环境嘈杂,或者服务员不方便看手机屏幕,直接播放当地语言语音会更顺畅。
sequenceDiagram
participant User as 用户
participant App as 点餐助手
participant LLM as 生成模块
participant TTS as 语音合成
participant Waiter as 服务员
User->>App: 确认购物车和特殊要求
App->>LLM: 生成当地语言下单文本
LLM-->>App: 返回可展示文本
App->>TTS: 转成语音
TTS-->>App: 返回音频
App->>Waiter: 展示文本或播放语音
下单文本生成时要避免过度发挥。菜名、数量、忌口信息应该来自结构化数据和用户输入,而不是让模型自由编写。
实时对话翻译:处理菜单之外的不确定情况
餐厅里经常会出现菜单之外的对话:
- 某道菜今天没有
- 厨房不能去掉某种配料
- 套餐需要选择饮品
- 服务员询问熟度、辣度、冰量
- 用户想确认是否含有过敏原
这时需要实时双向翻译。一个常见流程是:
flowchart LR
A[用户按住说话] --> B[ASR 语音识别]
B --> C[翻译成目标语言]
C --> D[屏幕展示]
C --> E[TTS 播放]
F[服务员说话] --> G[ASR 语音识别]
G --> H[翻译成中文]
H --> I[屏幕展示]
H --> J[TTS 播放]
ASR(Automatic Speech Recognition,自动语音识别)负责把语音转成文本,翻译模块负责转语言,TTS 负责播放。为了减少误会,界面最好同时显示原文和译文,方便双方确认。
工程难点:幻觉、成本和延迟
多模态大模型能显著提升菜单理解能力,但也会带来三个工程问题:幻觉、调用成本、响应延迟。
1. 幻觉:不能把猜测当事实
菜单识别场景里的幻觉很危险。模型可能根据菜名猜测配料,也可能把图片里没有的信息补出来。尤其是过敏信息,错误判断会直接影响用户安全。
降低幻觉可以从几个方面入手:
| 风险点 | 处理方式 |
|---|---|
| 菜名识别不确定 | 展示原图裁剪区域,让用户核对 |
| 配料无法确认 | 标记为“可能包含”,提醒询问服务员 |
| 地方菜缺少知识 | 接入搜索或菜品知识库做校验 |
| 模型输出自由发挥 | 使用 JSON Schema 限制字段 |
| 过敏相关判断 | 高风险时强制生成确认话术 |
结构化输出可以约束模型少说废话,也方便做规则校验。
{
"type": "object",
"required": ["name_original", "name_zh", "price", "confidence"],
"properties": {
"name_original": { "type": "string" },
"name_zh": { "type": "string" },
"price": { "type": ["number", "null"] },
"possible_allergens": {
"type": "array",
"items": { "type": "string" }
},
"confidence": {
"type": "number",
"minimum": 0,
"maximum": 1
}
}
}
2. 成本:不要所有任务都交给最大模型
菜单点餐是高频小场景,如果每一步都调用最贵的多模态大模型,成本会很难控制。更合理的做法是模型分层。
| 任务 | 可选方案 | 成本策略 |
|---|---|---|
| 图片压缩与裁剪 | 本地处理 | 不调用模型 |
| 普通 OCR | OCR 模型或小模型 | 低成本批量识别 |
| 难菜单理解 | 多模态大模型 | 只在必要时调用 |
| 菜品解释 | 小语言模型 + 缓存 | 常见菜复用结果 |
| 推荐套餐 | 规则 + 语言模型 | 先规则过滤,再生成解释 |
| 下单文本 | 小语言模型 | 模板优先,模型润色 |
| 语音播放 | TTS 服务 | 按需生成并缓存 |
还可以按餐厅、地区和菜品做缓存。同一家餐厅的菜单被多人拍摄后,后续用户不需要重复完整识别。
3. 延迟:用户站在餐厅里,不能等太久
点餐助手最好把任务拆成可并行的流水线。用户拍照后,先快速返回可阅读的菜单,再逐步补全推荐和解释。
flowchart TB
A[上传菜单图片] --> B[快速识别菜名和价格]
A --> C[后台裁剪菜品区域]
B --> D[先展示基础菜单]
C --> E[补全菜品解释]
E --> F[补全过敏提示]
F --> G[生成推荐套餐]
这种设计能让用户先开始浏览,不必等待所有 AI 任务完成。推荐、过敏提示、详情解释可以异步加载。
什么场景适合做成 AI 点餐助手
这种产品适合“小场景、强需求、高频交互”的问题。它不追求替代完整旅游工具,而是把一个明确痛点做深。
| 场景 | 适合程度 | 原因 |
|---|---|---|
| 出国旅行点餐 | 高 | 菜单识别、翻译、推荐、对话都集中在同一流程 |
| 外国游客在中国点餐 | 高 | 菜品解释和双向翻译需求明显 |
| 餐厅服务外国客人 | 高 | 不需要商家先做复杂数字化系统 |
| 景点路牌识别 | 中 | 更偏信息翻译,决策链路较短 |
| 商品包装识别 | 中 | 适合扩展过敏原、成分、产地解释 |
| 严肃医疗饮食建议 | 低 | 风险高,需要专业审核和责任边界 |
点餐场景的价值在于:它不是单点翻译,而是从“看懂”走到“能下单”。AI 只有嵌进完整任务流,用户才会明显感受到差异。
一个最小可用版本应该怎么做
如果要从零实现类似应用,最小可用版本可以只做四件事:
- 拍摄菜单并识别菜品
- 把菜品转成结构化列表
- 根据用户忌口生成推荐
- 生成当地语言下单文本
对应的 MVP(Minimum Viable Product,最小可用产品)架构可以很轻:
flowchart LR
A[移动端拍照] --> B[图片压缩]
B --> C[多模态模型]
C --> D[结构化菜单 JSON]
D --> E[菜品列表界面]
E --> F[用户选择菜品]
F --> G[下单文本生成]
早期不要急着做复杂的商家后台、社交分享、积分系统。先验证几个关键问题:
- 拍照识别是否足够稳定
- 用户能否看懂菜品解释
- 推荐是否真的减少选择成本
- 下单文本服务员是否能理解
- 过敏和忌口提示是否足够谨慎
只要这条主链路顺畅,后续再加入实时语音翻译、菜品图片补全、商家菜单维护、离线缓存等能力。
关键设计原则
AI 点餐助手看起来是一个小工具,但里面涉及多模态识别、结构化抽取、推荐系统、机器翻译、语音交互和移动端体验。要做得可用,需要遵守几条原则:
-
结构化优先
先把菜单变成可计算的数据,再做翻译、推荐和下单。 -
熟悉感优先
用类似外卖的界面降低学习成本,比做一个炫酷但难懂的界面更实用。 -
安全边界优先
对过敏、忌口、生食等风险信息保持保守,不确定时必须提示确认。 -
模型分层调用
把简单任务交给便宜模型或本地逻辑,把复杂理解交给多模态大模型。 -
结果可核对
原始菜名、翻译名、价格、推荐理由和风险提示都要展示出来,让用户能做最终判断。
点餐只是一个入口。类似的“拍一下就能理解并行动”的模式,还可以扩展到路牌、景点说明、商品包装、药品说明、交通告示等跨语言场景。真正重要的不是把文字换一种语言,而是把陌生环境里的信息变成用户能理解、能决策、能执行的流程。