大语言模型(LLM,Large Language Model)能写代码、解题、翻译、规划任务,但它为什么会给出某个答案,内部到底用了哪些特征和计算路径,仍然很难直接看清。
传统可解释性方法常用一种“探测器”思路:先定义一组人类理解的标签,比如情感、词性、实体类型、语法角色,再训练一个小模型去判断某个神经元或某层表示是否包含这些标签信息。这种方法有用,但有一个限制:标签是人提前定好的。如果模型学到的是“法律免责声明里的责任限制表达”“JSON 中可能代表配置项的键名”“间接宾语识别中的名字复制模式”这类更细、更混合的概念,固定标签集就不够用了。
概念描述(Concept Description)换了一个角度:不再要求研究者先列出标签,而是让另一个语言模型观察目标组件的行为,再用自然语言写出解释。它要回答的问题很直接:
这个神经元、注意力头、稀疏特征或电路,究竟在检测什么、执行什么、影响什么?
这类方法的目标不是把模型完全“白盒化”,而是把内部机制切成可讨论、可验证的局部假设。
概念描述可以覆盖多个粒度,从单个神经元到整段电路都能被自然语言解释。
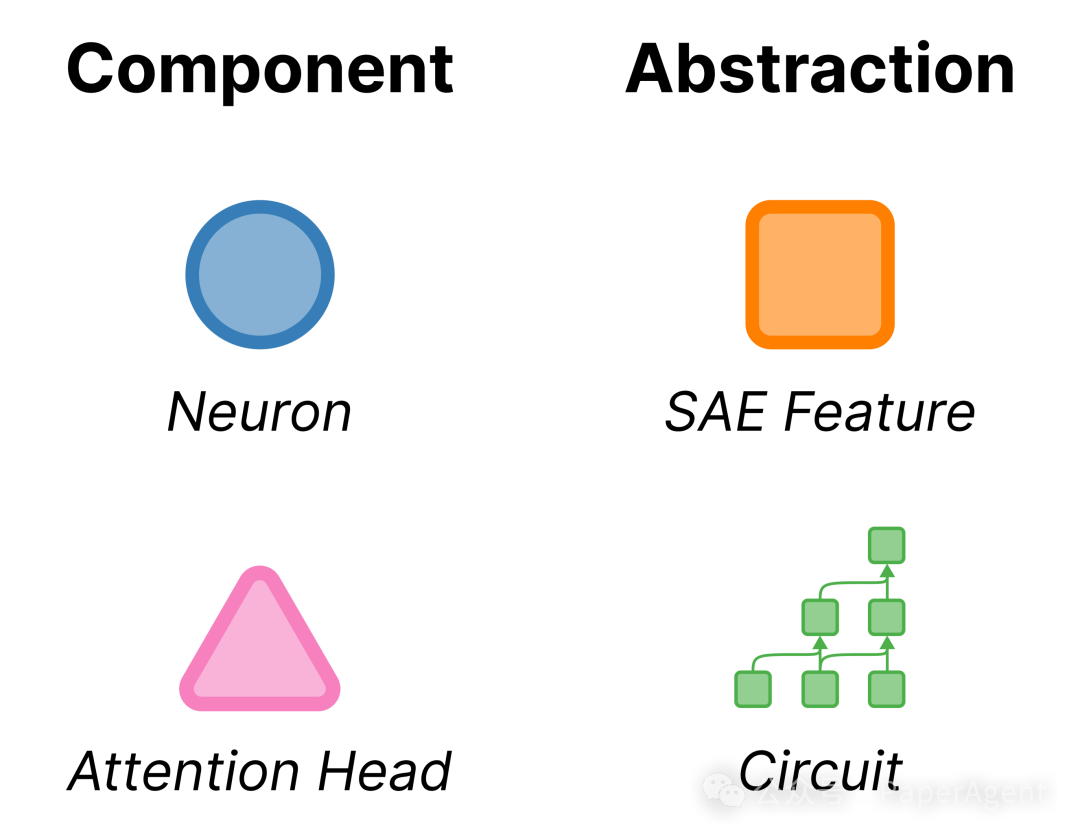
图中展示了概念描述的几个主要对象:神经元、注意力头、SAE 特征和电路。越靠近底层组件,越容易收集激活样本;越靠近电路层级,越接近模型完成任务时真正用到的因果路径,但分析成本也更高。
概念描述到底在描述什么
LLM 内部有很多可观察对象,不同对象对应的问题不同。
| 层级 | 对象 | 典型问题 | 解释难点 |
|---|---|---|---|
| 组件级 | 神经元 | 某个神经元为什么在法律条款、年代词、代码符号上都激活? | 单个神经元常常不是单一概念 |
| 组件级 | 注意力头 | 某个注意力头是否在做复制、对齐、括号匹配或实体回指? | 注意力权重不一定等于因果贡献 |
| 抽象级 | SAE 特征 | 某个稀疏特征对应的是哪个更干净的语义方向? | 特征仍可能有多个触发条件 |
| 抽象级 | 电路 | 一组头、MLP 和残差流如何共同完成某个任务? | 需要定位子图,还要验证子图真的必要 |
这里最关键的障碍叫多语义性(polysemanticity)。一个神经元经常同时服务多个看似无关的概念。原因很简单:模型参数有限,训练目标又复杂,同一个维度可能被复用来编码多个特征。
举个例子,一个神经元可能对这些文本都很敏感:
1. The party shall not be liable for indirect damages.
2. 1984 was a landmark year for the company.
3. section 7.2 of the agreement
如果只给它写一句“检测法律文本”,解释会漏掉年代和章节编号;如果写成“检测正式文档中的编号和责任条款”,又可能过宽。多语义性会让单句解释天然失真。
稀疏自编码器(SAE,Sparse Autoencoder)正是为了解决这个问题而受到关注。SAE 会把原本纠缠在一起的激活向量拆成更多、更稀疏的特征,希望每个特征对应更单一的概念。
flowchart LR
A[模型内部激活向量] --> B[SAE 编码器]
B --> C[稀疏特征 1]
B --> D[稀疏特征 2]
B --> E[稀疏特征 3]
C --> F[自然语言描述]
D --> F
E --> F
SAE 不会自动带来真解释,它只是把“一个神经元混合多个概念”的问题,转化成“多个稀疏特征分别描述”的问题。特征是否真的干净,还要靠后续评估。
概念描述的基本工作流
一个典型的概念描述流程可以拆成四步:
flowchart TD
A[选择目标对象] --> B[收集相关证据]
B --> C[让解释模型生成自然语言描述]
C --> D[用指标或实验评估描述]
D --> E{解释可靠吗?}
E -- 是 --> F[作为机制假设使用]
E -- 否 --> G[修改数据、拆分概念或重新定位对象]
G --> B
目标对象可以是神经元、注意力头、SAE 特征,也可以是一组组件组成的电路。收集证据的方式会随对象变化:
- 神经元:找出让它激活最高的 token 或文本片段。
- 注意力头:观察它从哪些 token 指向哪些 token,以及这个模式是否稳定。
- SAE 特征:找出触发该特征的输入片段,并查看特征激活强度。
- 电路:先定位与任务相关的子图,再解释子图中各组件如何配合。
生成解释时通常会把若干高激活样本交给另一个 LLM,让它归纳共同模式。例如:
你会看到若干文本片段,它们都强烈激活同一个模型内部特征。
请用一句话描述这些文本片段的共同特征。
不要只复述具体词语,要描述抽象模式。
输出可能是:
该特征主要响应法律或合同文本中限制责任、免责和赔偿范围的表达。
这句话只是一个假设。它看起来像解释,但还不能证明该组件真的“负责”法律免责声明。真正重要的是评估。
四类主要对象的描述方法
概念描述不是一种单一算法,而是一组围绕不同内部对象发展的技术路线。
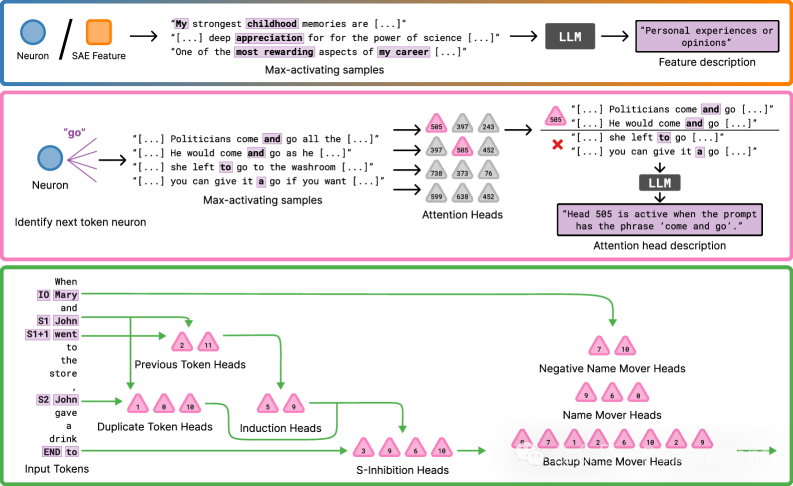
这张流程图对比了不同粒度对象的描述方式。神经元和 SAE 特征通常从高激活样本出发,注意力头更关注 token 之间的连接模式,电路则需要先找出相关子图,再总结整条计算路径的功能。
| 方法类别 | 处理对象 | 核心做法 | 示例描述 |
|---|---|---|---|
| 神经元描述 | MLP 神经元或某层激活维度 | 收集最高激活文本,让 LLM 归纳共同语义 | “检测法律文档中的免责或责任限制条款” |
| 注意力头描述 | Transformer 注意力头 | 分析 query-key 模式、注意力指向和词表投影 | “把当前位置对齐到前文最近出现的同名实体” |
| SAE 特征描述 | 稀疏自编码器学到的特征 | 对稀疏特征复用神经元描述流程 | “与夏季旅游、度假和海滩相关的表达” |
| 电路描述 | 多个头、MLP 和残差流组成的子图 | 定位任务相关子图,解释组件协作方式 | “在 IOI 任务中把代词位置与正确的间接宾语名字关联起来” |
神经元描述:从高激活样本归纳语义
神经元描述最直接。给定一个神经元,先跑一批语料,记录它在哪些 token 上激活最高,再让解释模型总结共同点。
def collect_top_activations(model, dataset, layer, neuron_id, top_k=20):
records = []
for text in dataset:
activations = model.forward_with_activations(text)
neuron_values = activations[layer][:, neuron_id]
for token, value in zip(model.tokenize(text), neuron_values):
records.append((float(value), token, text))
records.sort(reverse=True, key=lambda x: x[0])
return records[:top_k]
拿到高激活样本后,可以把它们组织成提示词:
以下 token 都让同一个神经元强烈激活:
1. token: "liable",上下文: "shall not be liable for..."
2. token: "damages",上下文: "indirect or consequential damages..."
3. token: "warranty",上下文: "without warranty of any kind..."
请描述这个神经元可能检测的概念。
这种方法的优点是简单、可扩展,缺点是容易被表面词频误导。一个神经元对 “damages” 激活,可能不是因为它理解“损害赔偿”,而是因为上下文里有合同格式、法律句式或特定标点结构。
注意力头描述:解释 token 到 token 的关系
注意力头不只是检测某类词,它更像是在建立 token 之间的关系。描述注意力头时,要关注它把当前位置的信息从哪里搬过来。
例如,句子中出现两个名字:
When John and Mary went to the store, John gave a bottle to Mary.
某些注意力头可能在预测最后一个名字时,强烈关注前文的另一个名字。这类头可能参与间接宾语识别(IOI,Indirect Object Identification)任务。
注意力头描述常看这些证据:
| 证据 | 含义 |
|---|---|
| 注意力矩阵 | 当前 token 主要关注哪些历史 token |
| query-key 词表投影 | 哪些词容易触发该头的匹配模式 |
| value-output 影响 | 被关注 token 的信息是否真的传到后续预测 |
| 消融结果 | 移除该头后任务表现是否下降 |
注意力权重本身不是因果解释。一个头关注某个 token,不代表它一定改变了输出;也可能只是“看到了但没用上”。因此注意力头描述最好配合消融或 patching 实验。
SAE 特征描述:把纠缠表示拆开再解释
SAE 的输入通常是模型某层的激活向量,输出是一组稀疏特征。每次输入只激活少数特征,这能让解释更集中。
flowchart LR
A[原模型某层激活] --> B[SAE]
B --> C{稀疏特征}
C --> D[收集触发样本]
D --> E[LLM 生成描述]
E --> F[预测/干预评估]
神经元描述面对的问题是:“这个维度为什么混了这么多概念?”
SAE 特征描述面对的问题变成:“这个稀疏方向是否足够单一?”
SAE 特征更适合处理多语义性,但它也有代价:
| 优点 | 代价 |
|---|---|
| 特征通常比单个神经元更可解释 | 需要额外训练 SAE |
| 可以把一个神经元中的多个概念拆散 | 特征数量很多,评估成本高 |
| 更容易做特征级干预 | SAE 本身可能引入伪特征 |
| 适合构建开放词汇解释库 | 不同 SAE 设置会影响结果 |
电路描述:解释一组组件如何协作
电路描述的目标更接近“机制解释”。它不是问某个单点检测什么,而是问一组组件怎样共同完成任务。
以 IOI 任务为例:
When John and Mary went to the store, John gave a drink to ___
模型应该预测 Mary,因为 Mary 是间接宾语。一个电路解释需要说明:
- 哪些组件识别了句子里的名字;
- 哪些组件区分了主语和间接宾语;
- 哪些组件把正确名字的信息传到预测位置;
- 移除这些组件后,模型是否更难预测正确名字。
电路描述通常不能只靠 LLM 自动归纳,还需要配合人工机制分析、激活 patching、路径 patching 或组件消融。它的成本最高,但因果含义也更强。
评估:自然语言解释怎样才算可靠
概念描述最容易踩的坑是“解释听起来合理”。LLM 很擅长写流畅句子,即使证据不足,也能编出看似合理的概括。评估的作用就是把“好听的故事”筛成“可检验的假设”。
常见评估可以分成五类:
| 评估家族 | 核心问题 | 常见做法 | 风险 |
|---|---|---|---|
| 文本质量评估 | 描述是否清楚、具体、不自相矛盾? | 人类或 LLM 打分 | 流畅不等于真实 |
| 激活预测评估 | 仅凭描述能否预测哪些文本会激活该组件? | 让解释模型给新样本打分,与真实激活相关性比较 | 相关性不代表因果 |
| 检索/分类评估 | 描述能否区分正例和负例? | 用描述检索触发样本,算准确率、召回率或 AUC | 负例设计会影响结果 |
| 因果干预评估 | 操作该组件后,输出变化是否符合描述? | 消融、激活 patching、特征 steering | 实验设置复杂 |
| 对抗与鲁棒性评估 | 描述是否能经受反例和分布外输入? | 构造相似但不应触发的样本 | 成本高,覆盖不完整 |
一个经典自动评估流程是“解释器—模拟器—评分器”:
sequenceDiagram
participant M as 被解释模型
participant E as 解释模型
participant S as 模拟器
participant R as 评分器
M->>E: 提供高激活样本
E-->>S: 生成自然语言描述
S->>S: 根据描述预测新样本激活强度
M->>R: 返回真实激活强度
S->>R: 返回预测激活强度
R-->>E: 计算相关性或排序分数
如果描述是“检测法律免责声明”,那么模拟器看到下面文本时应该给出不同预测:
| 文本 | 理想预测 |
|---|---|
| “The company shall not be liable for incidental damages.” | 高激活 |
| “The beach is crowded during summer vacation.” | 低激活 |
| “Section 12.4 limits the warranty obligations.” | 可能高激活 |
| “Liability is a concept in moral philosophy.” | 不一定高激活 |
这里能看出一个细节:好的评估不能只看关键词。liability 出现在哲学语境中,不一定应该触发“合同免责声明”特征。对抗样本能逼迫解释更加精确。
因果评估为什么越来越重要
相关性评估能快速筛选解释,但解释模型内部机制时,只看相关性远远不够。一个组件与某类文本共同出现,可能有三种情况:
| 情况 | 说明 |
|---|---|
| 真因果 | 该组件参与了模型对该概念的处理 |
| 旁观者 | 该组件也被激活,但输出不依赖它 |
| 间接相关 | 它响应的是另一个共现因素,比如标点、格式、位置 |
因果干预要做的是改变组件状态,观察输出是否按描述变化。
flowchart LR
A[输入文本] --> B[正常前向传播]
B --> C[记录输出]
A --> D[修改目标组件]
D --> E[再次前向传播]
E --> F[记录新输出]
C --> G[比较变化]
F --> G
G --> H{变化是否符合描述?}
常见干预方式有三种:
| 方法 | 做法 | 适合验证 |
|---|---|---|
| 消融 | 把目标神经元、头或特征置零 | 组件是否必要 |
| 激活 patching | 把一个输入中的激活替换成另一个输入中的激活 | 组件是否携带特定信息 |
| 特征 steering | 增强或减弱某个 SAE 特征 | 特征是否能定向影响输出 |
例如,一个 SAE 特征被描述为“与拒绝回答危险请求有关”。如果增强该特征后,模型更倾向于拒绝危险请求;减弱该特征后,拒绝倾向下降,这比单纯看到高激活样本更有说服力。当然,这仍然需要控制混杂因素,不能只看单个案例。
多概念描述:一个特征不一定只有一句解释
早期概念描述常假设一个对象对应一句话解释。但很多对象确实有多个触发模式,即使用 SAE 后也不一定完全单义。
更合理的做法是允许一个对象拥有多条描述:
特征 A:
1. 响应合同中的责任限制和免责条款。
2. 响应正式文档中的章节编号和条款引用。
3. 响应法律语境中的 warranty、damages、liable 等词。
这种多描述方式比强行写一句大而全的解释更稳妥。它还能帮助研究者发现:一个特征到底是“法律免责声明”特征,还是“正式法律文档格式”特征。
PRISM 一类框架的思路就是把单一描述扩展成多概念描述,让解释结果更接近模型真实表示的混合结构。
实际使用时的判断标准
概念描述适合做机制探索,但不适合直接当成最终结论。使用时可以按下面标准检查:
| 检查项 | 好解释 | 弱解释 |
|---|---|---|
| 具体性 | 能指出概念、语境和边界 | 只写“与文本含义有关” |
| 可预测性 | 能预测新样本是否触发 | 只解释已见样本 |
| 可反驳性 | 能构造反例检验 | 怎么说都对 |
| 因果性 | 干预后输出按预期变化 | 只与激活相关 |
| 稳定性 | 换数据、换负例仍成立 | 对提示词或样本选择很敏感 |
一个比较可靠的解释通常长这样:
该 SAE 特征主要响应合同或法律文档中限制责任、排除间接损害赔偿、限定保证范围的表达。
它不只是响应 liability 这个词;在非法律语境中出现 liability 时,激活通常较弱。
增强该特征会提高模型生成免责条款相关续写的概率。
这段解释包含三个要素:概念、边界、因果效应。只有一句“检测法律文本”就太粗了。
概念描述的局限
概念描述能让内部机制更容易讨论,但它仍然有明显限制。
LLM 生成的解释可能过度拟合样本
如果只给解释模型看最高激活样本,它可能抓住偶然共现的词,而不是底层机制。解决方法是加入中等激活样本、低激活样本和对抗负例。
自然语言不一定能完整表达向量空间概念
模型内部特征可能对应一种连续方向,而自然语言描述是离散的。某些特征可能无法被一句人类语言准确概括,只能用多个近似描述。
自动评分容易奖励“看起来对”的解释
LLM 既能生成解释,也能当评委,但这会带来偏差。更稳妥的做法是结合真实激活、干预实验和人工审核。
电路级解释成本很高
单个神经元或 SAE 特征可以批量描述,电路解释却需要定位组件、验证路径、构造任务和做干预。它不容易大规模自动化,但对理解关键能力更有价值。
一套可落地的分析流程
如果要在自己的模型分析中使用概念描述,可以按这个顺序推进:
flowchart TD
A[确定任务或能力] --> B[收集输入样本]
B --> C[定位相关层和组件]
C --> D[训练或加载 SAE]
D --> E[收集高激活/低激活样本]
E --> F[生成候选描述]
F --> G[用新样本做预测评估]
G --> H[构造反例]
H --> I[做消融或 patching]
I --> J[保留可靠描述]
对应的最低配置可以是:
| 步骤 | 建议 |
|---|---|
| 数据 | 至少包含正例、负例和相似反例 |
| 解释对象 | 先从 SAE 特征或明确任务相关的注意力头开始 |
| 描述生成 | 要求解释模型给出概念、边界和不应触发的样本 |
| 自动评估 | 用未见样本比较预测激活与真实激活 |
| 因果验证 | 对少量高价值特征做消融或 patching |
| 记录结果 | 保存样本、提示词、解释、分数和干预结果 |
概念描述最大的价值,是把模型内部的未知结构转化成可读、可讨论、可检验的假设。它不能保证每句解释都是真的,但能把“黑盒里可能发生了什么”拆成一组可以逐步验证的问题。真正可靠的解释,需要自然语言描述、激活证据、反例测试和因果干预共同支撑。