“单表别超过 2000 万行”不是 MySQL 的限制,也不是 InnoDB 到了这个数量就不能写入。它更像一个工程经验:在默认 16KB 数据页、InnoDB 存储引擎、B+树索引、普通业务表结构这些条件下,单表达到两千万级别后,B+树有可能从 3 层增长到 4 层,查询路径会多访问一层索引页。
多一层不一定立刻变慢到不可接受,但在高并发、二级索引回表、范围查询、深分页、缓存命中率下降等场景里,这个额外成本会被放大。
讨论这个问题时,先固定几个前提:
- 存储引擎:InnoDB;
- 页大小:默认 16KB;
- 索引结构:B+树;
- 主键:常见的整数自增主键;
- 表结构:普通业务表,列数量和单行大小没有特别夸张;
- 查询方式:主要依赖索引,而不是长期全表扫描。
可以用一张简单的用户表作为例子:
CREATE TABLE `user` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int NOT NULL DEFAULT 0 COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这张表里有一个主键索引 PRIMARY KEY(id),还有一个普通二级索引 idx_age(age)。理解这两类索引,就能理解 MySQL 为什么会和“页”“树高”“磁盘 I/O”绑在一起。
InnoDB 如何把表数据放到磁盘上
InnoDB 不是一行一行直接散落在磁盘上的。它使用页式存储,默认把数据文件切成一个个 16KB 的页,读写磁盘时也通常以页为单位。
对于独立表空间模式,一张 InnoDB 表通常会有自己的 .ibd 文件。表里的行记录、索引页、页头页尾等信息都在这个表空间文件里。
数据页和表空间的关系可以理解成这样:
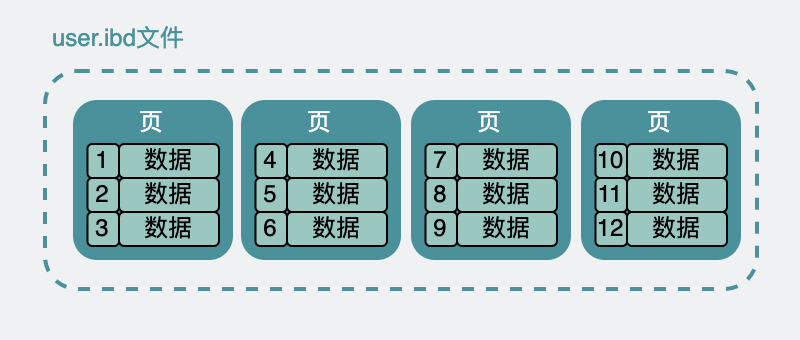
图里最重要的是两点:.ibd 文件不是一整块连续的“表格”,而是由很多页组成;每个页都有自己的页号,InnoDB 通过页号定位具体的数据页。
一个页内部也不只存业务数据。16KB 空间里还要放页头、页目录、校验信息、前后页指针等内容。
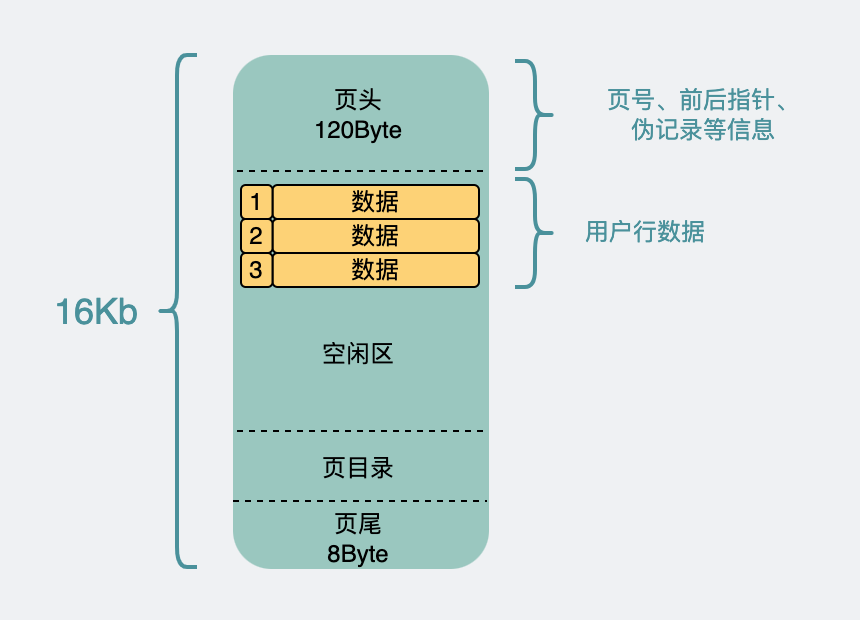
一个简化后的 InnoDB 数据页可以拆成这些部分:
| 区域 | 作用 |
|---|---|
| File Header | 记录页号、前后页指针、校验信息等文件层面的元数据 |
| Page Header | 记录页内状态,例如记录数量、空闲空间位置等 |
| Infimum / Supremum | 页内的最小和最大虚拟记录,辅助维护有序结构 |
| User Records | 真正存放用户行记录的区域 |
| Free Space | 页内尚未使用的空间 |
| Page Directory | 页目录,用于加速页内查找 |
| File Trailer | 页尾校验信息,用于检查页是否完整 |
页内的记录不是每次都从头扫到尾。InnoDB 会借助页目录做类似二分查找的定位,把页内查找成本从线性扫描降低到更小的范围内。
不过页内查找只是局部优化。如果一张表有几千万行,靠逐页扫描仍然不现实,所以还需要索引。
B+树索引如何组织数据页
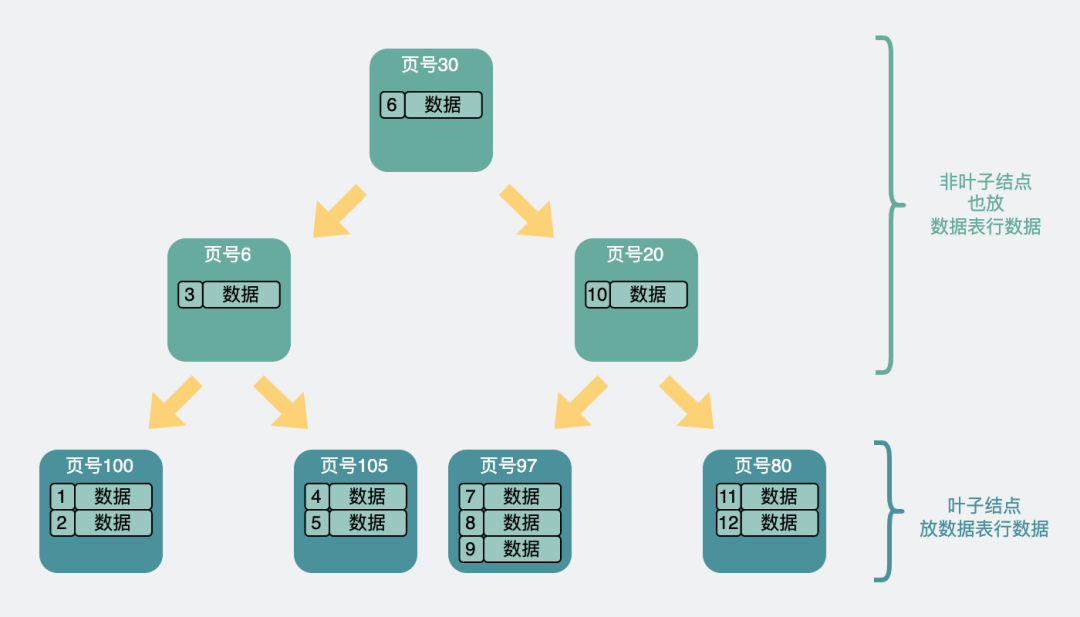
InnoDB 的主键索引是一棵 B+树。它有一个很关键的特征:
- 非叶子节点只存索引键和子页指针;
- 叶子节点存真正的行数据;
- 叶子节点之间通过双向链表连接,方便范围扫描。
聚簇索引结构可以画成这样:
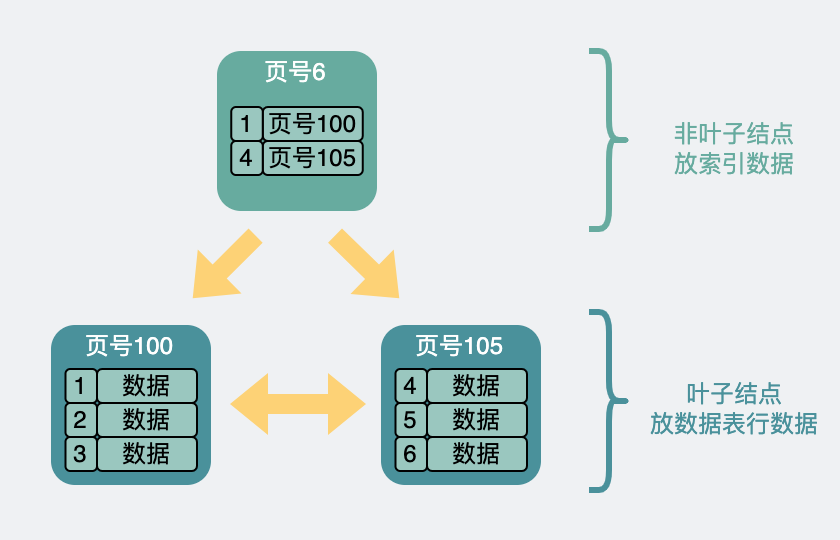
最底层是叶子节点,page level = 0,这里保存完整行记录。上层都是非叶子节点,只保存主键值和下一层页号,相当于目录页。
用 mermaid 表示更直观:
flowchart TD
R[根页<br/>主键范围 + 子页指针] --> M1[中间页 A<br/>主键范围 + 子页指针]
R --> M2[中间页 B<br/>主键范围 + 子页指针]
M1 --> L1[叶子页 1<br/>完整行记录]
M1 --> L2[叶子页 2<br/>完整行记录]
M2 --> L3[叶子页 3<br/>完整行记录]
M2 --> L4[叶子页 4<br/>完整行记录]
L1 <--> L2
L2 <--> L3
L3 <--> L4
这里有两个概念容易混淆。
聚簇索引
InnoDB 表的数据本身就是按主键索引组织的。也就是说,主键 B+树的叶子节点里放的是完整行数据。
对于刚才的 user 表,主键索引的叶子节点里会存:
id + name + age + 事务ID + 回滚指针 + 其他行格式信息
所以通过主键查询一行数据时,只需要沿着主键 B+树走到叶子节点,就能拿到完整行。
二级索引
二级索引不是直接存完整行。比如 idx_age(age) 的叶子节点,通常存的是:
age + 主键id
如果执行:
SELECT * FROM user WHERE age = 18;
MySQL 先走 idx_age 找到满足条件的主键 id,然后再拿这些 id 回到主键索引里查完整行。这个过程叫回表。
sequenceDiagram
participant SQL as SQL执行器
participant S as 二级索引 idx_age
participant P as 主键索引 PRIMARY
participant R as 结果集
SQL->>S: 根据 age = 18 查二级索引
S-->>SQL: 返回匹配的主键 id
SQL->>P: 根据主键 id 查询完整行
P-->>SQL: 返回整行数据
SQL-->>R: 输出结果
如果查询列都在二级索引里,例如:
SELECT id, age FROM user WHERE age = 18;
二级索引已经包含 age 和 id,就不需要回表,这叫覆盖索引。
一次主键查询会访问多少页
假设执行:
SELECT * FROM user WHERE id = 5;
InnoDB 会从 B+树根页开始,根据根页里的主键范围找到下一层页,再继续向下定位,直到叶子页。
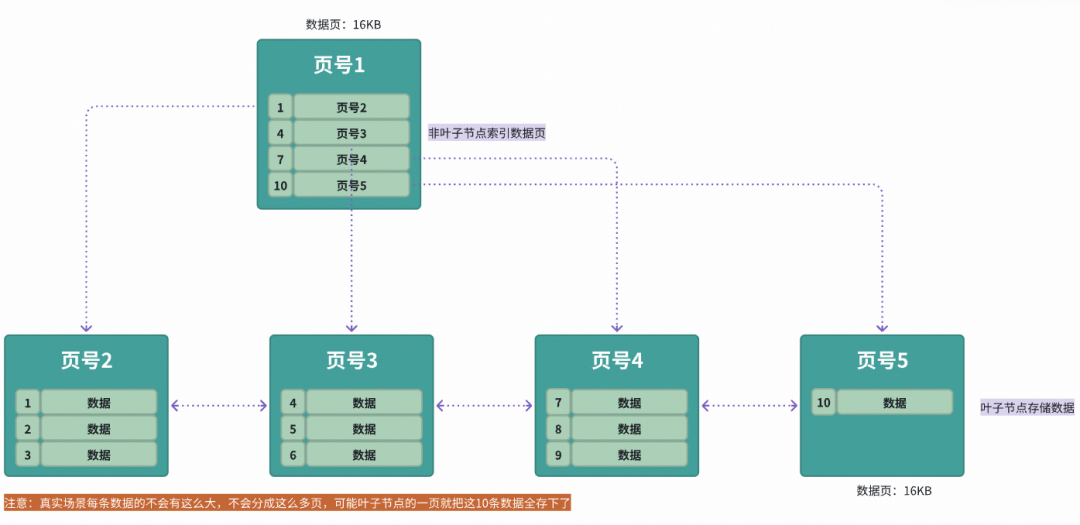
图里可以看到,非叶子节点里的记录本质上是“主键边界 + 页号”。如果某个上层页记录了这些范围:
| 子页 | 最小主键 |
|---|---|
| 页2 | 1 |
| 页3 | 4 |
| 页4 | 7 |
| 页5 | 10 |
那么 id = 5 落在 [4, 7) 这个范围里,InnoDB 就会进入页3,再在页3内部查找具体行。
主键查询流程可以概括成:
flowchart TD
A[执行 SELECT * FROM user WHERE id = 5] --> B[访问根页]
B --> C{根页是否在 Buffer Pool 中}
C -->|是| D[直接读取根页]
C -->|否| E[从磁盘加载根页到 Buffer Pool]
E --> D
D --> F[根据主键范围定位下一层页]
F --> G[访问中间页]
G --> H[定位叶子页]
H --> I[访问叶子页]
I --> J[页内通过页目录和记录链定位 id=5]
J --> K[返回完整行]
如果 B+树高度是 3,并且相关页都不在 Buffer Pool 中,理论上最多需要读取 3 个页:根页、中间页、叶子页。
实际运行时通常没这么悲观。根页和热点中间页很容易留在 Buffer Pool 中,真正发生磁盘 I/O 的可能只有叶子页。不过从复杂度上看,树高越高,最坏路径越长;当缓存命中率下降时,树高带来的差距会更明显。
2000 万行是怎么估算出来的
B+树能承载多少行,主要看三个变量:
| 变量 | 含义 |
|---|---|
| x | 非叶子节点的扇出,也就是一个非叶子页能指向多少个子页 |
| y | 一个叶子页能容纳多少行记录 |
| z | B+树高度 |
如果只估算聚簇索引的行数容量,可以用这个公式:
最大行数 ≈ x ^ (z - 1) × y
为什么是 z - 1?因为只有最后一层叶子页存行数据,前面的层级都负责把查询路由到下一层。每增加一层非叶子节点,能指向的叶子页数量都会乘以一次扇出。
非叶子节点扇出 x
非叶子节点里主要存两类信息:
索引键 + 子页页号
如果主键是 BIGINT,主键占 8 字节;页号可以粗略按 4 字节估算。真实记录还会有记录头、槽目录等额外开销,所以不能简单认为一条非叶子记录只有 12 字节。
为了便于估算,可以按下面方式粗算:
页大小:16KB
扣除页头、页尾、页目录等开销后,可用空间约 15KB
每条非叶子记录粗略按 12B 左右估算
扇出 x ≈ 15KB / 12B ≈ 1280
1280 不是精确值,只是一个便于理解的量级。真实值会受主键类型、记录格式、页内碎片、填充率等因素影响。
关键点在于:B+树非叶子节点不存整行数据,所以一个页可以指向非常多的子页。这就是 B+树“矮胖”的原因。
叶子节点单页行数 y
叶子节点存完整行数据。单页能放多少行,取决于单行大小。
如果一行数据大约 1KB,扣除页开销后,一个页大概能放:
y ≈ 15KB / 1KB = 15 行
如果一行只有 250B,一个页大概能放:
y ≈ 15KB / 250B ≈ 60 行
同样是 16KB 页,行越窄,叶子页能放的记录越多,整棵 B+树能承载的行数也越多。
三层 B+树为什么接近 2000 万
代入常见估算值:
x = 1280
y = 15
不同树高的容量大概是:
| B+树高度 z | 估算公式 | 可承载行数 |
|---|---|---|
| 2 | 1280 ^ 1 × 15 | 约 1.9 万 |
| 3 | 1280 ^ 2 × 15 | 约 2457 万 |
| 4 | 1280 ^ 3 × 15 | 约 314 亿 |
这就是两千万级别经验值的来源:当单行约 1KB、主键较短、页大小 16KB 时,三层 B+树大概能放两千多万行。继续增长后,B+树可能变成 4 层,主键查询路径就多一层。
但这个数不是边界线。换一种行大小,结果会完全不同。
| 单行大小 | 叶子页行数 y | 三层 B+树估算容量 |
|---|---|---|
| 2KB | 约 7 行 | 约 1146 万 |
| 1KB | 约 15 行 | 约 2457 万 |
| 500B | 约 30 行 | 约 4915 万 |
| 250B | 约 60 行 | 约 9830 万 |
所以,单表 1 亿行不一定慢。如果表很窄、查询走主键或覆盖索引、热点数据能留在 Buffer Pool 中,三层 B+树仍然可能支撑很大的数据量。
反过来,单表 500 万行也可能慢。如果一行很宽,包含大字段,二级索引很多,查询又经常回表或范围扫描,即使没到 2000 万,也可能出现明显压力。
B+树为什么比 B树更适合 InnoDB 索引
B树和 B+树名字很像,但存数据的位置不同。
- B树:非叶子节点和叶子节点都可以存数据;
- B+树:只有叶子节点存完整数据,非叶子节点只存索引键和指针。
B树结构可以理解成这样:
如果非叶子节点也存完整行,那么一个页能放的索引项就会明显变少。假设一行约 1KB,一个 16KB 页扣除开销后只能放十几条记录。扇出变小后,树就会变高。
对比一下两种结构:
| 对比项 | B树 | B+树 |
|---|---|---|
| 非叶子节点内容 | 索引键、指针、行数据 | 索引键、指针 |
| 单个非叶子页扇出 | 较小 | 很大 |
| 树高 | 更容易变高 | 更容易保持较低高度 |
| 范围查询 | 需要在树中多处遍历 | 叶子节点双向链表顺序扫描 |
| 磁盘 I/O | 同等数据量下更可能访问更多层 | 同等数据量下访问路径更短 |
| 是否适合数据库索引 | 可以用,但不如 B+树贴合磁盘页模型 | 更适合 InnoDB 这种页式存储 |
B+树把非叶子节点做得很“轻”,一个页能容纳大量目录项,因此树高可以压得很低。对磁盘型数据库来说,减少访问页数就是减少潜在磁盘 I/O。
范围查询也是 B+树的优势。比如:
SELECT * FROM user WHERE id BETWEEN 1000 AND 2000;
InnoDB 找到第一个满足条件的叶子页后,可以沿着叶子页链表继续向后扫,而不需要反复回到树的上层节点。
超过 2000 万行一定要分表吗
不一定。
是否要分表,不能只看行数,还要看下面这些指标:
| 判断项 | 需要关注什么 |
|---|---|
| 查询模式 | 主键点查、覆盖索引查询通常压力较小;大范围扫描、深分页、频繁回表压力更大 |
| 单行大小 | 行越宽,叶子页能放的记录越少,树高越容易增加 |
| Buffer Pool 命中率 | 命中率高时,树高增加的影响会被缓存削弱 |
| 写入模式 | 自增主键写入更顺序;随机主键容易导致页分裂和碎片 |
| 二级索引数量 | 索引越多,写入时维护成本越高,占用空间也越大 |
| 历史数据比例 | 很少访问的冷数据继续留在热表里,会拖累缓存效率 |
| SQL 质量 | 没有合适索引、排序临时表、回表过多,比单纯行数更容易造成慢查询 |
更合理的做法是把 2000 万当作预警值,而不是硬规则。
常见处理方式有几类:
| 方案 | 适合场景 | 代价 |
|---|---|---|
| 控制单行大小 | 热表包含大字段、JSON、TEXT、BLOB | 需要拆表或改业务读取逻辑 |
| 增加覆盖索引 | 查询字段比较固定,回表成本高 | 索引占用更多磁盘,写入成本增加 |
| 冷热分离 | 历史数据访问少,热数据集中在近期 | 需要处理跨冷热数据查询 |
| 归档历史数据 | 订单、日志、流水等天然按时间沉淀 | 需要归档任务和恢复方案 |
| 分区表 | 数据按时间或范围清理,单表逻辑仍想保留 | 分区键设计不当时收益有限 |
| 分库分表 | 单机容量、写入、索引维护都接近瓶颈 | 查询、事务、扩容、运维复杂度上升 |
如果只是主键查询慢,先检查索引、SQL、缓存命中率和行大小;如果写入也开始吃力,索引维护、页分裂、磁盘空间、复制延迟就都要纳入考虑。
为什么 InnoDB 默认页大小是 16KB
InnoDB 的页大小不是只能是 16KB,但 16KB 是默认值。它在数据库实例初始化时由 innodb_page_size 决定,常见取值包括 4KB、8KB、16KB、32KB、64KB。创建实例后通常不能随意修改。
页大小影响两个方向:
- 页越大,一个页能放更多记录或目录项,B+树可能更矮;
- 页越大,每次读取的最小单位也越大,不需要的数据也会被一起读入内存。
这个权衡可以这样看:
| 页大小 | 优点 | 缺点 |
|---|---|---|
| 较小页,例如 4KB、8KB | 单次读放大较小,更适合随机小读 | 非叶子节点扇出较低,树可能更高 |
| 默认 16KB | 在树高、I/O 粒度、内存利用之间比较均衡 | 不是所有业务的最优值 |
| 较大页,例如 32KB、64KB | 单页可容纳更多记录,范围扫描可能更友好 | 随机读放大更明显,Buffer Pool 容易装入更多无关数据 |
数据库默认值通常不是为某一种业务做到极致,而是在多数 OLTP(联机事务处理)场景下取得比较稳定的表现。对绝大多数业务系统来说,16KB 不需要调整;真正需要改页大小的场景,一般会结合压测、磁盘类型、数据模型和访问模式一起验证。
字符串列如何建立索引
字符串也可以建立 B+树索引。它的排序不是简单按“看起来的字母顺序”,而是由字符集和排序规则决定。
例如:
CREATE TABLE product (
id bigint unsigned NOT NULL AUTO_INCREMENT,
name varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name (name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
idx_name(name) 会按 name 的排序规则组织 B+树。
对于长字符串,直接给整列建索引可能会带来两个问题:
- 索引项变大,非叶子节点扇出降低;
- 索引文件变大,Buffer Pool 能缓存的有效索引页变少。
可以考虑前缀索引:
CREATE INDEX idx_name_prefix ON product(name(20));
前缀长度不能随便拍脑袋。可以用选择性估算:
SELECT
COUNT(DISTINCT name) / COUNT(*) AS full_selectivity,
COUNT(DISTINCT LEFT(name, 10)) / COUNT(*) AS prefix_10_selectivity,
COUNT(DISTINCT LEFT(name, 20)) / COUNT(*) AS prefix_20_selectivity
FROM product;
如果 LEFT(name, 20) 的选择性已经接近完整 name,前缀索引就可能够用。
不过前缀索引也有代价:它不能完整覆盖所有基于原字符串的排序和查询场景。比如某些 ORDER BY name 可能无法完全依赖前缀索引完成排序。
中文字符串索引要注意排序规则
中文字符串在 MySQL 里同样可以建立 B+树索引,但排序结果取决于 collation(排序规则)。
例如:
CREATE TABLE user_profile (
id bigint unsigned NOT NULL AUTO_INCREMENT,
name varchar(100) NOT NULL,
PRIMARY KEY (id),
KEY idx_name (name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
这里的 utf8mb4_0900_ai_ci 会按 Unicode Collation Algorithm 的规则比较字符串,不等于“按拼音排序”。
如果业务确实要求按拼音排序,更常见的做法是额外存一列拼音字段:
ALTER TABLE user_profile
ADD COLUMN name_pinyin varchar(200) NOT NULL DEFAULT '',
ADD KEY idx_name_pinyin (name_pinyin);
查询时按拼音字段排序:
SELECT id, name
FROM user_profile
ORDER BY name_pinyin
LIMIT 20;
也可以使用生成列,但拼音转换通常需要应用层或专门函数支持:
ALTER TABLE user_profile
ADD COLUMN name_sort_key varchar(200) GENERATED ALWAYS AS (name) STORED,
ADD KEY idx_name_sort_key (name_sort_key);
实际设计时要明确需求:是按 Unicode 规则排序,还是按拼音排序,还是只需要等值查询。不同目标对应的索引设计并不一样。
索引字段长度有哪些限制
索引长度受数据类型、字符集、排序规则、存储引擎和 MySQL 版本影响。
在现代 MySQL 5.7 / 8.0 的 InnoDB 中,常见 16KB 页下,单个索引键前缀最大长度通常是 3072 字节。更老的版本或旧行格式下,可能会遇到 767 字节限制。
字符串列尤其要注意字节数,而不是字符数。utf8mb4 下一个字符最多占 4 字节:
varchar(255) 在 utf8mb4 下最多占 255 × 4 = 1020 字节
如果建联合索引,多个字段的字节数会一起计算:
CREATE INDEX idx_a_b ON t(a, b);
索引键长度大致要考虑:
a 的最大字节数 + b 的最大字节数 + 额外开销
遇到长字符串索引,可以考虑几种方式:
| 方式 | 示例 | 适合场景 |
|---|---|---|
| 前缀索引 | KEY idx_name (name(20)) | 前缀区分度足够高 |
| 哈希辅助列 | 存储 MD5 或其他哈希值 | 长字段等值查询 |
| 拆分字段 | 把大字段拆到扩展表 | 热表需要保持较窄 |
| 全文索引 | FULLTEXT KEY | 文本搜索,而不是普通等值或范围查询 |
哈希辅助列常用于超长字符串等值查询,例如:
ALTER TABLE document
ADD COLUMN content_hash binary(16) NOT NULL,
ADD KEY idx_content_hash (content_hash);
查询时先用哈希定位,再用原字段做最终确认,避免哈希碰撞带来的误判:
SELECT *
FROM document
WHERE content_hash = UNHEX(MD5('some long content'))
AND content = 'some long content';
设计大表时更应该盯住哪些点
单表行数只是一个结果指标。真正影响 InnoDB 查询成本的,是页、索引和访问路径。
几个实践原则更有用:
-
主键尽量短且稳定
BIGINT自增主键比很长的字符串主键更适合作为聚簇索引。主键会出现在所有二级索引叶子节点里,主键越大,二级索引也越大。 -
热表不要塞大字段
TEXT、BLOB、大 JSON 会增加行大小,降低叶子页行数。热查询不需要的大字段可以拆到扩展表。 -
二级索引要围绕查询设计
不要只看WHERE条件,还要看ORDER BY、LIMIT、返回列和回表成本。 -
能覆盖就减少回表
高频查询如果只需要少量字段,可以通过联合索引覆盖,减少一次主键索引查找。 -
历史数据要有去处
订单、流水、日志这类表很容易自然增长。热数据和冷数据长期混在一起,会降低缓存命中率,也会拖慢备份、DDL 和统计信息维护。 -
不要等到极限再拆
分库分表、归档、冷热分离都需要改查询链路和运维流程。等到单表已经拖慢核心链路时再改,风险会高很多。
2000 万行的本质,是对 InnoDB B+树高度的一个经验估算:在 16KB 页和常见行大小下,三层 B+树大约能覆盖两千万级别数据。它不是数据库红线,而是提醒我们开始关注树高、行宽、索引大小、缓存命中率和数据生命周期。